







In the first part of this blog series, we showed how lean SQL code can "distill" redundant versions of a historized table.
Unfortunately, the algorithm we used made certain demands of the data that cannot always be met in practice. This blog post explains how to make sure your implementation is successful.
Here is a more extended example incorporating the practice cases:
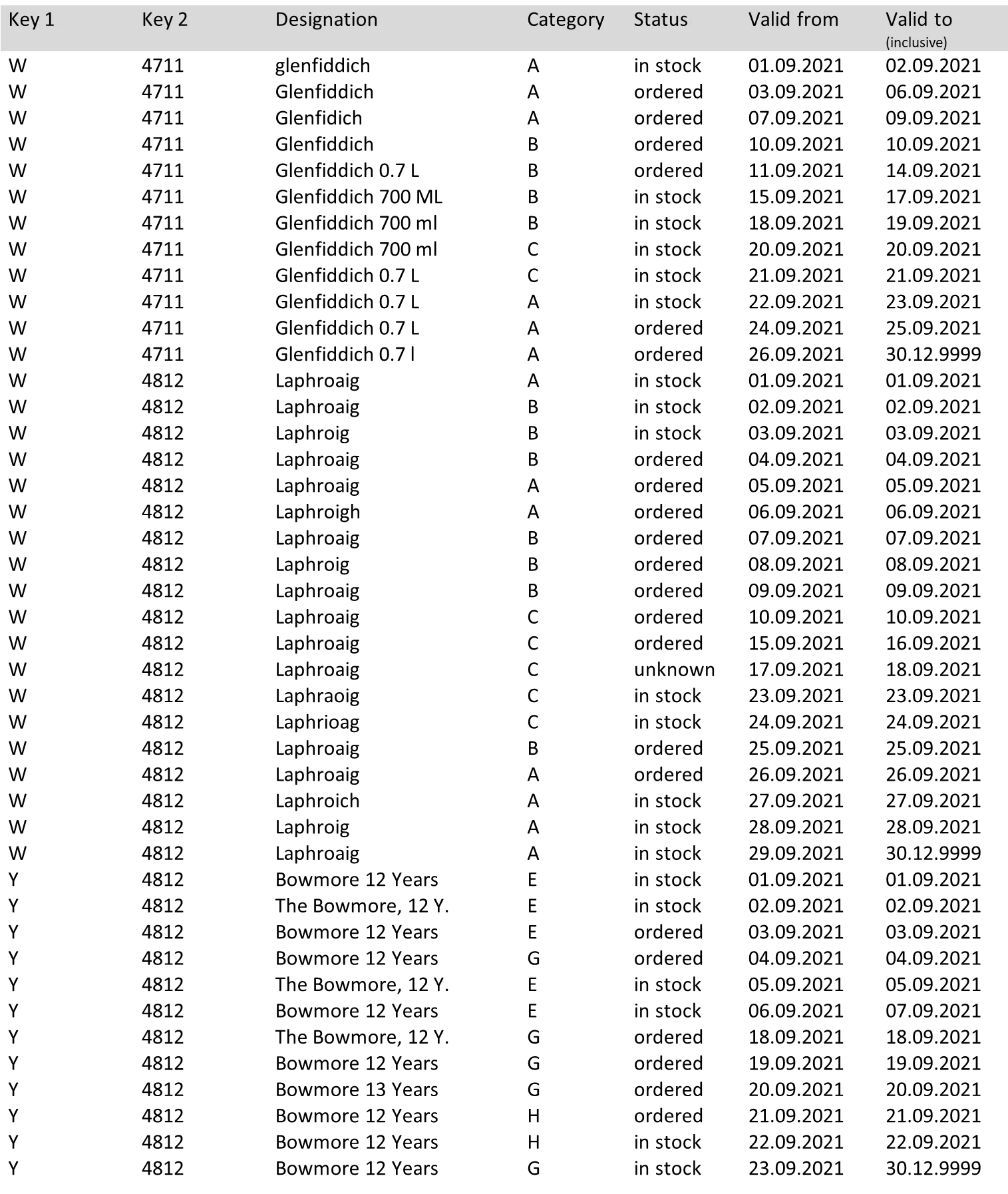
The following may deviate from the "ideal conditions", as you can see in our example:
Compound primary key
Here it is sufficient to insert all the key parts into the appropriate GROUP and PARTITION BY statements, as well as into the join condition. In the data vault, you can get around the problem right away by making use of surrogate keys.
Gaps in the history
The gaps in a history are either intentional or they are the result of errors either in the source system or the integration process. Irrespective of which it happens to be, these gaps are temporarily closed during the distillation process by "ghost records" which are removed at the end of the process.
Valid-from and valid-to dates are not identical
In some environments, the valid-to date of the previous version does not match the valid-from date of the successor, without a gap being stated, e.g.:
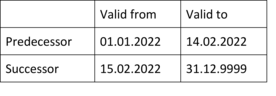
Here it usually helps if you increase the valid-to date by the appropriate unit (here: one second, in the code example: one day). Make sure that the end date does not overflow beyond the year 9999.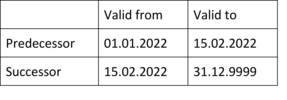
Depending on the content required after distillation, the increment at the end can be deducted from the valid-to date.
No reliable dummy value
In the first version, we added a dummy value to the attribute to tag the rows. However, there is always some likelihood of this value occurring in the data itself. We therefore added the column "flag" in the intermediate steps, which is set to "-" by default and may contain the values "PREV-DUMMY", "GAP_GHOST", "UNCHANGED" and "END-DUMMY".
Several relevant attributes
Normally, it is not just the changes to a single attribute that are relevant for versioning. In our example, versioning is carried out by category and status; the designation is of no interest. By introducing the hashdiff column as the hash value (MD5 in this instance) of all the relevant concatenated attributes, you do away with the need for the AND-linked query, as can be seen in the following pattern: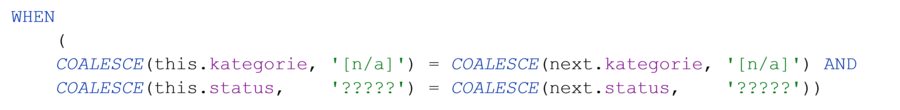
The necessary NULL substitution would, however, bring back the unreliable dummy value problem. Without COALESCE() the comparison becomes even more complex. The reader is welcome to try it.
On the other hand, you can simply compare the hashdiff with EQUAL TO. The attribute itself must be carried over.
The solution
The solution once again is a query, which consists of a series of five common table expressions (CTE) that build on each other, plus the final query.
First, in CTE 1
- The valid-to date is increased by one day to obtain the exclusive view
- The subsequent valid-from date is determined to identify the gaps
- Previous dummies are placed in front of the first version and flagged as "PREV-DUMMY"-.
CTE 2 is now added. Here, ghost records are added to CTE 1 for the gaps that have been identified and these are tagged with the flag "GAP-GHOST".

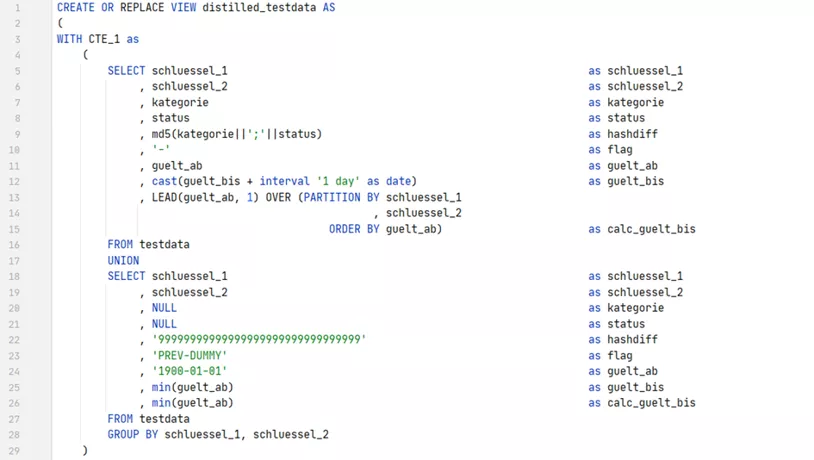
Now the logic, which was not easy to understand in the first part, is repeated. In CTE 3, all predecessors and successors from CTE 2 are concatenated by the self-join. The attributes of the successor are used, with only the valid-from and maximum valid-to dates determined by the predecessor. If the hashdiff hasn't changed, the row (the successor) is marked as "UNCHANGED".
Since the "PREV-DUMMY" also contains a dummy hashdiff, the first version has changed in each case. If the successor flag is left empty by the left join, it means there was no successor, and the line is flagged as "END-DUMMY".
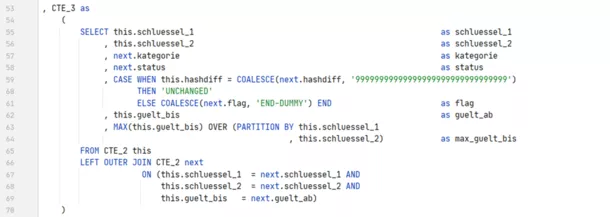
CTE 4 removes all unaltered successor lines from the result of CTE 3. The reason for their removal is that the PARTITION-BY operation does not exclude these lines.

For the same reason, the new valid-to date (in the exclusive view) must also be determined separately in CTE 5.
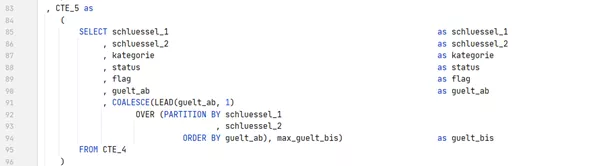
For the final result, the only problem that remains is the dummies for the beginning and end, and the ghost records for the gaps. These disappear if you leave only the lines without a flag at the end:

Ignoring the additional attributes and keys, the code now has twice the number of lines compared to the first solution. A modest effort that has enabled us to fill our whisky into rather lean bottles.
In the end, only these 26 lines remain:
Practical performance test with a specific use case
The situation: a view with nearly 600 lines of SQL code, the results of which have become rather large due to several self-references. This view is part of an entire chain. Any reduction in the amount of data will therefore also affect subsequent views.
The first three conditions (no gaps, primary key, valid-to date) were already met, showing that in practice not all of these scenarios have to occur together. Implementation can be reduced to four intermediate steps.
The environment was a Hadoop/Hive database running on Spark SQL (livy interpreter) in a Zeppelin notebook.
The customer has chosen to use the algorithm as the default in their business vault views whenever possible.
Conclusion
The solution shows how the five most common problem cases in data distillation can be addressed without too much effort. But is the effort always worth it? In the first part, we managed to reduce the amount of data to a third; now, almost two thirds remain. Is our new whisky not that high proof?
Versions are the result of the changes to individual attributes. The more attributes the result contains, the higher the number of versions. The fewer the attributes relevant to the use case, the higher the distillation potential.
The real benefit usually becomes apparent during further processing. It makes a difference to customers whether the subsequent data integration steps are performed with 12 or with 4 million rows.

