







After taking a trip into the world of Ray in the first article, we now want to dedicate ourselves to Vertex AI – the key area of all machine learning services in GCP. Pipelines are meant to make life in the machine learning world easier. They promise to shorten development cycles through a high degree of automation. In addition, infrastructure abstraction is meant to allow teams to dispense with expertise in microservices etc. and instead focus on core competencies.
In this blog post, we will look at a simple example of how a machine-learning pipeline can be set up in Vertex AI.
What are Vertex AI pipelines?
Compared to other cloud providers, Google has made a decision not to develop product-specific pipelines (such as AWS Sagemaker) but instead rely on the open-source technologies Kubeflow and Tensor Flow Extended (TFX) whose pipeline formats are supported.
We will focus on Kubeflow pipelines here. These consist of individual components linked by means of Python code. These components can be either ready-made containers or just Python functions – Kubeflow automatically runs the latter in a container environment without us having to write a Dockerfile.
Hands-on – Creating and executing a pipeline
In my opinion, the exact procedure of implementation can best be described with an example. The following code creates a pipeline which
- reads data from a source (for simplicity's sake, we'll just load a sample Sklearn data set here).
- trains a model and validates the results.
Reading data
Sample implementation for the first stage is as follows:
import kfp.v2.dsl, kfp.v2.compiler
from kfp.v2.dsl import Artifact, Dataset, Input, Metrics, Model, Output
@kfp.v2.dsl.component(base_image="python:3.9-slim", packages_to_install=["pandas", "sklearn"])
def data_source(output: Output[Dataset]):
import pandas as pd
import numpy as np
from sklearn.datasets import load_wine
X, y = load_wine(return_X_y=True)
data = pd.DataFrame(data=np.hstack([X, y.reshape([-1, 1])]))
data.to_csv(output.path, index=False, header=False)We will step individually through all the points of this function:
- Decorator: The decorator @component turns a normal Python function into a Kubeflow component. It essentially defines how the function should be executed in an environment furnished with containers. We have provided here as an example a standard Python image in which the packages Pandas and Sklearn are to be installed.
- Parameter: One has to grow accustomed to this Kubeflow feature. The function receives an 'Output' object as input. Instead of the function itself returning a value, the desired return value is stored in a path defined by the output object. The type-hint is not optional with Kubeflow – it is needed for Kubeflow to know what kind of artifact (dataset, model, metric ...) it needs to provide as input.
- Function: This is basically a normal Python function, but with two special features: Firstly, imports of Python packages must take place within the function. This makes the function self-sufficient and executable also subsequently inside a container without further information. The second special feature does not come from Kubeflow, but is specific to Vertex AI and not directly visible: The code line data.to_csv(...) stores the record in CSV format in a path defined by output.path. Though this works like a path in the local file system, it is actually a mounted cloud storage bucket.
Training the model
In the second function, a model is trained with the data set and then validated:
@kfp.v2.dsl.component(base_image="python:3.9-slim", packages_to_install=["pandas", "sklearn"])
def train_model(input: Input[Dataset], model: Output[Model], metrics: Output[Metrics]):
import pandas as pd
import pickle
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeRegressor
data = pd.read_csv(input.path, header=False)
features = list(data.columns)[0:-1]
target = list(data.columns)[-1]
x_train, x_test, y_train, y_test = train_test_split(data[features], data[target])
ml_model = DecisionTreeRegressor()
ml_model.fit(x_train, y_train)
with open(model.path, "wb") as f:
pickle.dump(ml_model, f)
accuracy = ml_model.score(x_test, y_test)
metrics.log_metric("accuracy", (accuracy * 100.0))
metrics.log_metric("framework", "Scikit Learn")The preceding function's output is defined here as an input. This indicates the path from which the data record can be read. In addition, two outputs are defined here – the trained model and its metrics describing the model. Metrics can be created as required. They work according to the key-value principle: For example, here we log a metric with the name 'framework' and the value 'Scikit Learn'.
Combining pipeline components
Now that we've defined both functions, we can link them in a pipeline:
@kfp.v2.dsl.pipeline(name="tree-pipeline")
def my_pipeline():
source_op = data_source()
train_model(source_op.outputs["output"])The decorator does not directly execute function code. Created instead are operators which can be linked.
Compiling and running the Pipline
The pipeline is ready. Now we can compile and upload it:
import os
from datetime import datetime
from pathlib import Path
from google.cloud import aiplatform
if __name__ == "__main__":
filename = str(Path(__file__).parent.joinpath("pipeline.json"))
kfp.v2.compiler.Compiler().compile(my_pipeline, filename)
run = aiplatform.PipelineJob(
project=os.environ['PROJECT_ID'],
location=os.environ['REGION'],
display_name="test-pipeline",
template_path=filename,
job_id=f"test-pipeline-{datetime.now().strftime('%Y-%m-%d-%H-%M-%S')}",
enable_caching=True,
pipeline_root=f"gs://{os.environ['BUCKET_ID']}",
parameter_values={},
)
run.submit(service_account=os.environ["SERVICE_ACCOUNT"])The compilation process converts our Python code into a JSON file. This file is then uploaded and executed.
Vertex AI makes it possible to monitor the pipeline and its current progress. The entire appearance is approximately as follows (the pipeline shown has two additional steps which I've omitted here for simplification):
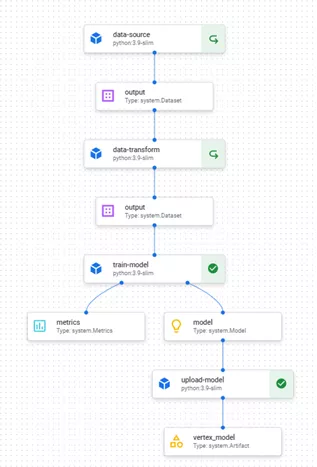
Conclusion
Vertex AI is still a very young product constantly being developed. I was all the more amazed at how easy it is to assemble pipelines which can perform different steps in clearly separated environments. Apart from a few Docker basics (for choosing and possibly creating a basic image), no infrastructure knowledge is necessary. It is also very convenient to be able to use cloud buckets like conventional volumes, without a need to specially write code for this.
All in all, we found that no great deal of effort is needed to convert classic Python functionality into Kubeflow components. In the next article, we'll take a closer look at the benefits of a Vertex AI pipeline.

