







In meinem letzten Beitrag haben wir gesehen, wie Vertex AI Pipelines erstellt werden können. Jetzt werden wir uns etwas mehr mit dem „Warum“ beschäftigen und die möglichen Vorteile durchsprechen, die Pipelines mit sich bringen.
Hoher Grad von Automatisierung
GCP bietet viele Möglichkeiten, Pipeline-Jobs automatisiert zu starten. Dank Tools wie Cloud Scheduler und Cloud Build sind Szenarien wie die folgenden einfach umzusetzen. So können Pipelines zum Beispiel getriggert werden, wenn …
- … neue Daten in einem Bucket vorhanden sind.
- … ein Datendrift festgestellt wurde (aktuelle Daten entsprechen nicht mehr der Verteilung des Trainingsdatensatzes).
- … ein Cronjob aktiv wird (z. B. wöchentlicher Trigger).
- … eine Änderung am Code durchgeführt wurde.
Von der Ausführung am eigenen Laptop in die Cloud
Durch Pipelines ist nicht nur definiert, was ausgeführt werden soll, sondern auch, wo und wie es ausgeführt werden soll. Eine fertige Pipeline-Konfiguration enthält sämtliche Informationen darüber, welcher Code auf welcher Infrastruktur auszuführen ist.
Das bringt den großen Vorteil, dass das Ausführen des Codes nicht an einen speziellen PC mit genau der richtigen Konfiguration gebunden ist, damit alle Schritte fehlerfrei laufen. Stattdessen kann die Pipeline in einer klar definierten Umgebung ablaufen, die exakt die Definition in der Pipeline-Konfiguration abbildet.
Das macht die Ausführung weniger anfällig für Fehler: Durch die Pipeline ist eine exakte Infrastrukturkonfiguration definiert, wogegen auf dem eigenen Rechner ständig neue Dependencies installiert oder alte gelöscht, Ordner umbenannt oder Environment-Variablen neu gesetzt werden. Man wechselt also von einer Mehrzweckinfrastruktur zu einer Infrastruktur, die nur für die Ausführung der Pipeline geschaffen worden ist.
Reproduzierbarkeit und Nachvollziehbarkeit
Ein sehr großer Vorteil von Vertex AI Pipelines ist, dass es Ordnung in den Modell-Trainingsvorgang bringt. Es sind nicht nur sämtliche trainierten Modelle in der Vertex AI Registry abgelegt, die Modelle sind auch mit sämtlichen anderen Artefakten des Pipeline-Laufs verknüpft. Das bedeutet, ich kann für jede Modellversion feststellen, mit welcher Version des Datensatzes sie trainiert wurde, welche Hyperparameter definiert und genutzt wurden und welche Metriken sie in der Validierung erzeugt hat. Das ist bei einer Vielzahl von Modellen und regelmäßigen Trainings von essenzieller Bedeutung, um nicht den Überblick zu verlieren.
Für die Umsetzung dieser Modellversionierung verwendet Google das Open-Source-Projekt ML Metadata, das bei TensorFlow Extended angesiedelt ist. Eine von Vertex AI wegabstrahierte Datenbank speichert alle Artefakte und macht sie durch einen gemeinsamen Pipelinelauf verknüpfbar und abfragbar.
Die Abfrage der Daten kann im Browser oder z. B. mit Python stattfinden.
Eine Möglichkeit zur Betrachtung im Browser ist der Lineage-Graph. Im folgenden Beispielbild, das zur Pipeline des letzten Artikels passt, ist zu erkennen, dass auf Basis desselben Datensatzes drei verschiedene Modelle trainiert wurden. Deren Input und Metriken sind ebenfalls interaktiv dargestellt.
Alternativ kann man auch direkt im Browser mehrere Läufe miteinander vergleichen und so z. B. feststellen, wie sich eine Änderung von Hyperparametern auf eine bestimmte Metrik ausgewirkt hat.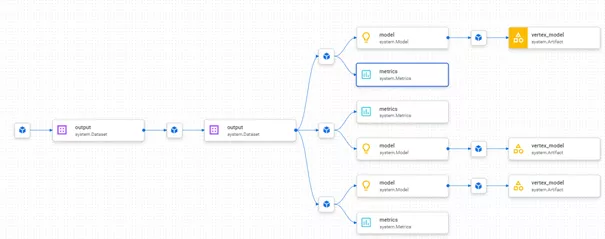
Wenn Du mehr zu Metadaten in Pipelines erfahren möchtest, gibt es dafür ein prima Tutorial.
Fazit
Pipelines bieten eine gute Möglichkeit, Workflows zu strukturieren und zu automatisieren. Durch Vertex AI wird ein Metadaten-Managementsystem zur Verfügung gestellt, das keinerlei Setup und Mehraufwand erfordert.
Ob diese Vorteile den Mehraufwand wert sind, hängt stark vom Komplexitätsgrad des Projekts ab. Wenn nur das einmalige Training eines einfachen Modells notwendig ist, ist das vermutlich auch als manueller Prozess handhabbar. Habe ich aber ein Projekt, das erfordert, dass ein Modell regelmäßig trainiert werden muss oder ich gezielt unterschiedliche Varianten von Modell oder Vorverarbeitung vergleichen will, sollten Vertex AI Pipelines definitiv in Betracht gezogen werden.
Hast Du Probleme mit dem Training Deiner Modelle, weil es ein komplett manueller Prozess ist oder ein kompliziertes Infrastruktur-Setup benötigt wird? Schau Dir doch mal die Vertex-AI-Beispiele an: Vielleicht sind Ideen dabei, wie Du Deine Probleme mit Vertex AI Pipelines lösen kannst; oder melde Dich direkt bei uns.
Aufsetzen, trainieren – und nun strukturieren: Anstatt Codeschnipsel von Projekt zu Projekt zu kopieren, bieten sich Python-Pakete an, um Ordnung zu schaffen. Was hier in der GCP möglich ist, erfährst Du im dritten Teil dieser Blogreihe.

