







My last article showed how Vertex AI pipelines can be created. Now we'll deal a little more with the 'why?’ and discuss the potential benefits of pipelines.
High degree of automation
GCP offers many possibilities to start pipeline jobs automatically. Tools like Cloud Scheduler and Cloud Build make it easy to implement scenarios such as the following. For example, pipelines can be triggered if ...
- ...new data exist in a bucket.
- ...a data drift has been detected (current data no longer correspond to the distribution of the training data set).
- ...a cronjob becomes active (e.g. weekly trigger).
- ...code has been modified.
From execution on personal laptop to the cloud
Pipelines define not only what needs to be executed, but also where and how it should be executed. A finished pipeline configuration contains all the information about which code to run on which infrastructure.
The major advantage here is that code execution is not bound to a special PC with exactly the right configuration allowing all steps to run flawlessly. The pipeline can instead run in any clearly defined environment fully compliant with the pipeline's configuration.
This makes execution less susceptible to errors: The pipeline defines an exact infrastructure configuration, whereas on your own computer, new dependencies are constantly installed or old ones deleted, folders are renamed or environment variables are reset. So you switch from a multi-purpose infrastructure to one created only for pipeline execution.
Reproducibility and traceability
A very big advantage of Vertex AI pipelines is an ordered model training process. Not only are all trained models stored in the Vertex AI registry, they are also linked to all other artifacts involved in the pipeline's execution. This means that for each model version, I can determine which version of the data set was used for training, which hyper-parameters were used by definition, and which metrics were generated during validation. This is essential for retaining an overview given a variety of models and the need for regular training.
For implementation of this model versioning, Google uses the ML Metadata open-source project forming part of Tensor Flow Extended. A database abstracted from Vertex AI stores all artifacts and allows them to be linked and queried during joint pipeline execution.
Data can be queried from a browser or Python, for example.
One way of viewing from a browser is the lineage graph. The following sample diagram representing the pipeline from the last article shows that three different models have been trained on the basis of the same data set. Their inputs and metrics are also displayed interactively.
Alternatively, you can compare several runs directly in the browser and thus determine, for example, how a change in hyper-parameters has impacted a certain metric.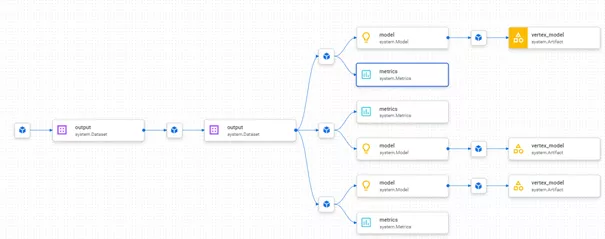
Here is a fine tutorial for those who want to learn more about metadata in pipelines.
Conclusion
Pipelines are a great way to structure and automate workflows. Vertex AI provides a metadata management system which is available without any setup requirements or other overhead.
Whether these advantages are ultimately worth the additional effort depends strongly on the project's complexity. If once-only training of a simple model is necessary, this is probably also manageable as a manual process. But if I have a project which requires regular model training, or I want to compare different variants of models or pre-processing steps, Vertex AI pipelines should definitely be considered.
Do you have problems training your models because this process is completely manual or requires a complex infrastructure setup? Have a look at the Vertex AI examples - maybe some will provide ideas on how to solve your problems with Vertex AI pipelines - or contact us directly.
Setup, training – and now structuring: Instead of copying code snippets from one project to another, use of Python packages is a good way to create order. The third part of this blog series shows the possibilities provided by GCP in this context.

