Text Embeddings and Vector Search: Optimizing Retrieval in RAG Systems
Laura Weber
Laura Weber
Consultant
Laura Weber is a consultant specializing in data science. Her quick perception has allowed her to apply her skills in various roles and in different industries. From data analysis, data engineering, data modeling, reporting to stakeholder communication and presentation, she masters a wide range of technical and methodological skills.
You’ve implemented RAG – but what comes next? Embeddings are the foundation of any RAG system. In this post, we’ll walk you through a CV matching use case to show how analyzing text embeddings can make vector search more effective — and retrieval in GenAI projects more accurate, explainable, and fair.
Table of Contents
RAG applications rely on text embeddings that capture the semantic meaning of text. We’ll show how to analyze these embeddings to better understand their content and how to optimize document retrieval in your RAG solution.
Retrieval Optimization: Taking RAG Systems to the Next Level
Retrieval-Augmented Generation (RAG) is at the heart of many GenAI projects today. A RAG application enriches a user’s query with relevant information from external sources — for example, internal documents. It does this by finding semantically similar text passages through a similarity search, then feeding those as context into the large language model (LLM).
This way, the LLM can use additional, domain-specific knowledge for its response rather than relying solely on its pre-trained data. Thanks to integrated services like Azure OpenAI and Azure AI Search, RAG applications can be implemented quickly and efficiently.
Understanding Embeddings Instead of Accepting a Black Box
The retrieval process — the “R” in RAG — is complex and often appears as a black box to most users. It’s difficult to assess why a document is considered “relevant” during retrieval. That’s because the matching doesn’t happen between the raw text and its words, but between their vectorized representations — the text embeddings.
What Exactly Is an Embedding?
An embedding is a numerical representation (a vector) of a text, generated by an embedding model. This vector encodes the semantic meaning of the text — typically across hundreds of dimensions. While each dimension carries information, none of them can be directly interpreted in isolation. (See also: Text Embeddings, Classification, and Semantic Search | Towards Data Science)
More Quality, Fairness, and Efficiency Through Embedding Analysis
Because embeddings form the foundation of RAG, taking a closer analytical look at them pays off. Understanding and optimizing retrieval increases answer quality, relevance, and fairness. It also reduces costs — fewer tokens are consumed, and fewer re-prompts are needed.
Additionally, it lowers risks such as biased outputs, wrong matches, and compliance issues.
The following steps are not just analytical exercises — they are practical levers applicable to use cases such as internal knowledge search, support ticket retrieval, contract analysis, or product documentation.
Use Case: Assisted Staffing Through Matching Job Descriptions and CVs
Let’s look at a practical example from daily staffing operations. To find out which consultants are the best fit for new projects, we analyzed the matching between job descriptions and CVs — specifically in the areas of Cloud/Data Platforms, Data Management, and Data Analytics/AI.
The goal: Identify CVs from a pool of about 120 resumes that best fit a given job based on project experience, technologies, and skills. The implementation used RAG with vector search (Cosine Similarity) via Azure OpenAI and Azure AI Search. The CVs came from both internal b.telligent consultants and external freelancers or partner firms.
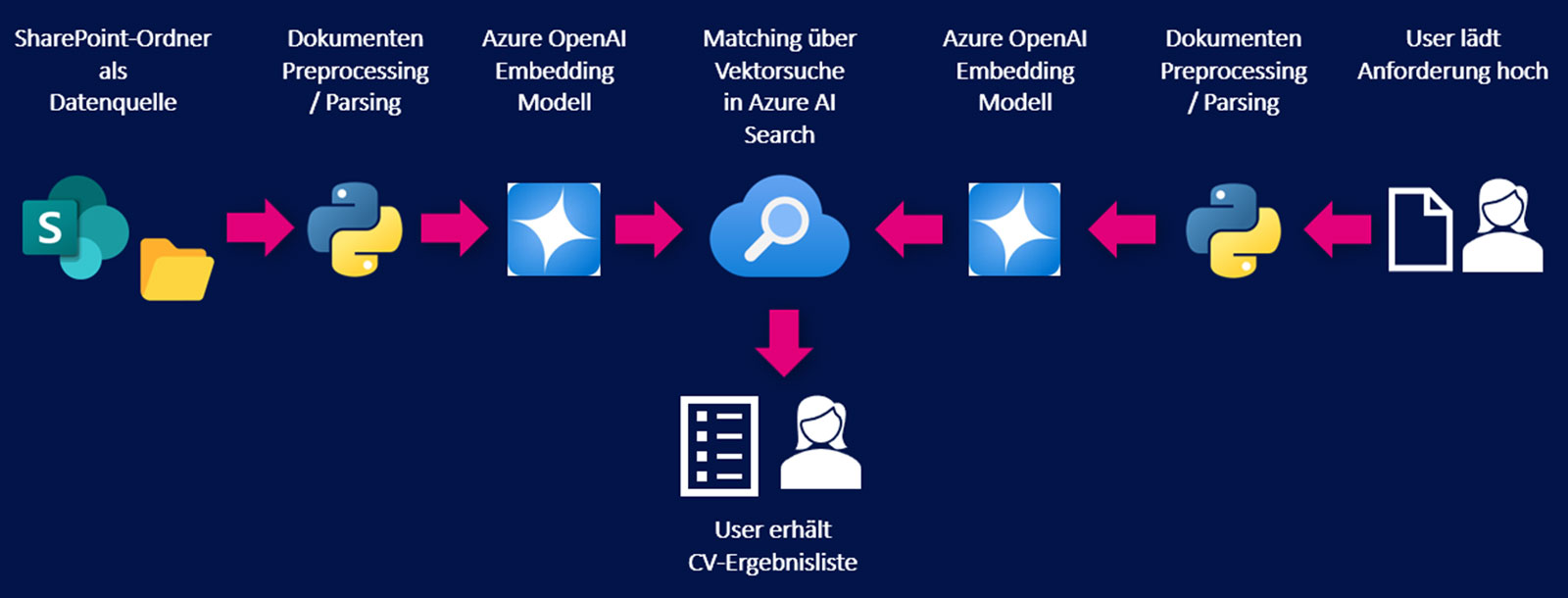
RAG architecture for matching job descriptions and CVs
The initial similarity search results from this RAG setup were promising but not perfect. Some top-ranked matches weren’t ideal, while better-suited CVs ranked lower. It was unclear which embedding features influenced the similarity score most strongly — meaning the matching process wasn’t yet controllable.
To uncover these factors, we used two analytical approaches:
Formulate hypotheses about what might be encoded in the embeddings and validate them.
Perform exploratory analysis through visualization to identify patterns.
Testing Hypotheses: What Factors Influence Matching?
AI use cases are not immune to context-specific influences that can be reflected in embeddings — and thus affect text matching. In our example, gender could be encoded through names or pronouns, potentially impacting ranking.
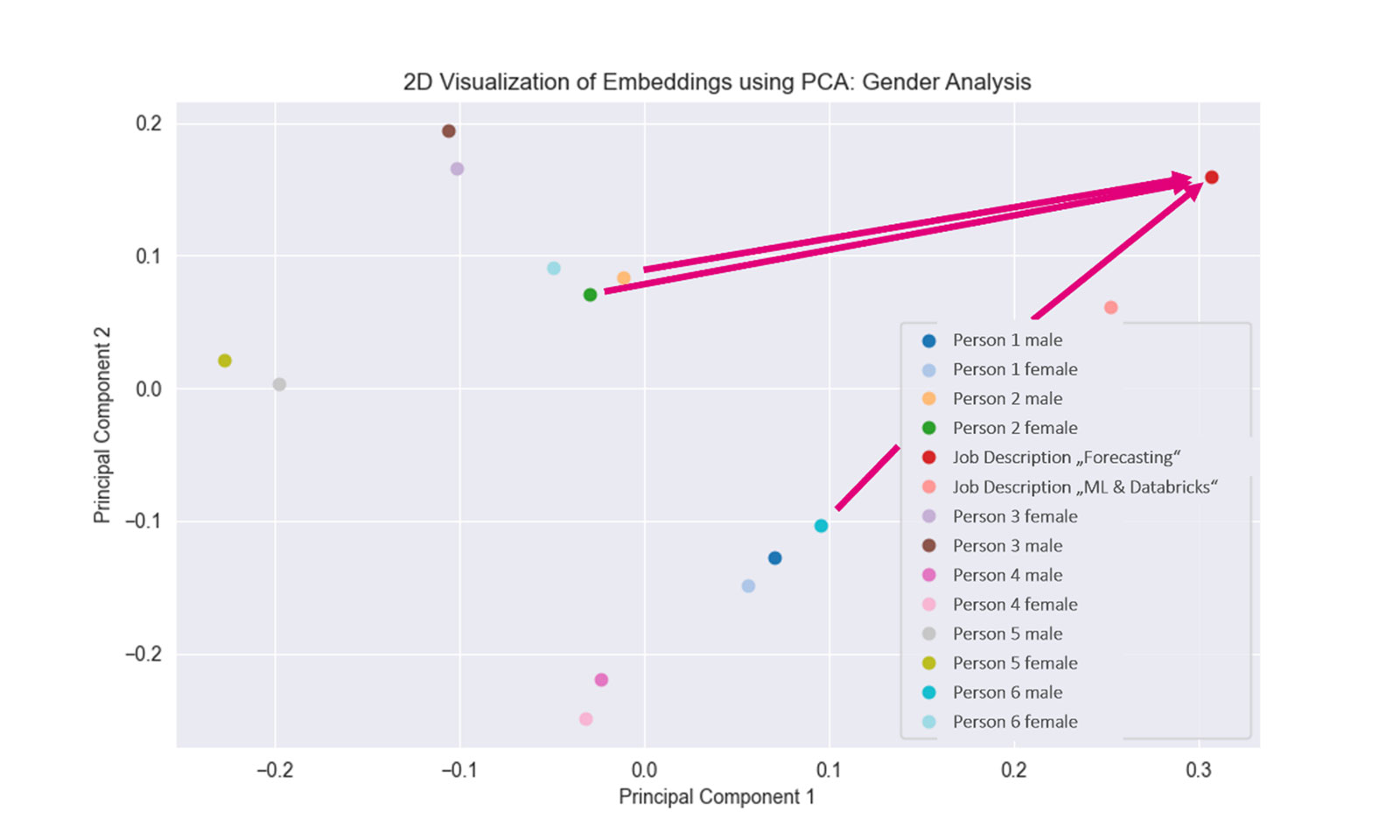
To test this, we created paired CV versions with identical content but gendered names and pronouns. Both versions were embedded as vectors and compared. The experiment showed that no single dimension carried “gender” information alone — differences spanned across nearly all dimensions.
This means embedding models distribute information across the entire vector space, not in isolated dimensions.
Fairness in Focus: How Bias Can Distort Matching
The hypothesis that “male” CVs would consistently achieve higher similarity scores was not confirmed. However, embeddings between male and female versions still differed, which could influence matching outcomes.
Takeaway:
Anonymizing CVs and using gender-neutral wording in both CVs and job descriptions can increase fairness and reduce bias risk.
The same applies to other markers such as age, ethnicity, political or cultural references, or other contextual signals — all of which can subtly skew semantic search results. This is crucial for developing fair and responsible AI applications.
This analytical approach can also be applied to other domains: for example, customer names in support data, company boilerplates in contract documents, or brand names in product tickets could unintentionally alter the ranking. The method remains the same: build counterfactuals, measure differences, derive measures.
Distance between the embeddings of male and female CV versions and the job description
Exploration: What Visualizations Reveal About Embeddings
Analyzing text embeddings is challenging due to their high dimensionality. Visualization helps make them interpretable.
We applied Principal Component Analysis (PCA) to reduce embeddings to two dimensions (Principal Components 1 and 2). PCA extracts the components with the greatest variance in the dataset, making structural patterns visible.
In general, PCA extracts the two components from the high-dimensional vector space for which a data set exhibits the greatest variance, thereby making structures visible.
The goal was to detect clusters (for example, thematic or technological groupings) that might reveal what content is encoded in the embeddings — and which factors drive matching.
The visualization primarily exposed structural rather than semantic clusters, caused by:
Empty or faulty content: A cluster of CVs contained only whitespace due to parsing errors.
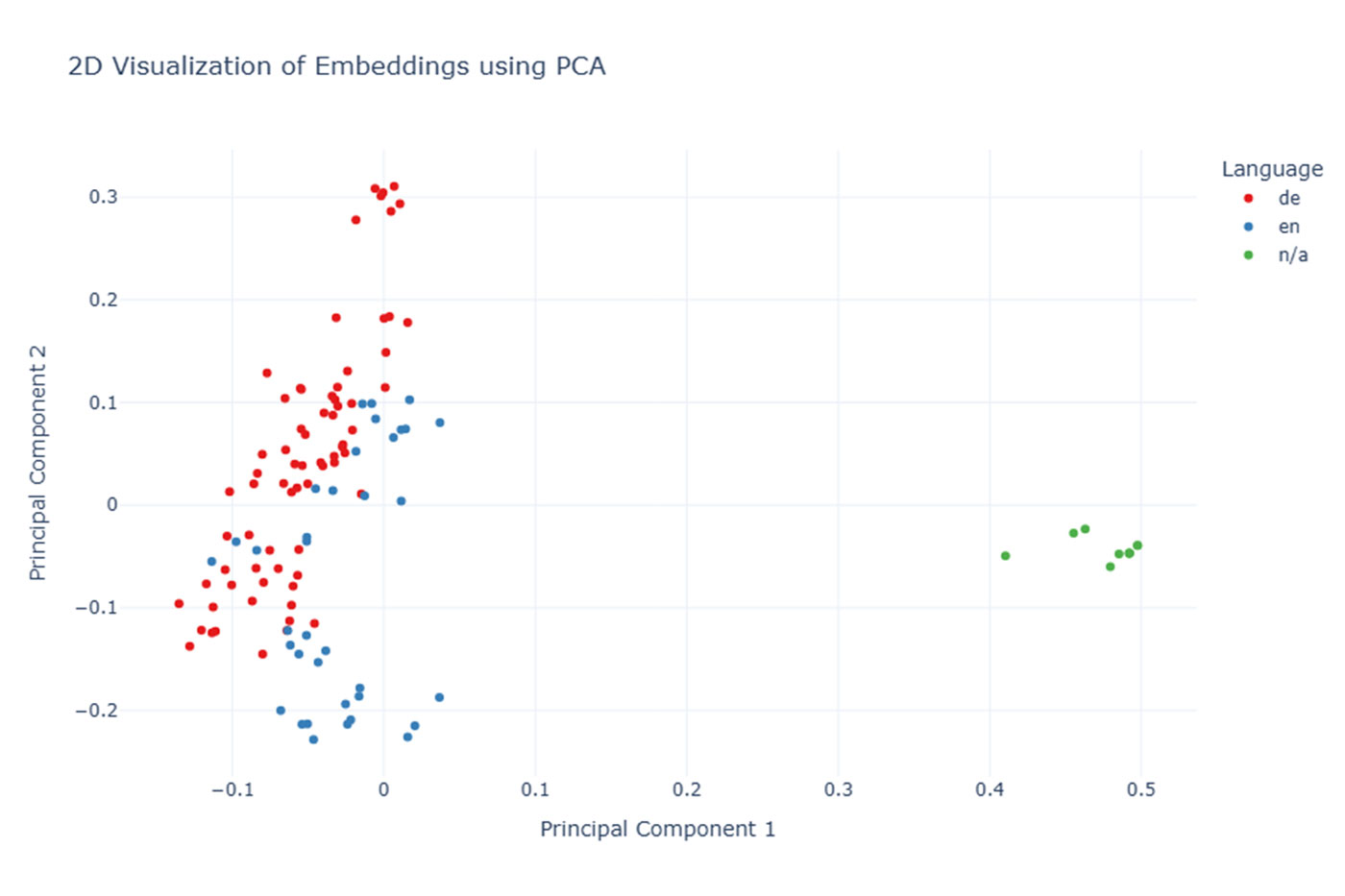
Language differences: CVs in different languages created systematic embedding divergences.
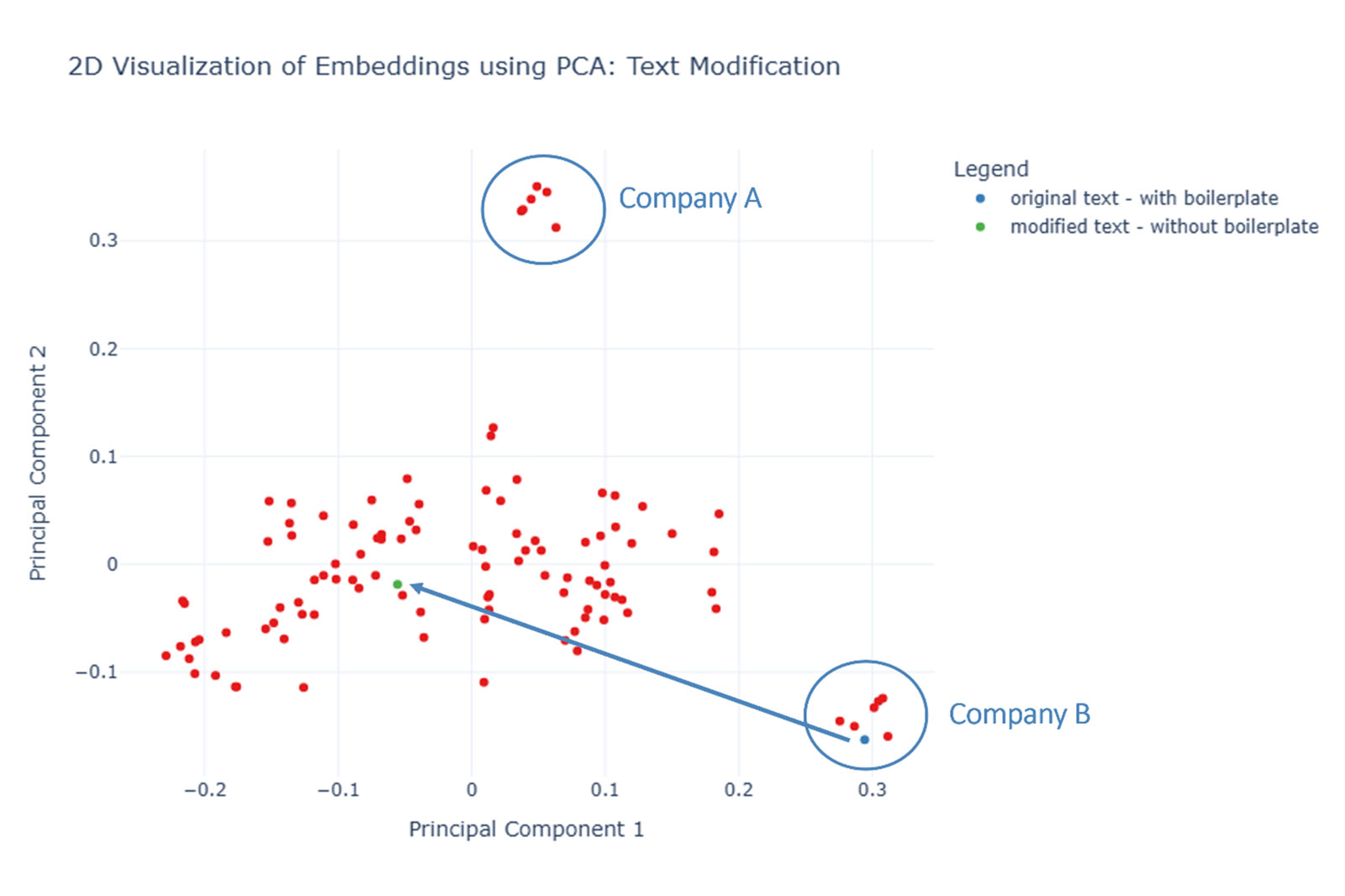
Company-specific text blocks: Repetitive corporate phrasing (e.g., in headers or footers) skewed embeddings disproportionately.
Grouping of CV embeddings by language
Visualization after excluding incorrectly imported CVs. Deleting company-specific text blocks eliminates structural deviations—the CV embedding from the company cluster (blue dot) moves toward the rest (green dot).
From Patterns to Actions: Insights from PCA
Structural effects influence similarity scoring — meaning CVs can be disadvantaged purely due to formatting, language, or boilerplate text. Faulty documents can’t match properly and won’t appear in retrieval.
Actions to improve matching:
Quality assurance during parsing: Validate extracted text after document processing.
Language standardization: Define a default language and translate both CVs and job descriptions.
Remove company-specific text irrelevant to the use case.
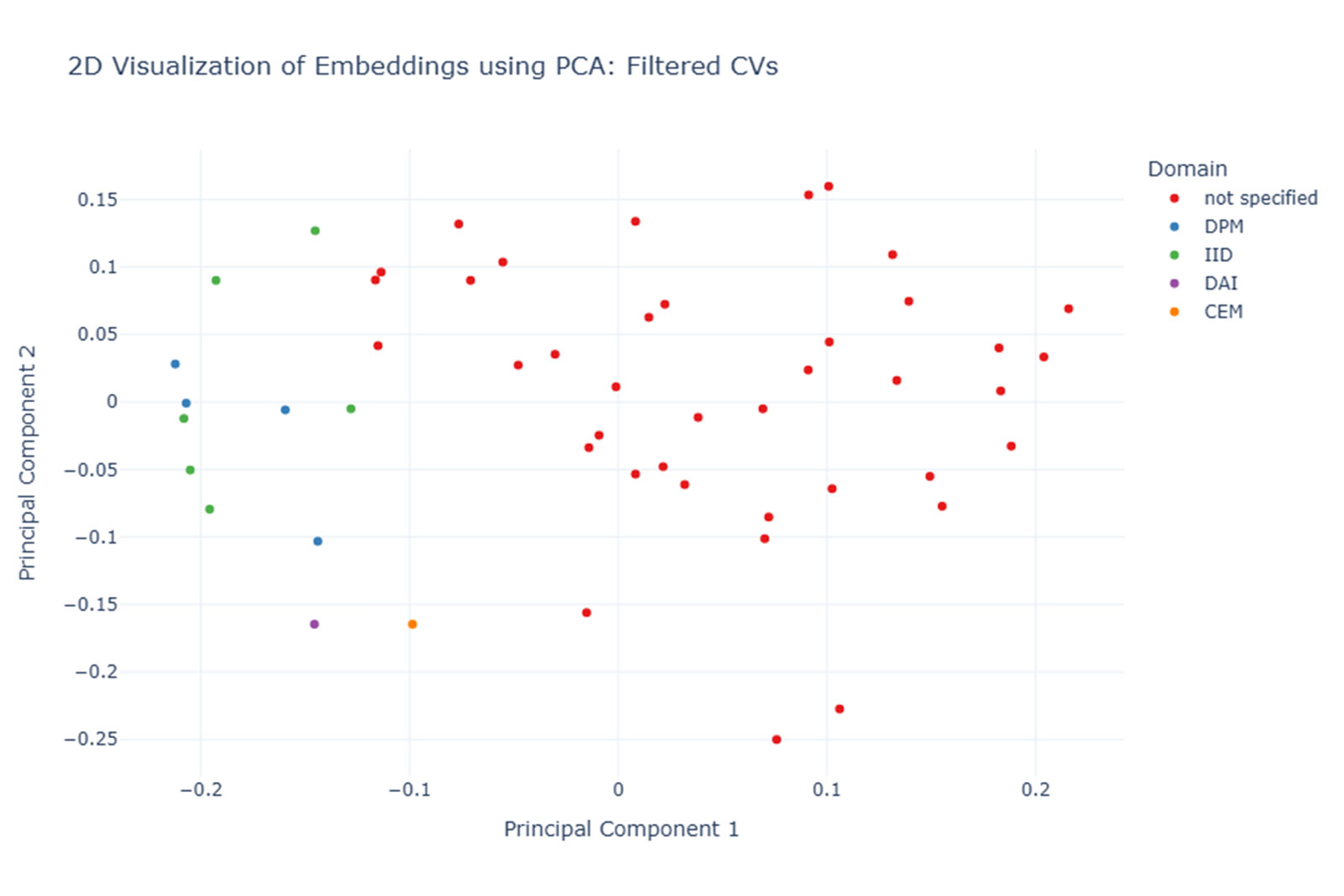
Now, the embeddings of the CVs with the identified anomalies are excluded, and a new PCA is performed. We now expect clearer semantic clusters in our 2D visualization.
The result has improved slightly, and although the embeddings are distributed across the entire PCA space, some groupings can be discerned. However, qualitative samples of the CVs show that semantically inexplicable embedding distances still exist, which is reflected in the search ranking.
Many CVs are long and contain numerous projects, technologies, and skills. The generically trained embedding model does not seem able to sufficiently capture fine, domain-specific differences across long texts. The small semantic nuances that are crucial for a good match between job requirements and a CV are not recognized. This is a pattern often found in retrieval scenarios where documents are too long, too heterogeneous, or too unique.
Visualization of CV embeddings colored according to b.telligent department and external CVs (red) shows no noticeable content clusters
Chunking as a Game-Changer for Precision
The solution: Chunking — splitting CVs into smaller, meaningful sections such as individual projects. Each section was re-embedded and visualized again via PCA.
This resulted in sharper, more meaningful clusters, with vector search producing more accurate matches. Shorter, focused text segments yield more distinct embeddings, making similarity search both more effective and more interpretable (“this matches because of Project X or Technology Y”).
The same applies to job descriptions: overly broad texts can dilute query embeddings. Focusing on must-have requirements improves precision and reduces manual post-processing.
Visualization of project embeddings shows clusters according to the applicant's field of expertise
Conclusion: From Black Box to Controllable Retrieval Engine
The analysis described has shown that there are pitfalls in using text embeddings in the retrieval process — but they can be uncovered. This means that concrete measures can be derived from the analysis to increase the precision of similarity search:
Data Quality: Parsing checks, language standards, filtering out standardized text blocks in documents
Fairness: Neutralization of context-specific influences
Chunking & Query Focus: Tailoring documents and user queries to essential units
Business Benefits: Reduced review effort for end users of the AI application, faster decisions due to fewer re-prompts
Governance & Trust: Explainable results, documented measures against bias
The insights gained from our analysis are based on the specific embedding model and the documents we processed. In your RAG application, a different embedding model may be used and different documents processed, each with its own challenges.
Nevertheless, with the approaches we have described, you can identify patterns and apply concrete levers to improve the quality of your RAG results:
Capture the baseline: Measure the current retrieval quality
Hypotheses & Tests: Create targeted text variants (counterfactuals) and measure the differences
Reduce the dimensionality of text embeddings and visualize them in 2D or 3D PCA space
Need support implementing or optimizing your RAG application?
We’d be happy to help — get in touch with us!
Want To Learn More? Contact Us!
Your contact person
Dr. Sebastian Petry
Domain Lead Data Science & AI
Who is b.telligent?
b.telligent – that’s Data Analytics, AI, Customer Engagement, and Data Visualization. It’s Germany, Austria, Switzerland, and Romania. But most importantly, it’s our team: people with a true passion for data, working together to create innovative solutions that drive sustainable progress for businesses.
In the age of agentic AI, retrieval quality often determines how reliably a system performs. Using an AI staffing use case, we show how retrieval can be meaningfully improved with late interaction retrieval, cross-encoders, and LLM-based approaches.
With Snowflake Document AI, information can be easily extracted from documents, such as invoices or handwritten documents, within the data platform. Document AI is straightforward and easy to use: either via a graphical user interface, via code in a pipeline or integrated into a Streamlit application. In this article, we explain the feature, describe how the integration into the platform works and present interesting application possibilities.
Neural Networks for Tabular Data: Ensemble Learning Without Trees
Neural networks are applied to just about any kind of data (images, audio, text, video, graphs, ...). Only with tabular data, tree-based ensembles like random forests and gradient boosted trees are still much more popular. If you want to replace these successful classics with neural networks, ensemble learning may still be a key idea. This blog post tells you why. It is complemented by a notebook in which you can follow the practical details.