Das Potenzial von Openflow freisetzen: Praktische Lösungen für reale Herausforderungen bei der Datenintegration
Mathias Heinze
Mathias Heinze
Principal Consultant
Mathias ist Berater mit langjähriger Erfahrung in Data Vault Modellierung, DWH-Architektur und DWH-Automatisierung und hat Versicherungen zu diesen Themen beraten. Seine Projekterfahrung umfasst dabei den kompletten Wertschöpfungsprozess von der Analyse, Planung und Konzeption bis hin zur Umsetzung mit Fokus auf Snowflake und Oracle Technologien. Er verfügt zudem über fundiertes Wissen in Domain-Specific-Languages (DSL) zur Codegenerierung, Big Data und Cloud Technologien sowie agilen Projektvorgehen.
Openflow von Snowflake macht die Datenintegration schneller, einfacher und effizienter. In diesem Artikel zeigen wir, wie sich diese Vorteile in der Praxis auswirken. Anhand eines echten Beispiels werden Strategien für die einfache und leistungsstarke Verarbeitung großer Mengen kleiner, eingehender Dateien vorgestellt.
Inhaltsverzeichnis
Openflow ist die neueste Lösung von Snowflake für Unternehmen: eine offene, erweiterbare und sichere Datenintegrationsplattform, die bidirektionalen Datenaustausch in Echtzeit innerhalb von Snowflake ermöglicht. Sie schließt eine wesentliche Lücke - insbesondere in ETL-Workflows, bei denen die Datenextraktion und das Laden traditionell von Drittanbieter-Tools wie Fivetran, Airbyte oder anderen Plattformen abhängt.
In diesem Artikel zeigen wir, wie Openflow bestehende Datenpipelines vereinfachen und optimieren kann. Am Beispiel einer typischen API-basierten Herausforderung stellen wir zwei praktische Lösungen vor, die vollständig mit Openflow erstellt wurden. Diese Ansätze erfordern kein benutzerdefiniertes Scripting oder komplexe Logik. Stattdessen sind sie geradlinig, skalierbar, hochleistungsfähig - und Schritt für Schritt einfach zu folgen.
Hand aufs Herz – IT-Landschaften in der Realität sind selten perfekt. Systeme wachsen über Jahre hinweg und bringen dabei oft unnötige Komplexität mit sich. Nicht jedes Unternehmen braucht eine Datenbereitstellung in Echtzeit – viele setzen weiterhin auf klassische Batch-Verarbeitung, wie sie in vielen BI-Setups üblich ist. Und der Zugriff auf Quellsysteme läuft in der Praxis selten so reibungslos wie im Lehrbuch – oder wie man es sich wünschen würde.
In diesem Artikel beleuchten wir ein reales Kundenprojekt: Die Aufgabe bestand darin, in regelmäßigen Abständen – täglich, wöchentlich, monatlich oder je nach Bedarf – einen vollständigen System-Snapshot in Snowflake zu laden. Zwar bieten viele Anwendungen dafür eigene Batch-Schnittstellen an, dieses System jedoch nicht. Stattdessen war lediglich eine REST-API verfügbar, die ausschließlich den Abruf einzelner Datensätze per ID über HTTP zuließ.
Nach Rücksprache mit den zuständigen Systemexperten wurde ein zweistufiges Vorgehen empfohlen:
API-Endpunkt „getAllIDs“ nutzen: Über diesen Einstiegspunkt wird zunächst eine vollständige Liste aller eindeutigen IDs abgerufen – die Grundlage für den folgenden Datenextraktionsprozess.
API-Endpunkt „getDataForID“ nutzen: Im zweiten Schritt wird die Liste iteriert und für jede einzelne ID ein eigener API-Call durchgeführt, um die zugehörigen Daten abzurufen.
Diese Vorgehensweise war technisch alternativlos – brachte aber mehrere operative Herausforderungen mit sich: Das sequenzielle Abrufen tausender IDs ist zeitaufwendig und skaliert schlecht. Es entstehen unzählige kleine Antwortdateien, die einzeln verarbeitet werden müssen. Das Handling vieler kleiner Dateien führt zu höherer Latenz und I/O-Overhead – verursacht durch häufige Metadatenabfragen und das wiederholte Starten von Prozessen. Snowflake empfiehlt daher als Best Practice größere Dateien im Bereich von 100 bis 250 MB (komprimiert), um Performance und Effizienz zu verbessern.
Auch wenn wir an der Art der Datenbereitstellung im Quellsystem nichts ändern konnten, lag die Kontrolle über den Umgang mit den kleinen Dateien bei uns. In den folgenden Abschnitten zeigen wir zwei praxisnahe Openflow-Lösungen, um genau diese Herausforderung effizient zu meistern. Sie dienen gleichzeitig als Implementierungsvorlage und Inspiration für eigene Integrationsszenarien.
Die Kundensystem-Simulation mit Openflow
Vielleicht hast du selbst keinen Zugriff auf ein vergleichbares System – möchtest aber trotzdem Use Cases mit vielen kleinen Dateien testen. Deshalb zeigen wir dir zuerst, wie sich dieses Szenario komplett innerhalb von Snowflake simulieren lässt.
Dazu bauen wir eine vereinfachte Anwendung in Openflow, die die Systemumgebung des Kunden nachbildet. Als Grundlage nutzen wir das TPC-H-Beispieldatenset von Snowflake – in Kombination mit der Snowflake SQL API. Dabei handelt es sich um eine REST-API, über die sich Daten direkt innerhalb der Snowflake-Datenbank abfragen und aktualisieren lassen.
Falls du die Snowflake SQL API noch nicht kennst, empfehlen wir dir einen Blick in die offizielle Dokumentation – dort findest du eine umfassende Anleitung für den Einstieg.
Schritt 1: Liste aller IDs abrufen
Im ersten Schritt erstellen wir eine Liste mit eindeutigen Kunden-IDs. Als Datenquelle dient die Tabelle SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.CUSTOMER, auf die wir über die SQL API von Snowflake zugreifen. Dafür senden wir eine POST-Anfrage, die alle Kundenschlüssel abruft – diese fungieren als eindeutige IDs. Im nächsten Schritt nutzen wir diese, um für jede ID den vollständigen Datensatz über die API abzurufen.
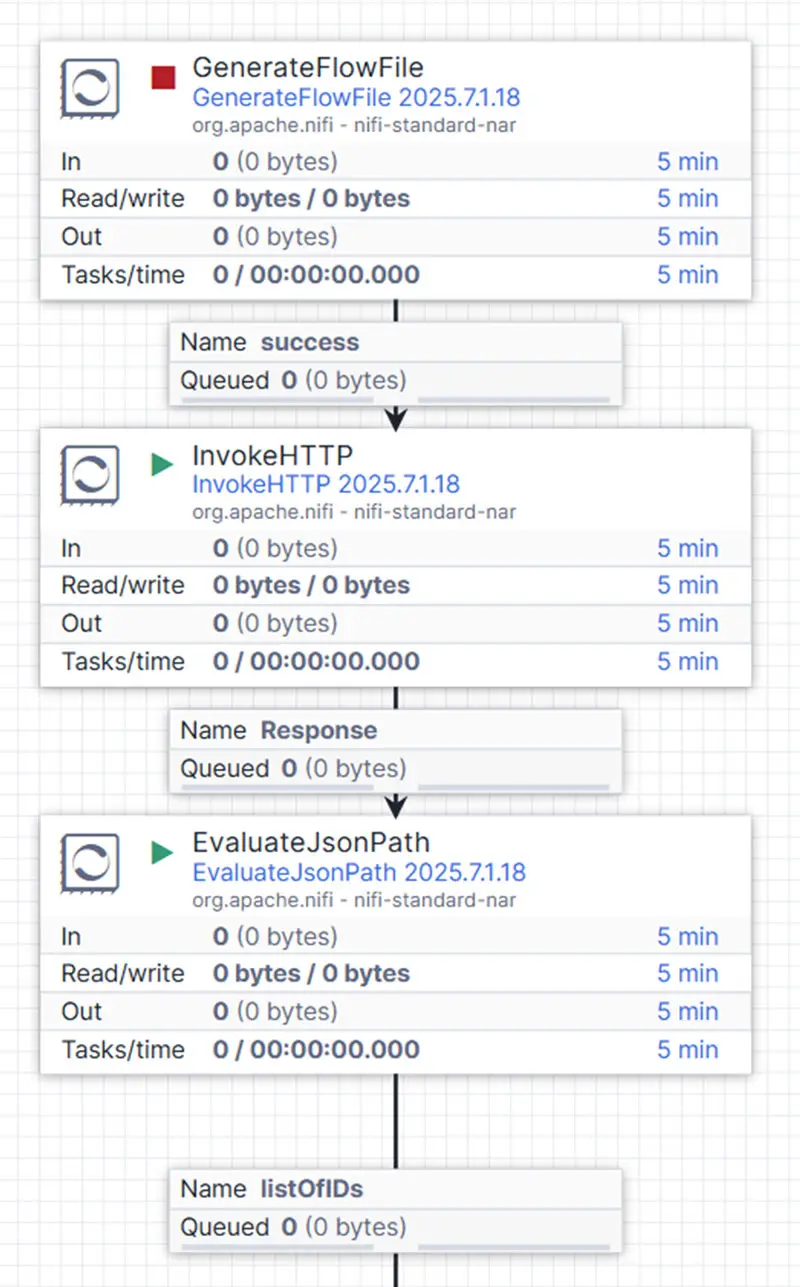
Wie bereits erwähnt, setzen wir den gesamten Prozess mit Openflow um. Der folgende Flow zeigt eine beispielhafte Implementierung und macht deutlich, wie sich dieser Schritt strukturiert und wiederholbar umsetzen lässt.
Unser Hauptprozessor InvokeHTTP übernimmt den Aufruf des Snowflake-API-Endpunkts unter /api/v2/statements. In Openflow funktioniert dieser Prozessor wie folgt: Die Attribute jeder Flow-Datei werden als Header in die Anfrage übernommen, der Inhalt der jeweiligen Flow-Datei bildet den Request-Body.
Für den Aufbau dieser Anfrage nutzen wir den GenerateFlowFile-Prozessor, um den Body-Inhalt zu definieren. Dieser enthält sowohl das Compute-Warehouse als auch das SQL-Statement, das wir über die Snowflake SQL API ausführen möchten. In unserem Beispiel rufen wir alle Kundenschlüssel aus der Tabelle SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.CUSTOMER ab – eine Tabelle mit rund 150.000 Einträgen.
Der Request-Header – konfiguriert als Attribute – legen das Content-Type-Format (JSON) und die Authentifizierungsmethode fest. Hier verwenden wir ein Personal Access Token (PAT), das zuvor über Snowflake Snowsight generiert wurde.
Die Antwort von InvokeHTTP wird im JSON-Format zurückgeliefert und im Content der Flow-Datei innerhalb einer Response-Queue abgelegt. Da die Antwort sowohl relevante Daten als auch Metadaten enthält, extrahieren wir anschließend ausschließlich die Liste der Kunden-IDs. Dafür kommt der EvaluateJsonPath-Prozessor zum Einsatz, der die JSON-Antwort analysiert und die vollständige ID-Liste isoliert.
Und das war’s auch schon: Mit nur drei Prozessoren simulieren wir erfolgreich den Zugriff auf eine HTTP-API, die eine eindeutige Liste von IDs zurückliefert. Das Ergebnis ist eine einzelne Flow-Datei, die alle Kundenschlüssel aus der Tabelle SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.CUSTOMER enthält.
Im zweiten Schritt der System-Simulation konzentrieren wir uns darauf, die tatsächlichen Daten zu jeder einzelnen ID abzurufen. Dafür durchlaufen wir die zuvor erstellte Liste der Kunden-IDs und senden für jede ID eine eigene API-Anfrage.
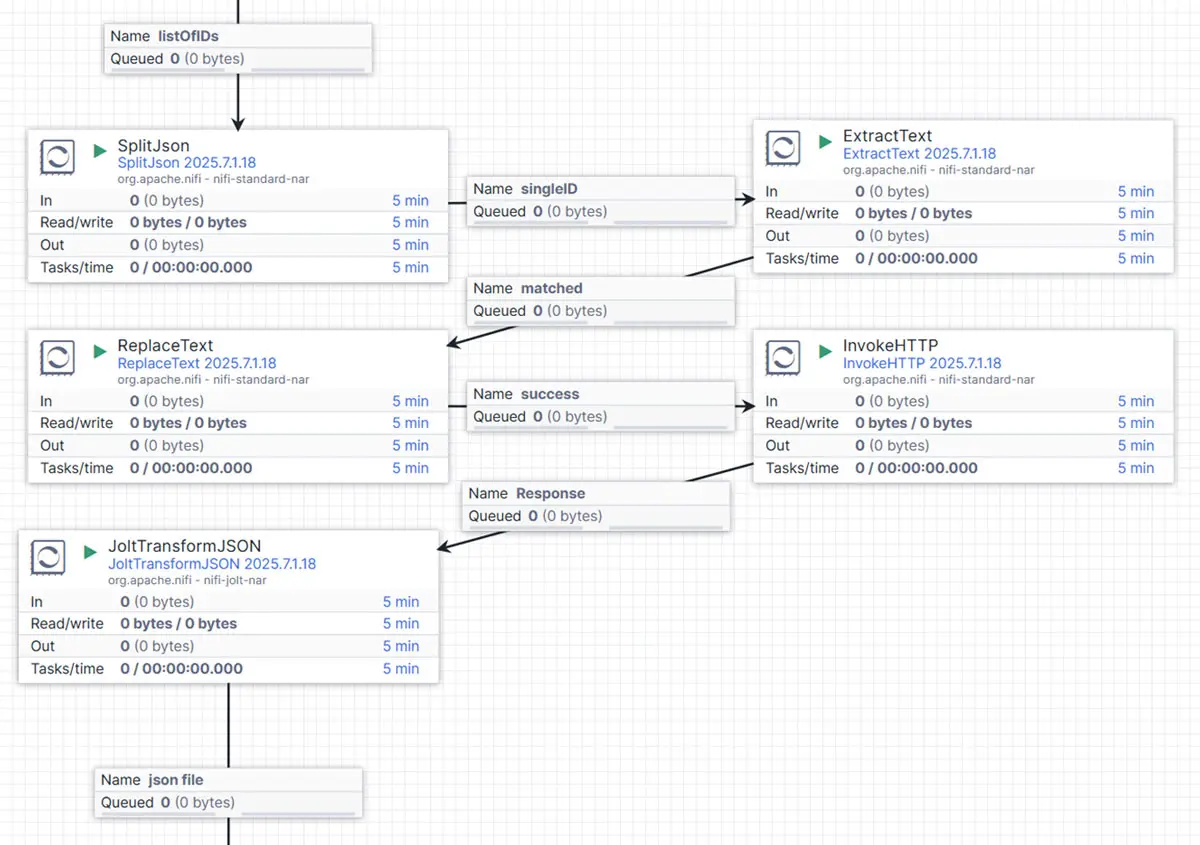
Der Ablauf dieses Prozesses ist wie folgt aufgebaut:
Zunächst nutzen wir den SplitJson-Prozessor, um die Liste der Kunden-IDs in einzelne Flow-Dateien aufzuteilen – jede davon enthält genau eine ID. Nach dem Split befindet sich pro Datei nur noch eine einzelne ID im Content.
Da wir diese ID später als Attribut für den API-Request benötigen, kommt anschließend der ExtractText-Prozessor zum Einsatz. Er extrahiert den Inhalt und speichert ihn als neues Attribut mit dem Namen ID_VALUE.
Im nächsten Schritt verwendet der ReplaceText-Prozessor dieses ID_VALUE-Attribut, um dynamisch den Request-Body zu erzeugen. Dieser wird dann an den InvokeHTTP-Prozessor übergeben, der – wie zuvor beim Abruf der ID-Liste – nun für jede einzelne Kunden-ID einen separaten API-Call durchführt.
Die Antwort des InvokeHTTP-Prozessors wird wieder als Inhalt der Flow-Datei gespeichert – diesmal enthält sie jedoch die tatsächlichen Kundendaten im JSON-Format. Da uns nur der eigentliche Dateninhalt interessiert und nicht die umgebenden Metadaten, kann optional der JoltTransformJSON-Prozessor eingesetzt werden, um nur die relevanten Felder zu extrahieren. Ob dieser Schritt notwendig ist, hängt vom individuellen Use Case ab.
Und damit ist Schritt zwei abgeschlossen: Jede Flow-Datei enthält nun ein sauberes JSON-Dokument mit dem vollständigen Datensatz eines einzelnen Kunden.
Durch die Kombination der ersten beiden Schritte haben wir erfolgreich die Anwendung des Kunden nachgebildet. Dieses Setup erzeugt einzelne Dateien über API-Aufrufe – jede Datei enthält den vollständigen Datensatz für einen einzelnen Kunden.
Wie erwartet führt dies zu einer sehr großen Anzahl an Dateien. In unserem Fall lag die Gesamtzahl bei über 150.000. Ein wichtiger Leistungsfaktor in diesem Zusammenhang ist, dass der Hauptengpass bei der Ausführung durch die einzelnen API-Aufrufe für jede eindeutige ID entsteht.
Glücklicherweise ermöglicht es Openflow, diese Prozesse problemlos zu parallelisieren. Durch die Anpassung der Prozessor-Einstellungen können wir mehrere gleichzeitige Ausführungen aktivieren, wodurch sich die Verarbeitungsgeschwindigkeit und die gesamte Effizienz erheblich verbessern.
Im nächsten Schritt schauen wir uns an, wie diese Dateien nahtlos in Snowflake integriert werden können.
Unsere zentralen Einstellungen:
Processor
Attribute
Value
SplitJson
JsonPath Expression
$[*]
ExtractText
ID_VAL
(.*)
ReplaceText
Replacement Strategy
Regex Replace
Replacement Value
{ "warehouse" : "<warehouse name>", "statement" : "select * from SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.CUSTOMER WHERE C_CUSTKEY = ${ID_VAL}"
}
Optimiertes Handling kleiner Dateien mit Openflow: Zwei effektive Lösungen
Nachdem wir die Anwendung des Kunden erfolgreich mit der SQL API von Snowflake simuliert haben, schauen wir uns nun zwei Ansätze an, wie sich große Mengen kleiner Dateien effizient mit Snowflake Openflow verarbeiten lassen.
Die erste Lösung basiert auf Snowpipe Streaming, die zweite auf einem klassischen Batch-Ansatz unter Einsatz eines Blob Storage.
Snowpipe Streaming
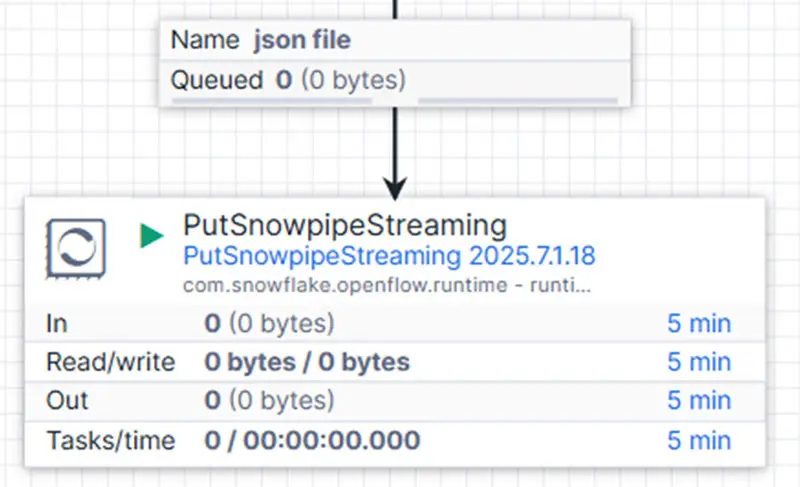
Dies ist wahrscheinlich die einfachste, kosteneffizienteste und zeitsparendste Methode, um Daten aus API-basierten Anwendungen direkt in Snowflake zu laden. In Openflow nutzt du dafür den PutSnowPipeStreaming-Prozessor, um die Daten direkt in eine definierte Snowflake-Tabelle zu streamen.
Die Konfiguration ist unkompliziert und ermöglicht eine nahezu echtzeitnahe Verarbeitung mit hoher Skalierbarkeit – ganz ohne Performanceeinbußen. Gleichzeitig ist dieser Ansatz dank Snowflakes neuem Preismodell besonders budgetfreundlich: Statt wie früher pro Datei wird nun pro verarbeitetem Gigabyte abgerechnet. Das senkt die Kosten im Durchschnitt um rund 50 %.
Der Flow für diese Lösung ist folgendermaßen aufgebaut:
Die eingehenden Flow-Dateien – im Standard-JSON-Format – werden direkt in die Zieltabelle gestreamt. Wichtig: Diese Tabelle muss in Snowflake bereits vorhanden sein und über die entsprechenden Spalten verfügen, die zur Struktur der JSON-Daten passen.
In unseren Tests erzielten wir mit dem PutSnowpipeStreaming-Prozessor und den Standardeinstellungen bereits hervorragende Ergebnisse. Zwischen den API-Anfragen (ausgelöst durch den InvokeHTTP-Prozessor im Hoch-Parallelmodus) und dem eigentlichen Datenstreaming gab es praktisch keine Verzögerung. Falls gewünscht, lässt sich die Performance durch Anpassung von Parametern wie Client Lag und Maximum Batch Size weiter optimieren.
Batch-Ingestion über Blob Storage
Unsere zweite Lösung ist etwas komplexer und adressiert ein anderes Szenario: Angenommen, du möchtest die Daten nicht direkt nach Snowflake laden, sondern zunächst in einem Blob Storage ablegen – etwa als Datalake Schicht für dein Data Warehouse. Das kann ein AWS-S3-Bucket, Azure Blob Storage oder ein anderer Objektspeicher sein.
Vielleicht baust du gerade eine Medallion-Architektur, bei der die Bronze-Schicht rohe und standardisierte Dateiformate speichert. Genau eine solche Architektur zeigen wir hier exemplarisch mit Openflow.
Der Prozess beginnt damit, dass die API-generierten Dateien im Rohformat in einem S3-Bucket gespeichert werden. Anschließend werden diese Dateien standardisiert – zum Beispiel ins Parquet-Format überführt – und die vielen kleinen Dateien zu wenigen, größeren Dateien zusammengefasst. Diese Optimierung verbessert die Performance beim späteren Import in Snowflake via COPY INTO-Befehl deutlich – und entspricht zugleich den empfohlenen Dateigrößen von Snowflake.
Rohdaten nach AWS S3 laden
Im ersten Schritt erweitern wir unseren API-Flow so, dass die abgerufenen Daten in einem Blob-Speicher abgelegt werden – in unserem Fall einem AWS-S3-Bucket. Mit dieser Erweiterung können wir die Rohdaten zwischenspeichern, bevor sie weiterverarbeitet werden.
So sieht der entsprechende Flow aus:
Im ersten Schritt dieser Erweiterung benennen wir die eingehenden JSON-Dateien mithilfe des UpdateAttribute-Prozessors um. Dabei wird eine Funktion angewendet, die die Dateipfade gemäß der erwarteten Ordnerstruktur im Blob Storage organisiert. Die Struktur folgt einem partitionierten Layout, z. B.:
Zusätzlich erhält jede Datei einen eindeutigen Namen, der sich aus einem Zeitstempel und einer systemgenerierten UUID zusammensetzt.
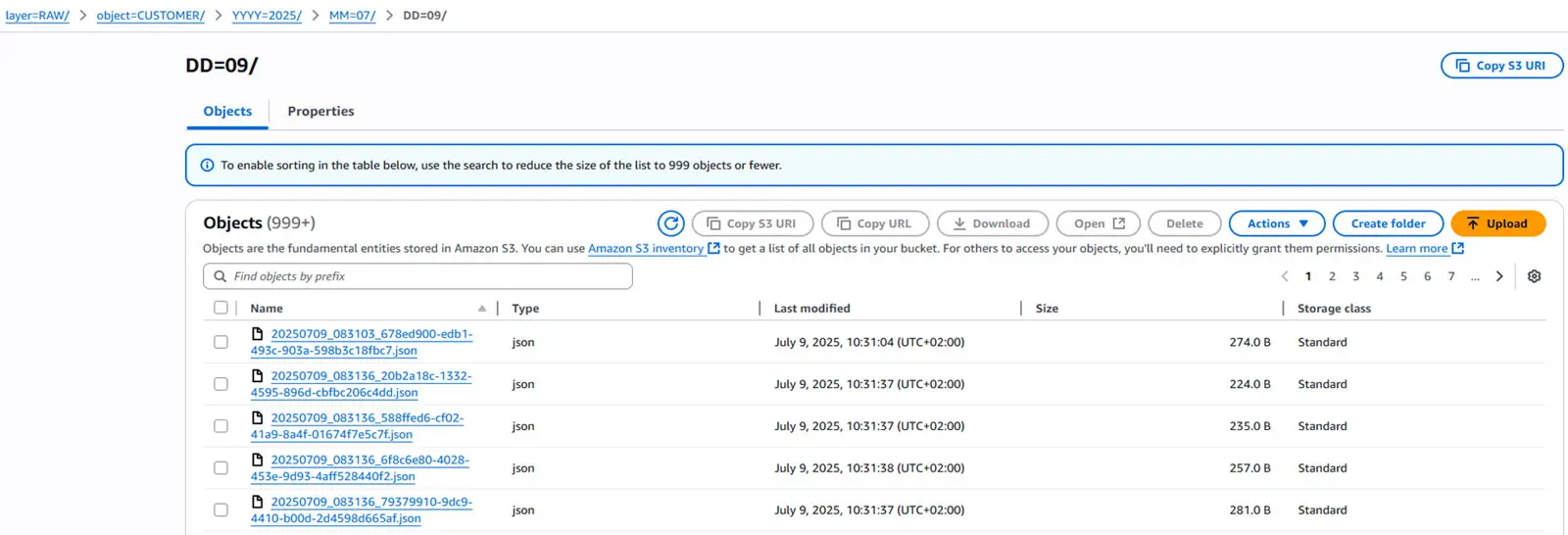
Im zweiten Schritt nutzen wir den PutS3Object-Prozessor, um alle umbenannten Dateien im Rohformat in unseren S3-Bucket hochzuladen. Der Ablauf ist unkompliziert – und nach erfolgreichem Upload sind die Dateien sauber wie folgt strukturiert abgelegt:
Im nächsten Schritt transformieren wir die im S3-Bucket abgelegten Dateien – also jene, die sich in der Rohdaten-Schicht befinden – in ein standardisiertes Format. Dieser Schritt umfasst zwei zentrale Aufgaben: die Konvertierung aller JSON-Dateien in das Parquet-Format sowie das Zusammenführen vieler kleiner Dateien in wenige, größere Dateien.
Diese Optimierung verbessert nicht nur die Speichereffizienz, sondern sorgt auch für einheitliche Schemastrukturen. Das bringt spürbare Vorteile – sowohl in der Performance als auch bei den Kosten. Insbesondere die Reduzierung kleiner Einzeldateien erhöht die Ladegeschwindigkeit und entspricht den empfohlenen Dateigrößen von Snowflake für eine optimale Verarbeitung.
In unserer Umsetzung ist das S3-Verzeichnis wie folgt aufgebaut:
Der Flow, den wir für diesen Verarbeitungsschritt verwenden, ist wie folgt aufgebaut:
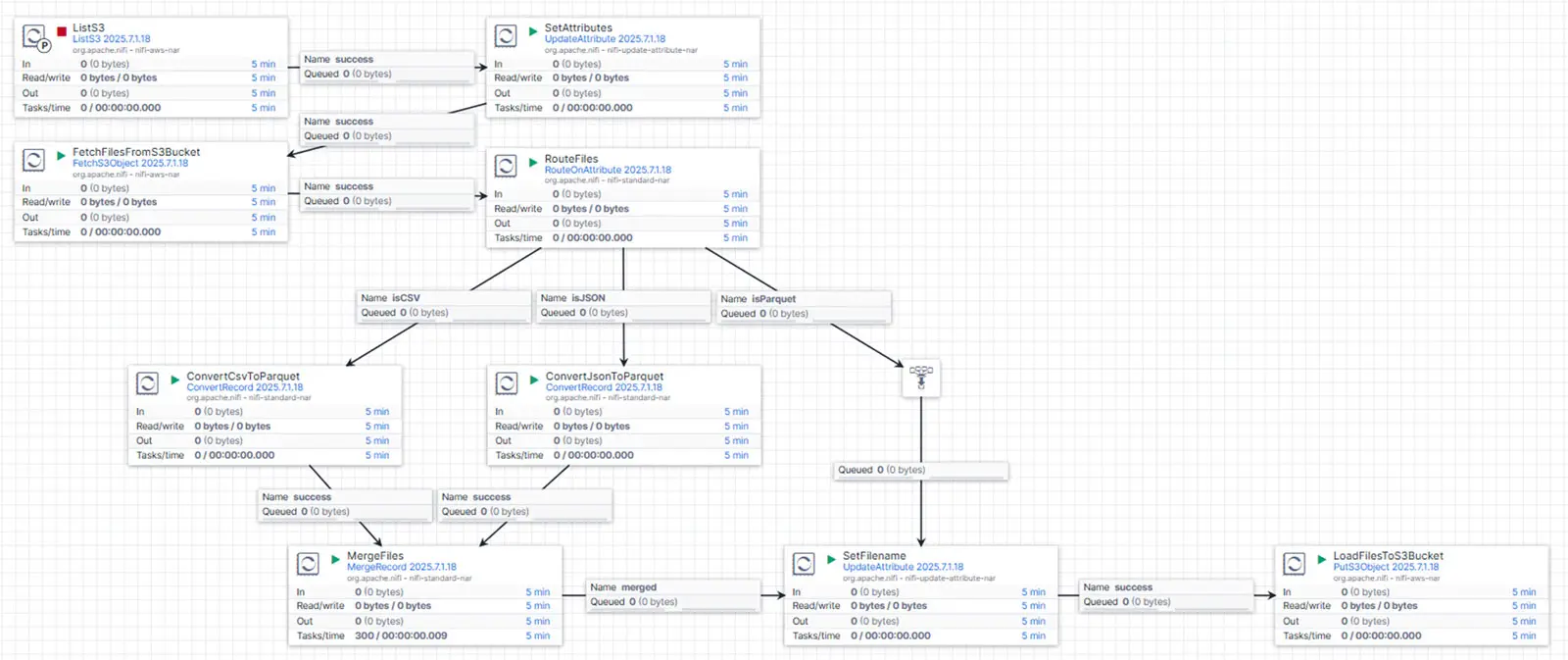
Wir beginnen mit dem ListS3-Prozessor, der so konfiguriert ist, dass er nur Dateien aus dem Verzeichnispfad layer=RAW/ zurückliefert. Die integrierten Tracking-Einstellungen des Prozessors ermöglichen es, bereits verarbeitete Dateien gezielt zu steuern. Diese eingebaute „Gedächtnisfunktion“ erlaubt uns damit eine inkrementelle Verarbeitung von Dateien.
Als Tracking-Strategie wählen wir eine Variante, die auf den Zeitstempeln der Dateien basiert.
Anschließend verwenden wir den UpdateAttribute-Prozessor, um mehrere wichtige Attribute der Flow-Datei für die nachfolgenden Schritte festzulegen. Diese Attribute – wie ${S3FILENAME}, ${S3FILEEXTENSION}, ${S3OBJECT} und ${S3PATH} – werden aus dem ursprünglich systemgenerierten filename abgeleitet.
Zur besseren Veranschaulichung hier einige Beispielwerte:
Anschließend verwenden wir den FetchS3Object-Prozessor, um die Rohdaten aus dem S3-Bucket in Openflow zu laden. Mithilfe des Flow-File-Attributs ${S3FILEEXTENSION} bestimmen wir mit dem RouteOnAttribute-Prozessor, wie die Dateien im nächsten Schritt verarbeitet werden. Dieser Prozessor verteilt die Dateien je nach Dateiendung auf unterschiedliche Flows, die jeweils auf ein bestimmtes Dateiformat zugeschnitten sind. In unserem Setup erfolgt das Routing für .csv, .json und .parquet:
isCSV: Dateien werden an den ConvertCsvToParquet-Prozessor geleitet, der CSV-Dateien ins Parquet-Format überführt.
isJSON: Dateien werden an den ConvertJsonToParquet-Prozessor geleitet, der JSON-Dateien ins Parquet-Format überführt.
isParquet: Diese Dateien durchlaufen die Pipeline ohne weitere Verarbeitung.
Da unser Use Case ausschließlich JSON-Dateien umfasst, werden alle Dateien in den „JSON-Flow“ geleitet. Dort übernimmt der ConvertRecord-Prozessor die Umwandlung ins Parquet-Format. Er ist so konfiguriert, dass er JsonTreeReader als Input Reader und ParquetRecordSetWriter als Output Writer verwendet.
Der ConvertCsvToParquet-Prozessor ist ebenfalls eingerichtet – mit CSVReader als Input –, kommt in unserem Fall jedoch nicht zum Einsatz. Dies zeigt aber, dass unser Flow problemlos mehrere Formate unterstützt.
Nach der Umwandlung verwenden wir den MergeRecord-Prozessor, um viele kleine Parquet-Dateien zu wenigen großen zusammenzuführen. Die Zusammenführung erfolgt anhand eines Partitionierungsschlüssels – in unserem Fall ist das das Attribut ${S3PATH}, das alle relevanten Kriterien wie Layer, Objekt und Datum enthält.
Zur Optimierung konfigurieren wir den Merge-Prozessor wie folgt:
30 Sekunden Wartezeit vor der Zusammenführung,
maximale Dateigröße pro Merge: 250 MB,
bis zu 10.000 Datensätze pro Batch.
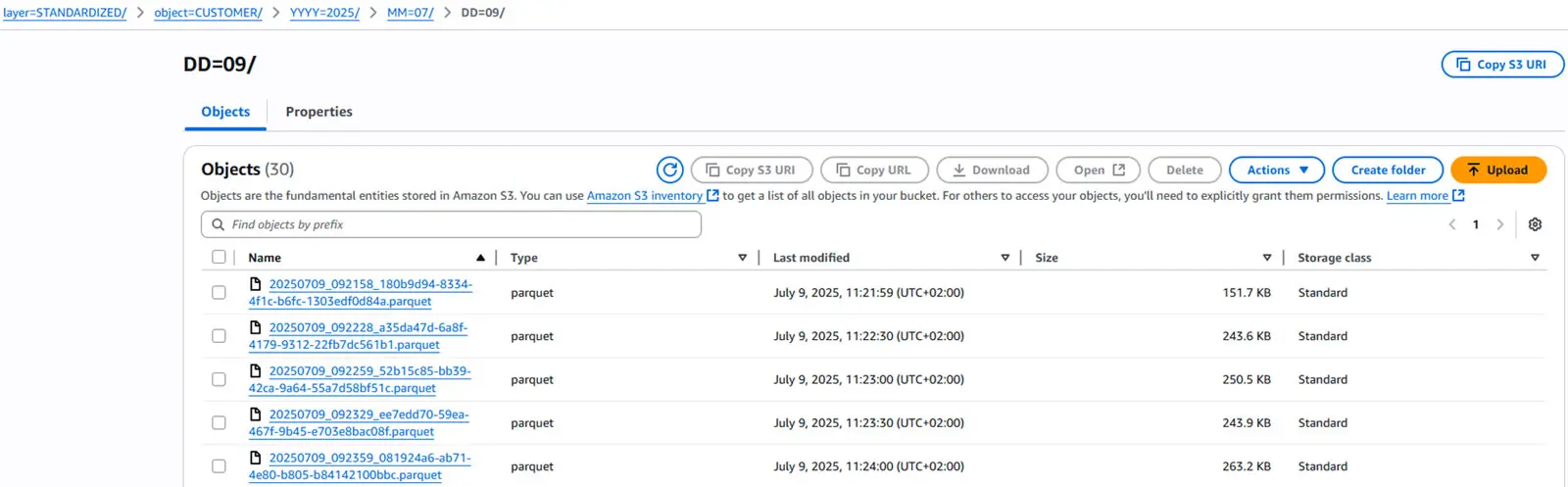
In unseren Tests erzielte diese Konfiguration bereits hervorragende Ergebnisse: Über 150.000 JSON-Dateien wurden ohne zusätzliches Feintuning zu nur 90 Parquet-Dateien zusammengeführt.
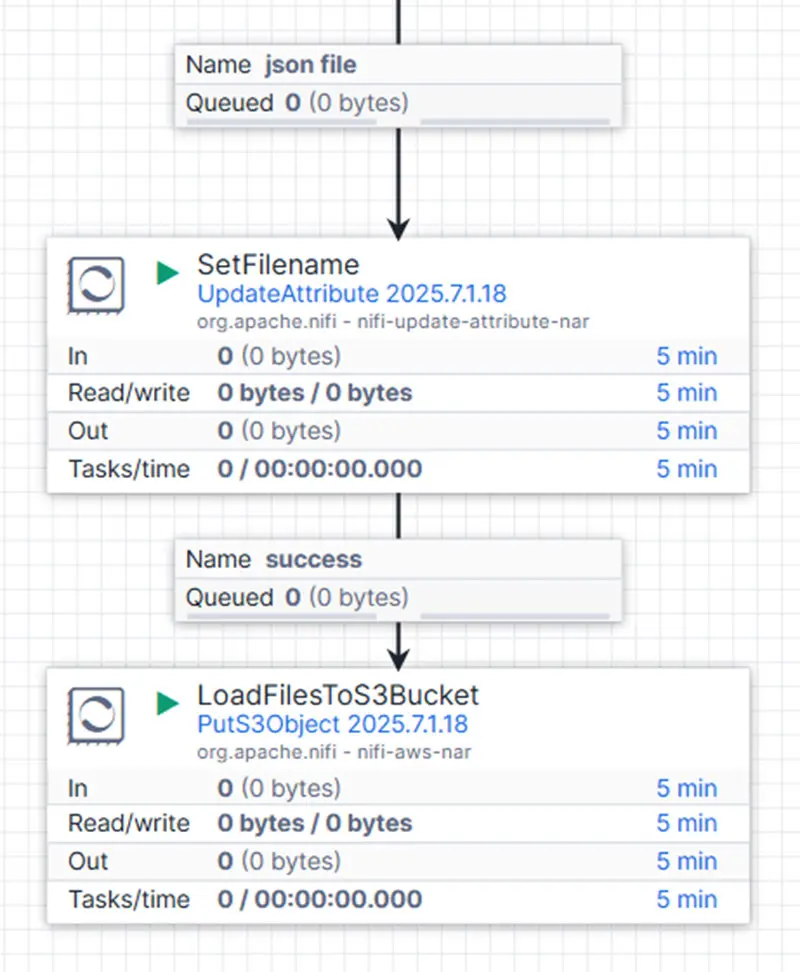
Im vorletzten Schritt nutzen wir erneut den UpdateAttribute-Prozessor, um jeder zusammengeführten Datei einen neuen Namen zu geben. Dieser enthält die Verzeichnisebene STANDARDIZED sowie einen Zeitstempel und eine UUID zur eindeutigen Identifizierung.
Im finalen Schritt übernimmt der loadFilesToS3Bucket-Prozessor das Hochladen der umbenannten und zusammengeführten Parquet-Dateien zurück in den AWS S3-Bucket – nun jedoch organisiert unter der neuen, standardisierten Verzeichnisstruktur.
Unsere hochgeladenen Dateien folgen jetzt einem klaren und konsistenten Schema.
Mit diesem Schritt sind alle Dateien aus dem ursprünglichen Datenfluss nun in das Parquet-Format konvertiert, auf einheitliche Dateigrößen konsolidiert und effizient im Blob-Speicher abgelegt. Und das alles – ohne eine einzige Zeile benutzerdefinierten Codes, umgesetzt in nur wenigen, klar strukturierten Schritten.
Im letzten Schritt laden wir die standardisierten Dateien aus dem Blob Storage in Snowflake. Dafür verwenden wir eine interne Stage kombiniert mit dem COPY INTO-Befehl.
Natürlich werden auch weitere Ladeverfahren unterstützt – etwa externe Stages, externe Tabellen, Snowpipe Streaming, Snowpipe oder sogar Iceberg Tabellen.
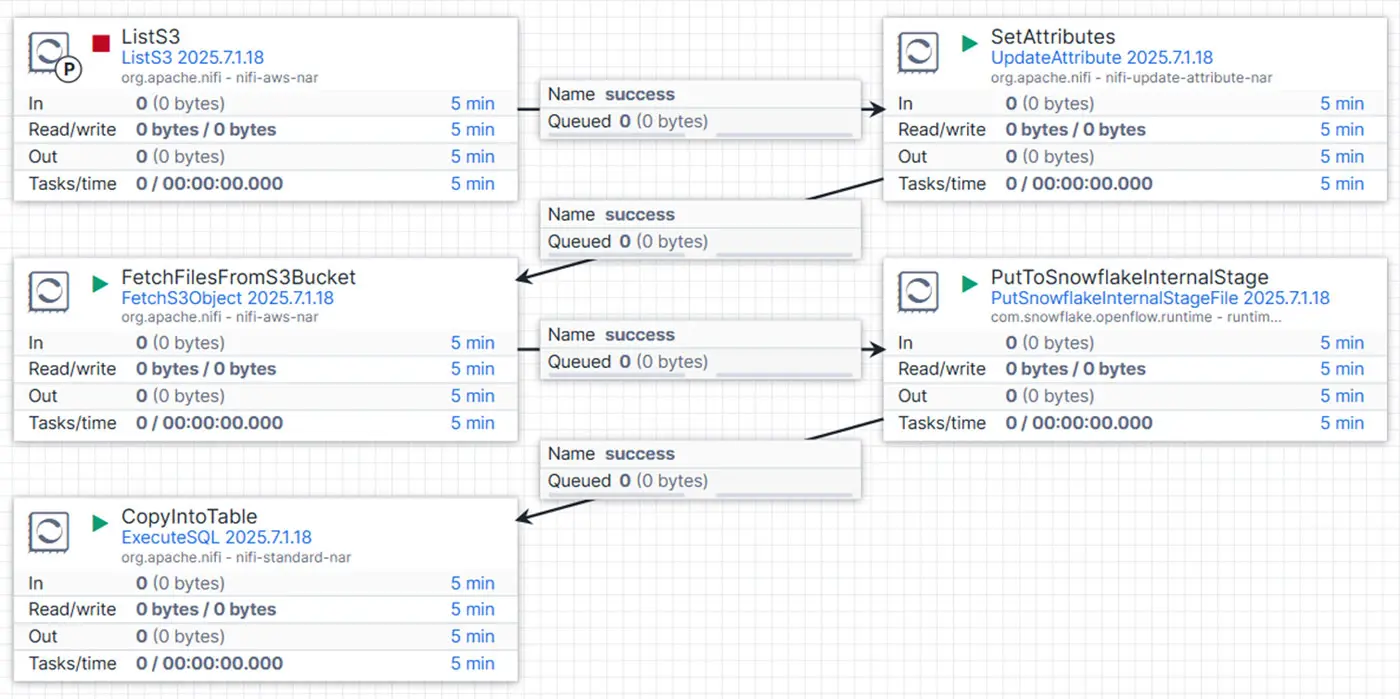
Das folgende Diagramm zeigt den Flow, den wir eingesetzt haben:
Die ersten drei Schritte entsprechen denen aus unserem Standardisierungs-Flow. Wir beginnen mit dem Listen der Dateien im S3-Bucket mittels ListS3-Prozessor – dieses Mal für die STANDARDIZED-Ebene. Wie zuvor nutzen wir die integrierte Tracking-Funktion für eine inkrementelle Verarbeitung.
Anschließend weisen wir jedem Flow-File das Attribut ${S3OBJECT} zu. Dieser Wert entspricht der Zieltabelle in Snowflake und ist entscheidend für die dynamische Erstellung des späteren COPY INTO-Befehls.
Der FetchFilesFromS3Bucket-Prozessor lädt dann die standardisierten Dateien aus S3 und stellt sie für die weitere Verarbeitung bereit. Die Dateien werden an den PutSnowflakeInternalStageFile-Prozessor übergeben, der sie in eine interne Snowflake-Staging-Umgebung lädt. Durch die Konfiguration eines Präfixes wird ein strukturierter Staging-Pfad definiert, der jedem Objekt (z. B. CUSTOMER) einen eigenen Ordner zuweist – etwa:
@<database>.<schema>.<stage>/CUSTOMER
Im letzten Schritt verwenden wir den ExecuteSQL-Prozessor, um den COPY INTO-Befehl von Snowflake auszuführen. Dieser lädt die Parquet-Dateien aus der internen Stage in die passende Zieltabelle. Der Befehl wird dynamisch unter Verwendung der zuvor gesetzten ${S3OBJECT}-Variablen generiert.
Dank der Snowflake-Funktion MATCH_BY_COLUMN_NAME werden eingehende Daten automatisch den korrekten Spalten der Zieltabelle zugeordnet – individuelle INSERT-Befehle sind nicht nötig. Die Einstellung PURGE = TRUE sorgt zudem dafür, dass Dateien nach dem Laden automatisch wieder aus der internen Stage gelöscht werden.
Und damit ist es geschafft! Mit den logischen Schritten Extraktion, Standardisierung und Ingest haben wir eine durchgängige Pipeline geschaffen, die enorme Mengen kleiner Dateien aus externen Anwendungen bewältigt. Die Lösung wandelt diese in standardisierte, skalierbare und für Snowflake-optimierte Datenformate um – bereit für die anschließende Analyse.
COPY INTO <database>.<schema>.${S3OBJECT}
FROM @<database>.<schema>.<stage>/${S3OBJECT}
FILE_FORMAT = (FORMAT_NAME = 'RAW_DATA.FF_PARQUET')
PURGE = TRUE
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE ;
Fazit
In diesem Artikel haben wir gezeigt, wie Openflow eine reale Herausforderung bei der Datenintegration meistern kann: die Aufnahme und Verwaltung großer Mengen kleiner Dateien aus einer Kundenanwendung. Wir haben demonstriert, wie Openflow mit Anwendungen umgehen kann, die Daten ausschließlich über individuelle, ID-basierte API-Endpunkte bereitstellen – und dieses Szenario komplett innerhalb von Snowflake nachgebildet.
Zudem haben wir die Stärke von Openflow im schnellen Aufbau robuster Datenpipelines aufgezeigt, indem wir zwei praxisnahe Lösungen vorgestellt haben. Beide sind einfach umzusetzen, kommen ohne eigenes Scripting aus und sind hoch skalierbar – sodass das Setup in der eigenen Infrastruktur getestet und angepasst werden kann.
In der ersten Lösung haben wir Openflow mit Snowpipe Streaming genutzt, um eine nahezu Echtzeit-Datenaufnahme in Snowflake zu ermöglichen. Die zweite Lösung erzeugt eine Data-Lake Schicht unter Verwendung eines Blob Storage, in der Dateien standardisiert und konsolidiert werden, bevor sie per Batch nach Snowflake geladen werden. Diese Ansätze verdeutlichen die Flexibilität und Leistungsfähigkeit von Openflow, das den gesamten Prozess von der Datenextraktion bis zur effizienten Ingestion vereinfacht.
Kurz gesagt: Openflow vereint Datenintegration in einer einzigen, leistungsstarken Plattform.
Es bietet Erweiterbarkeit, Interoperabilität und unterstützt Verbindungen zu nahezu jeder Datenquelle oder jedem Zielsystem. Egal, ob du klassische ETL-Tools ersetzen oder moderne Pipelines für Snowflake gestalten möchtest – Openflow ist eine starke Alternative und mehr.
Es ist mehr als nur „NiFi as a Service“.
Openflow ist eine cloud-native Plattform mit elastischer Skalierung, integriertem Support für native und Snowflake-optimierte Konnektoren und der Fähigkeit, multimodale Daten zu verarbeiten. Openflow kann sogar Cortex AI-Services in Snowflake auslösen – ideal für datengetriebene KI-Anwendungen.
Wenn auch Du vor der Herausforderung stehst, Deine Datenintegration zu optimieren und so echten Mehrwert für Dein Unternehmen zu schaffen, unterstützen wir Dich gerne dabei. Kontaktiere uns für ein unverbindliches Erstgespräch, um Deinen individuellen Use Case zu besprechen.
Du hast Fragen? Kontaktiere uns
Your contact person
Helene Fuchs
Domain Lead Data Platform & Data Management
Your contact person
Pia Ehrnlechner
Domain Lead Data Platform & Data Management
Wer ist b.telligent?
b.telligent – das ist Data Analytics, AI, Customer Engagement und Data Visualisation. Das ist Deutschland, Österreich, die Schweiz und Rumänien. Doch das Entscheidende ist unser Team: Menschen mit echter Leidenschaft für Daten, die gemeinsam innovative Lösungen schaffen und Unternehmen nachhaltig voranbringen.
Wir zeigen auf, wie Du mit Snowflake Intelligence schneller an verwertbare Insights und Entscheidungen kommst. Und: Wie Du Use Cases realisierst und den ROI der Datenplattform steigerst: mit wenig Aufwand und ohne technisches Know-how.
Mit Openflow vereinfacht Snowflake die Datenintegration grundlegend: Extraktion und Laden erfolgen als Bestandteil der Snowflake Plattform – ganz ohne externe ETL-Tools. Damit sinkt der Integrationsaufwand deutlich, und das komplette Pipeline-Management wird erheblich schlanker und effizienter.
Exasol ist ein führender Hersteller von analytischen Datenbanksystemen. Das Kernprodukt ist eine auf In-Memory-Technologie basierende Software für die professionelle, parallele und schnelle Datenanalyse. Normalerweise werden SQL-Statements in einem SQL-Skript sequenziell abgearbeitet. Wie können aber mehrere Statements gleichzeitig ausgeführt werden? Dies zeigen wir anhand eines einfachen Skripts in diesem Blogbeitrag.