Text-Embeddings & Vektorsuche: Retrieval in RAG-Systemen optimieren
Laura Weber
Laura Weber
Consultant
Laura Weber ist Consultant mit dem Schwerpunkt Data Science. Ihre schnelle Auffassungsgabe erlaubte es ihr, ihre Fähigkeiten in verschiedenen Rollen und in verschiedenen Branchen einzusetzen. Von der Datenanalyse, über Data Engineering, Datenmodellierung, Reporting bis hin zur Stakeholder Kommunikation und Präsentation beherrscht sie ein breites Spektrum an technischen und methodischen Kompetenzen.
RAG implementiert – und jetzt? Embeddings sind das Fundament von RAG-Systemen. In diesem Blogbeitrag zeigen wir anhand eines CV-Matching Use Cases, wie Du mit der Analyse von Text-Embeddings die Vektorsuche effektiver und das Retrieval in GenAI Projekten qualitativer und fairer gestalten kannst.
Inhaltsverzeichnis
RAG-Anwendungen stützen sich auf Text-Embeddings, die die semantische Bedeutung von Texten repräsentieren. Wir zeigen Dir, wie Text-Embeddings auf unterschiedliche Weise analysiert werden können, und wie Du mehr Verständnis für ihre Inhalte erlangst. Außerdem: Wie Du das Retrieval von Dokumenten in Deiner RAG-Anwendung optimierst.
Retrieval optimieren: Das nächste Level für RAG-Systeme
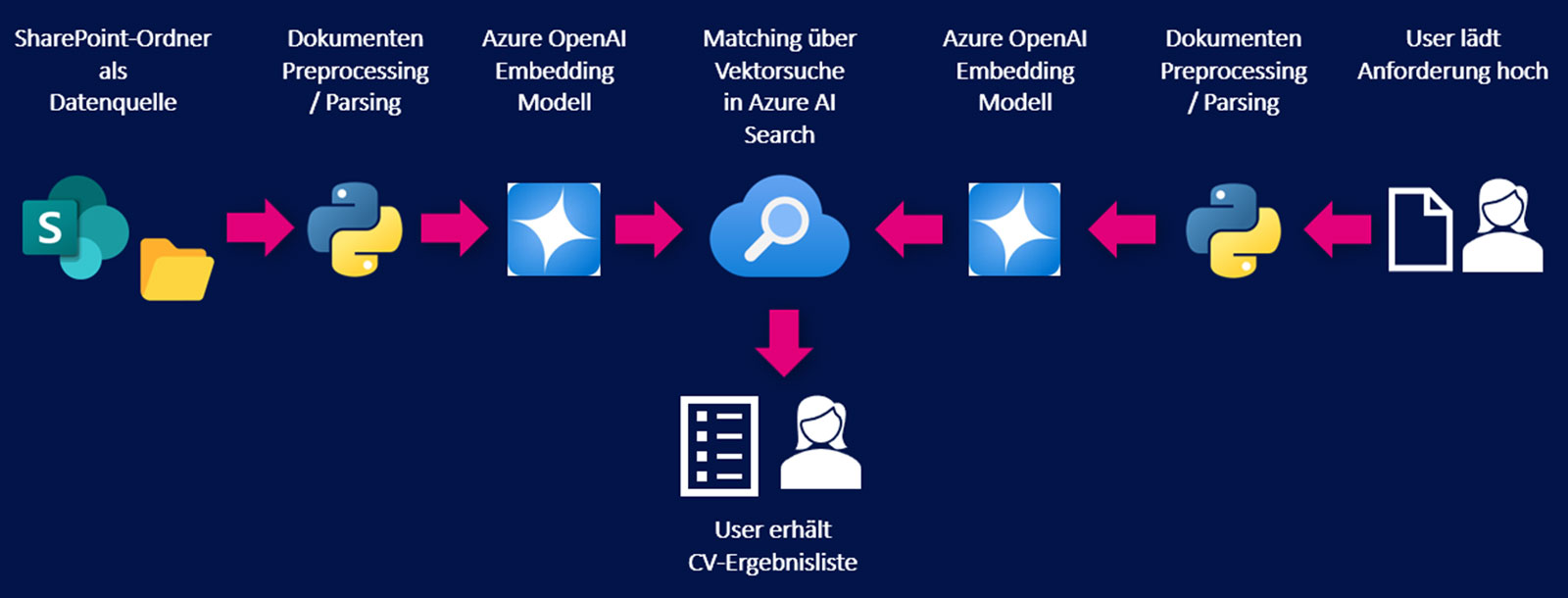
RAG – Retrieval Augmented Generation – wird heutzutage in vielen GenAI-Projekten umgesetzt. Eine RAG-Anwendung erweitert eine Nutzerfrage um relevante Informationen aus zusätzlichen Quellen – etwa aus internen Dokumenten. Dazu werden per Ähnlichkeitssuche relevante Textstellen gefunden und als Kontext zur eigentlichen Abfrage „mitgegeben“. So kann das LLM diese Informationen dann direkt für die Antwortgenerierung nutzen und muss sich nicht nur auf sein vortrainiertes Wissen verlassen. Durch integrierte Services wie Azure OpenAI und Azure AI Search lässt sich eine RAG-Anwendung vergleichsweise schnell aufsetzen.
Embeddings verstehen statt Blackbox akzeptieren
Die Algorithmik der Ähnlichkeitssuche – also das „R“ in RAG – ist jedoch anspruchsvoll und stellt für die meisten Anwender:innen eine Blackbox dar. Warum ein Dokument als „relevant“ für das Retrieval eingestuft wird, ist schwer zu bewerten. Warum? Weil das Matching nicht zwischen den Texten und ihren Wörtern selbst, sondern zwischen ihren Text-Embeddings erfolgt.
Was genau ist ein Embedding?
Ein Embedding ist die numerische Repräsentation (Vektor) eines Textes und wird von Embedding-Modellen berechnet. Dieser Vektor erfasst die semantische Bedeutung des Textes, die häufig in hunderten Dimensionen kodiert ist. Die einzelnen Dimensionen sind allerdings inhaltlich nicht zu interpretieren. (Siehe auch Text Embeddings, Classification, and Semantic Search | Towards Data Science)
Mehr Qualität, Fairness und Effizienz durch Embedding-Analysen
Gerade weil Embeddings das Fundament von RAG bilden, lohnt die analytische Vertiefung: Wer Retrieval versteht und gezielt optimiert, steigert Antwortqualität, Relevanz und Fairness. Außerdem sinken dadurch die Kosten, da weniger Tokens verbraucht und weniger Re-Prompts benötigt werden. Zugleich verringern sich Risiken wie Fehlentscheidungen und Compliance-Verstöße. Die im Folgenden beschriebenen Schritte sind nicht nur Analysen, sondern praktische Hebel – übertragbar auf viele Anwendungsfälle wie interne Wissenssuche, Support-Ticket-Retrieval, Vertragsrecherche oder Produktdokumentation.
Use Case: Unterstütztes Staffing durch Matching von Jobbeschreibung und CVs
Ein Beispiel aus dem Staffing-Alltag: Um herauszufinden, wer aus unserem Berater:innen-Team am besten auf neue Jobs passt, schauen wir uns das Matching zwischen Jobbeschreibungen und CVs an. Und zwar konkret in den Domänen Cloud/Data-Plattform, Data Management und Data Analytics/AI. Ziel des Use Cases ist es, genau die CVs aus einem Pool an Lebensläufen auszugeben, die anhand von Projekten, Erfahrungen, Technologien und Skills am besten für den ausgeschriebenen Job geeignet sind. Hierfür wurde RAG mit Vektorsuche (Cosine Similarity) über Azure OpenAI und Azure AI Search implementiert. Als Datengrundlage dienen knapp 120 CVs mit unterschiedlichen Formatierungen. Die Lebensläufe stammen sowohl von b.telligent Mitarbeitenden als auch von externen Freelancern und weiteren Beratungen.
RAG-Architektur für dasMatching von Jobbeschreibung und CVs
Die Ergebnisse der Ähnlichkeitssuche aus der initialen RAG-Implementierung sind ausbaufähig – die Top-Treffer sind nicht ideal, während bessere CVs weiter unten im Ranking platziert wurden. Welche Inhalte durch die Embeddings ganz konkret Einfluss auf eine hohe Ähnlichkeitsbewertung – den Similarity Score – nehmen, ist unklar. Entsprechend kann das Matching an diesem Punkt nicht gesteuert werden.
Um die Einflussfaktoren des Matchings aufzudecken, bieten sich zwei Ansätze an:
Hypothesen darüber formulieren, was in den Embeddings abgebildet sein könnte, und gezielt validieren
Explorative Analyse der Embeddings durch Visualisierung zur Identifikation von Mustern
Hypothesen prüfen: Welche Faktoren beeinflussen das Matching?
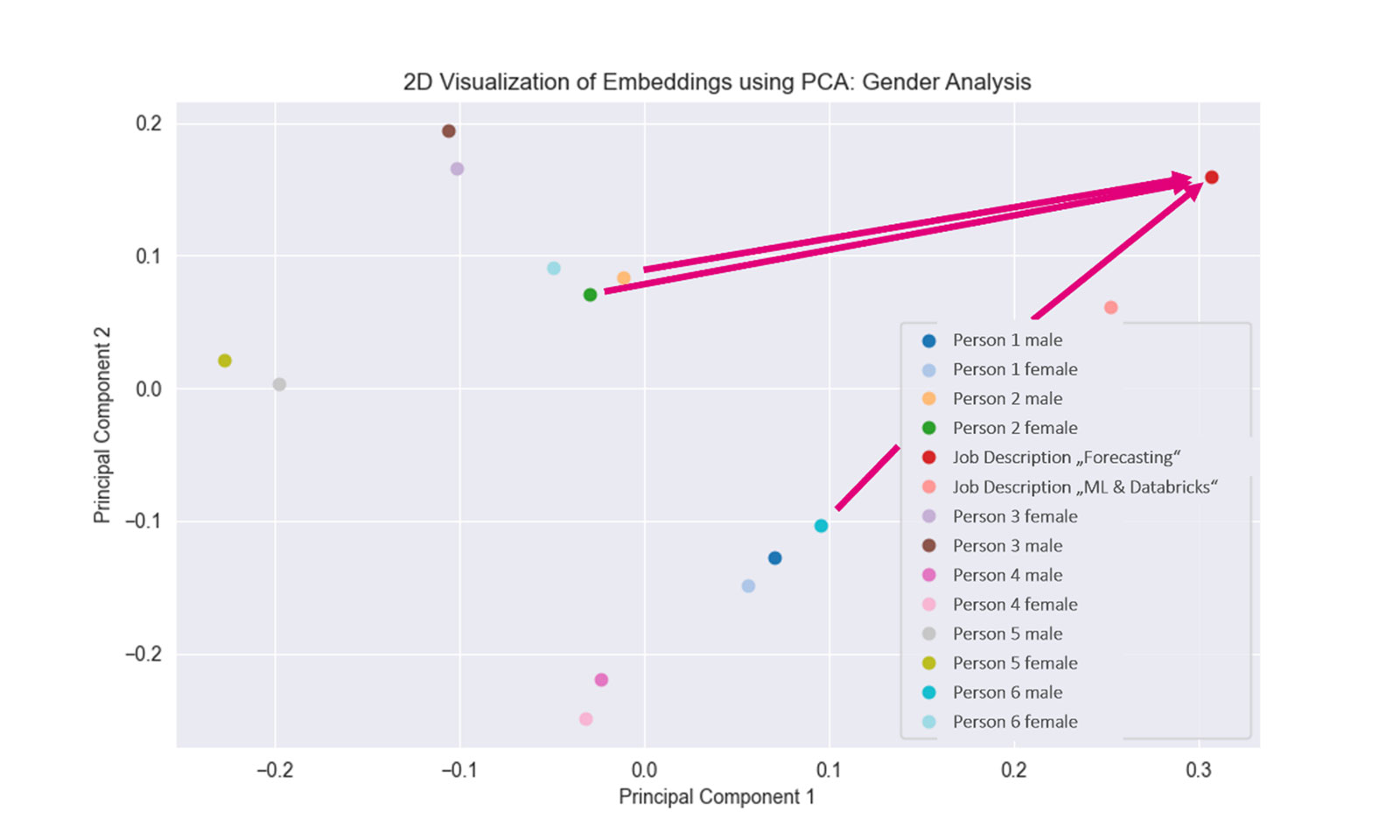
AI Use Cases sind nicht frei von kontextspezifischen Einflüssen, die sich auf Embeddings – und damit im Text-Matching – auswirken können. In unserem Beispiel kann beispielsweise das Geschlecht über Namen/Pronomen im Text im Embedding kodiert sein und das Ranking beeinflussen.
Zur Überprüfung wurden gezielte Textmodifikationen vorgenommen: gleiche CV-Inhalte mit männlichen beziehungsweise weiblichen Vornamen/Pronomen. Beide Varianten wurden als Vektoren eingebettet und miteinander verglichen. In diesem Experiment konnte keine spezifische Dimension identifiziert werden, die die Information „Geschlecht“ isoliert trägt. Stattdessen unterschieden sich fast alle Dimensionen zwischen den beiden Varianten. Das bedeutet, das Embedding-Modell speichert Informationen nicht in gezielten Dimensionen, sondern über alle Dimensionen hinweg.
Fairness im Fokus – wie Bias das Matching verzerren kann
Die Hypothese, dass die „männliche“ Version pauschal einen höheren Similarity-Score (Ähnlichkeit zur Jobbeschreibung) erzielt, hat sich nicht bestätigt. Fakt bleibt: Die Embeddings zwischen männlichem und weiblichem CV unterscheiden sich, was wiederum das Matching beeinflussen kann.
Konsequenz: Anonymisierung und geschlechterneutrale Formulierungen im CV und in der Jobbeschreibung erhöhen Fairness und senken Bias-Risiken.
Analog gilt: Auch Alter, Ethnizität, politische, kulturelle und andere Use-Case-spezifische Marker können Embeddings beeinflussen und die semantische Suche unbeabsichtigt verzerren – eine wichtige Erkenntnis für die Entwicklung einer fairen und verantwortungsvollen KI-Anwendung.
Dieser Analyseansatz ist auch auf andere Domänen übertragbar: In Support-Daten könnten beispielsweise Kundennamen, in Vertragsdokumenten Unternehmens-Boilerplates oder in Produkttickets Markennamen ungewollt das Ranking verändern. Die Methode bleibt dieselbe: Counterfactuals bauen, Unterschiede messen, Maßnahmen ableiten.
Distanz der Embeddings von männlichen und weiblichen CV-Versionen zur Jobbeschreibung
Exploration: Was Visualisierungen über Embeddings verraten
Die Analyse von Text-Embeddings ist aufgrund ihrer hohen Dimensionalität herausfordernd. Hier macht eine Visualisierung Sinn.
Um die Vektoren visualisieren zu können, werden sie zunächst per Principal Component Analysis (PCA) auf zwei Dimensionen reduziert (hier im Beispiel: Principal Component 1 und 2).
Generell gilt:
PCA extrahiert die beiden Komponenten aus dem hochdimensionalen Vektorraum, für die ein Datensatz die größte Varianz aufweist, und macht damit Strukturen sichtbar.
Die Idee hinter der Visualisierung ist es, Cluster zu erkennen (z.B. thematisch, fachlich, technologisch), welche Rückschlüsse auf die in Embeddings kodierten Inhalte geben. Und so Matchingfaktoren aufzudecken.
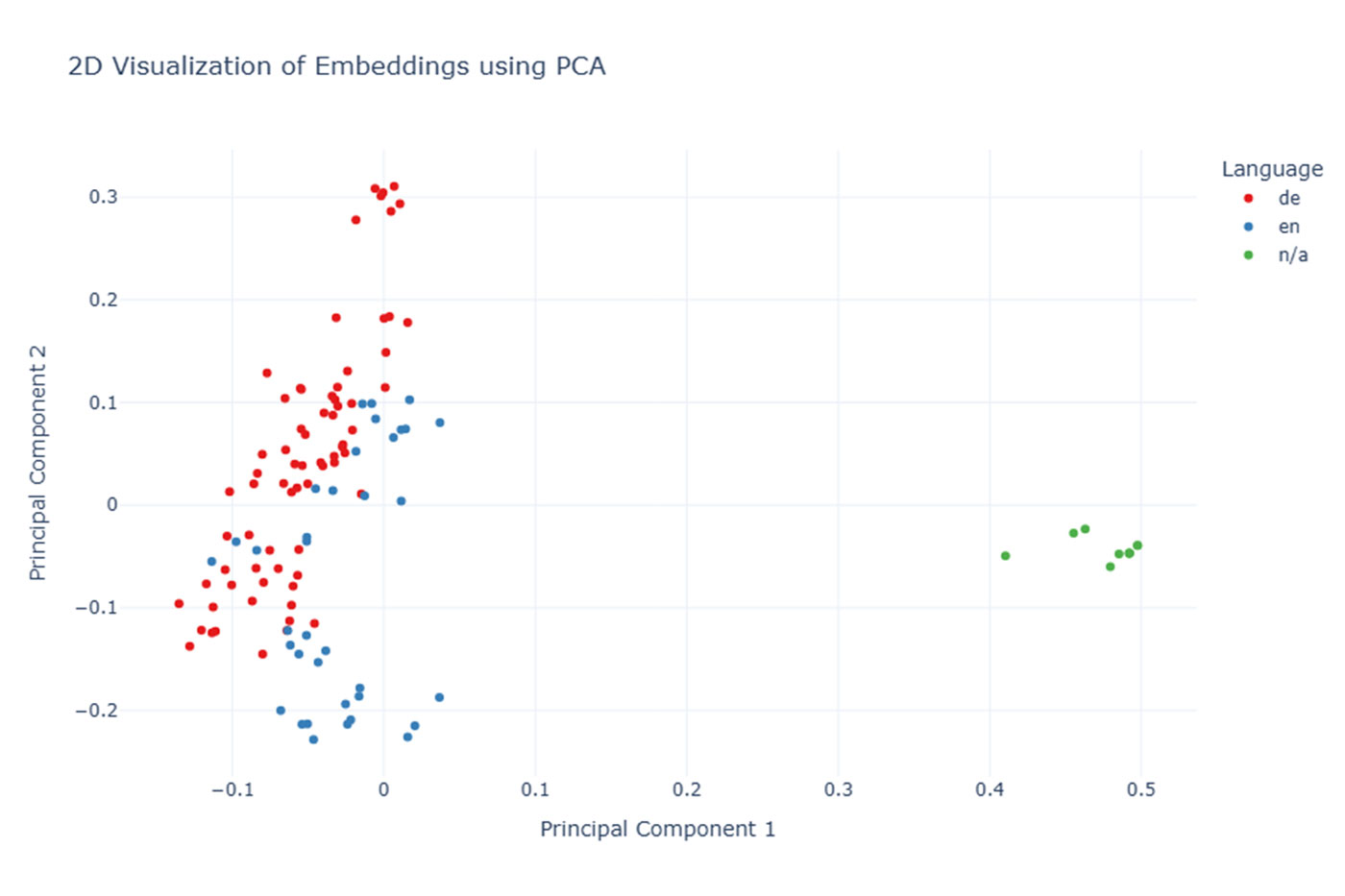
Die Visualisierungsergebnisse zeigen jedoch primär strukturelle statt inhaltlicher Cluster – entstanden durch:
Leere/fehlerhafte Inhalte: Ein Cluster von CVs enthält de facto nur Leerzeichen und zeigt auf ein Parsing-Problem.
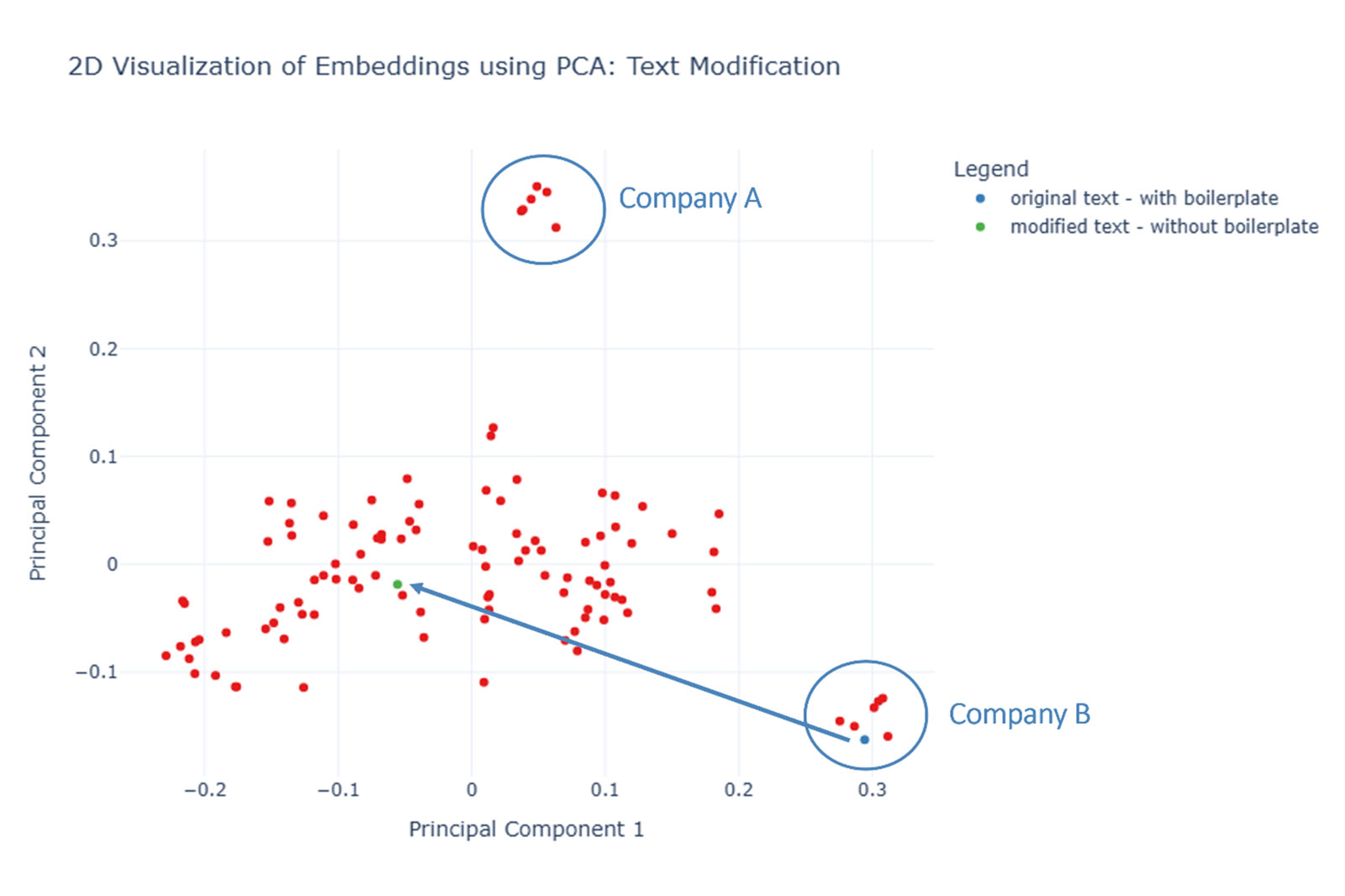
Unternehmenszugehörigkeit: Wiederkehrende firmenspezifische Textbausteine (z.B. im Footer/Header der Dokumente) führen zu überproportionalen Ausschlägen in den Embeddings.
Gruppierung der CV-Embeddings nach Sprache
Visualisierung nach Ausschluss der fehlerhaft eingelesenen CVs. Das Löschen firmeneigener Textblöcke beseitigt die strukturelle Abweichung – das CV-Embedding aus dem Unternehmenscluster (blauer Punkt) bewegt sich zum Rest (grüner Punkt).
Von Mustern zu Maßnahmen – Insights aus der PCA
Strukturelle Effekte beeinflussen die Ähnlichkeitsbewertung. So können CVs allein aufgrund von Sprache, Formatierung oder Firmennennung benachteiligt werden. Fehlerhafte Dokumente können nicht matchen und fehlen in der Antwortgenerierung.
Maßnahmen zur Verbesserung des Matchings:
Qualitätssicherung beim Einlesen: Validierung der extrahierten Texte nach dem Parsen der Dokumente
Sprachvereinheitlichung: z.B. Standard-Sprache definieren und Texte übersetzen – sowohl für CVs als auch für Jobbeschreibungen
Entfernen firmenspezifischer Informationen, die nicht Use-Case-relevant sind
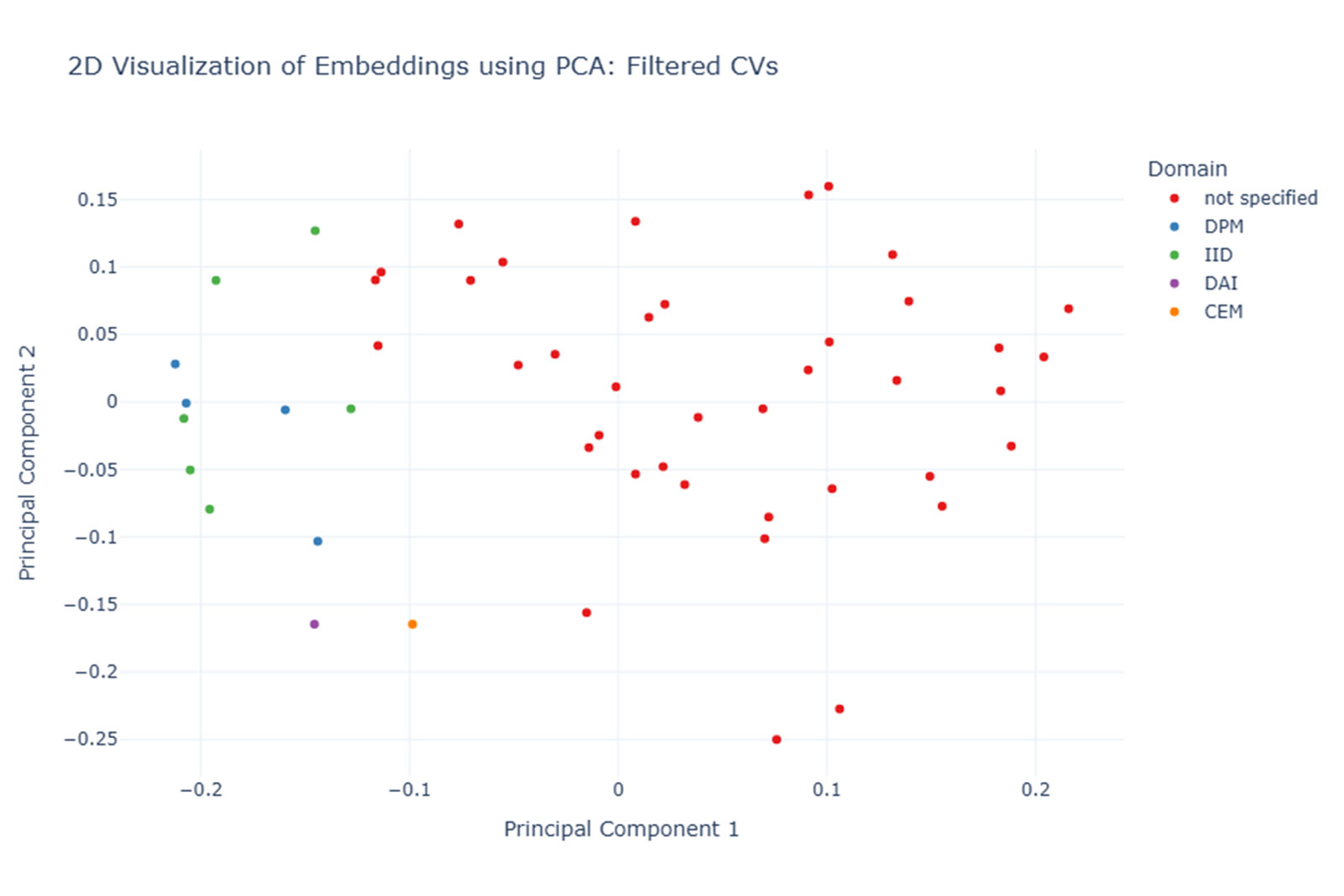
Nun werden die Embeddings der CVs mit den genannten Auffälligkeiten ausgeschlossen und erneut eine PCA durchgeführt. Wir erwarten jetzt klarere semantische Cluster in unserer 2D-Visualisierung.
Das Ergebnis hat sich leicht verbessert und obwohl die Embeddings über den gesamten PCA-Raum verteilt sind, lassen sich Gruppierungen erahnen. Qualitative Stichproben der CVs zeigen jedoch, dass weiterhin inhaltlich nicht nachvollziehbare Embedding-Distanzen bestehen, was sich im Search Ranking widerspiegelt.
Viele CVs sind lang und enthalten zahlreiche Projekte, Technologien und Skills. Das generisch trainierte Embedding-Modell scheint feine, domainspezifische Unterschiede über lange Texte hinweg nicht ausreichend herausarbeiten zu können. Die kleinen semantischen Unterschiede, die entscheidend für ein gutes Match zwischen Jobanforderung und CV sind, werden nicht erkannt. Ein Muster, das sich in Retrieval-Szenarien findet, in denen Dokumente zu lang, zu heterogen oder zu eigen sind.
Visualisierung der CV-Embeddings unter Einfärbung nach b.telligent-Abteilung und externen CVs (rot) zeigt keine auffälligen inhaltlichen Cluster.
Chunking als Gamechanger für präzisere Ergebnisse
Die Lösung:
Chunking – das Zerteilen der CVs in sinnvolle Abschnitte; nämlich in einzelne Projekte. Diese Textabschnitte werden erneut mithilfe des Embedding-Modells in Vektoren überführt und durch eine PCA visualisiert.
Es entstehen jetzt trennschärfere Cluster, die sich inhaltlich voneinander unterscheiden. Die Vektorsuche liefert nun ebenfalls passgenauere Ergebnisse. Kürzere, fokussierte Textsegmente erzeugen kontrastreichere Embeddings – die Ähnlichkeitssuche wird effektiver und erklärbarer („passt wegen Projekt X/Technologie Y“). Gleiches gilt für die Jobbeschreibung: Ein „Alles-drin“-Text kann die Präzision des Query-Embeddings mindern. Eine Fokussierung auf „Muss-Anforderungen“ kann das Matching erleichtern und erspart manuelle Nacharbeit.
Visualisierung von Projekt-Embeddings zeigt Cluster nach fachlicher Zugehörigkeit des Bewerbenden
Fazit: Von der Blackbox zur steuerbaren Retrieval-Engine
Die beschriebene Analyse hat gezeigt, dass Stolpersteine bei der Verwendung von Text-Embeddings im Retrieval-Prozess vorhanden sind, die aber aufgedeckt werden können. So lassen sich also für die Analyse konkrete Maßnahmen ableiten, die die Präzision der Ähnlichkeitssuche erhöhen:
Datenqualität: Parsing-Checks, Sprach-Standards, Herausfiltern von standardisierten Textbausteinen in Dokumenten
Fairness: Neutralisierung von kontextspezifischen Einflüssen
Chunking & Query-Fokussierung: Dokumente und Nutzerabfragen auf wesentliche Einheiten zuschneiden
Diese Maßnahmen führen zu:
Besseren Ergebnissen: Höhere Relevanz, mehr Fairness, weniger Fehler
Wirtschaftlichem Nutzen: Geringere Review-Aufwände für Endnutzer der KI-Anwendung, schnellere Entscheidungen durch weniger Re-Promptings
Governance & Vertrauen: Erklärbare Treffer, dokumentierte Maßnahmen gegen Bias
Die in unserer Analyse gewonnenen Erkenntnisse stammen aus dem spezifischen Embedding-Modell und den von uns verarbeiteten Dokumenten. In Deiner RAG-Anwendung wird vielleicht ein anderes Embedding-Modell verwendet und andere Dokumente verarbeitet, die ihre eigenen Herausforderungen mitbringen.
Dennoch kannst Du mit den von uns beschriebenen Ansätzen Muster erkennen und konkrete Hebel zur Qualitätssteigerung Deiner RAG-Ergebnisse einsetzen:
Hypothesen & Tests: Zielgerichtete Text-Varianten (Counterfactuals) bauen und Differenzen messen
Text-Embeddings in ihrer Dimension reduzieren und sie im 2D- oder 3D-PCA Raum visualisieren
Brauchst Du Unterstützung bei der Implementierung oder Optimierung Deiner RAG-Anwendung? Dann melde Dich gerne bei uns.
Du hast Fragen? Kontaktiere uns
Your contact person
Dr. Sebastian Petry
Domain Lead Data Science & AI
Wer ist b.telligent?
b.telligent – das ist Data Analytics, AI, Customer Engagement und Data Visualisation. Das ist Deutschland, Österreich, die Schweiz und Rumänien. Doch das Entscheidende ist unser Team: Menschen mit echter Leidenschaft für Daten, die gemeinsam innovative Lösungen schaffen und Unternehmen nachhaltig voranbringen.
Im Zeitalter von Agentic AI entscheidet die Qualität des Retrievals oft darüber, wie zuverlässig ein System arbeitet. Anhand eines AI-Staffing Use Cases zeigen wir, wie sich Retrieval mit Late Interaction Retrieval, Cross-Encodern und LLM-basierten Verfahren gezielt verbessern lässt.
Mit Snowflake Document AI können innerhalb der Datenplattform ganz einfach Informationen aus Dokumenten, zum Beispiel Rechnungen oder handgeschriebenen Dokumenten, extrahiert werden. Document AI ist unkompliziert und leicht zu nutzen: entweder via grafische Benutzeroberfläche, via Code in einer Pipeline oder integriert in eine Streamlit-Applikation. In diesem Beitrag erklären wir Dir das Feature, beschreiben, wie die Integration in die Plattform funktioniert, und stellen interessante Anwendungsmöglichkeiten vor.
Neuronale Netze werden erfolgreich auf so ziemlich jeden Datentyp angewandt: Bilder, Audio, Texte, Videos, Graphen usw. Nur wenn es um Tabellendaten geht, sind baumbasierte Ensembles wie Random Forests und Gradient Boosted Trees immer noch sehr viel verbreiteter. Wenn man diese erfolgreichen Klassiker durch neuronale Netze ersetzen will, dürfte Ensemble Learning immer noch eine Schlüsselidee sein. Dieser Blogbeitrag erklärt, warum das so ist. Dazu gibt’s ein Notebook mit den praktischen Details.