







Have you ever stumbled across the following problem? Your database contains a table of versions, and you happen to notice there are almost no relevant changes from one version to the next, which means you have way too many rows. Let’s show you how to easily solve this problem.
To better understand the issue, we’ll start with an appropriate example: a set of base product data on a particular whisky:
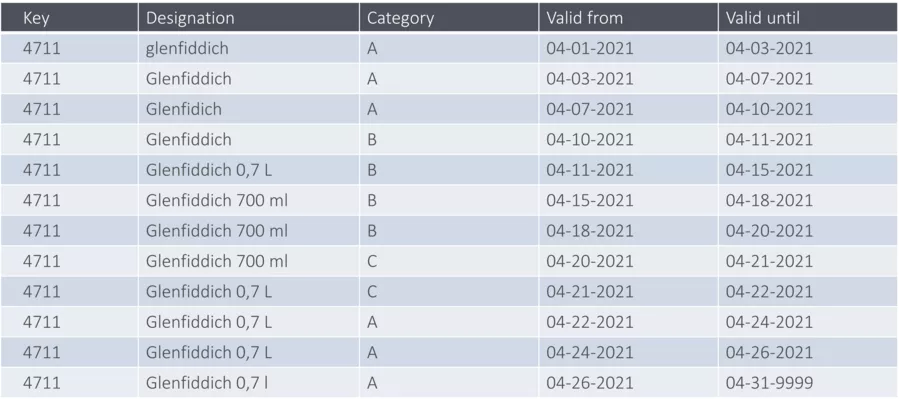
People often tweak the name of a whisky, but that doesn’t interest us. We only want to distill the change in a category by its respective validity date:

You can immediately see – we’ve cut the volume of data significantly.
Coalesce time slices: what’s really needed?
Basically, we can run into this problem in many situations concerning a temporal database: for example, when only certain attributes from a source are needed in a typical data warehouse.
In dealing with a data vault, you may prefer to outsource more volatile attributes to your own satellites, but the source systems cannot be versioned at the column level.
Upon transitioning to a data mart, JOIN can create a multitude of tiny time slices that are undesirable for some dimensions. One can generate many superfluous rows when transposing (unpivoting) from columns to rows.
Is it a real problem or just better performance?
The key point is: it really doesn‘t matter, if you have too many versions for an attribute value. However, this distillation approach will not only save you storage space, it will also boost performance since it processes less data.
If you pose the question for our initial example, “Since when is a product assigned to a specific category,” you’ll clearly see the technical reasons for distilling such versions.
Product lifecycle grouping – that alone does not cut it!
Applying GROUP BY for grouping is actually the first idea that comes to mind. But that would require the attribute values to never revert back to prior values. If that’s the way things work in practice (e.g., a fixed order of values in a lifecycle), the solution naturally becomes trivial. In most cases, though, things are different.
On the contrary, it is not really unusual that columns flicker back and forth between few values. In the example, category A was valid in two time periods.
Many names for many solutions
Online, you’ll find a few code snippets with extremely different descriptions for this issue, like redundant or obsolete versions, or condensing, consolidating, densifying, duplication/doublets in versions or historical data.
In fact, our goal here is to not just coalesce the data somehow, but more so to extract the essence of true relevance from a technical standpoint. That’s why I call this distillation.
Applying standard SQL makes the solution quite generic, since the problem is right in the database.
High-proof distillation – an absolutely brilliant move with SQL!
Let’s start by looking at where we are with the following attributes at hand:
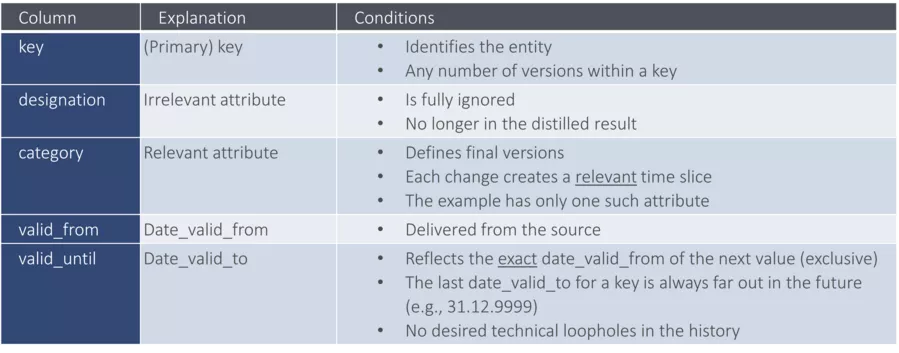
The solution itself comprises just three CTEs (common table expressions), that build on each other respectively and are numbered consecutively. The final result is computed after the fourth query and presented as the distillery_algo view.
CTE1 first generates a virtual previous value for each key and with UNION attaches it to the table. This is the very first version that was always valid (in this case 01.01.1900), and the first version of the key is actually valid up to the date_valid_from. A dummy value is set for the relevant attribute (category), which could not occur otherwise.

CTE2 is not complicated, but possibly a bit confusing: CTE1 is joined to itself via a key and validity date, such that each row finds its next direct value. Now you can see why the date_valid_from and date_valid_to must correspond precisely.
We rename the relevant attribute (category) versions: the current value (this) is defined as the previous value (prev_val), the next value (next) is set to the current value (this_val).
The current date_valid_to becomes the new date_valid_from; this way, the last version in time gets a virtual next value. Since this end dummy at LEFT JOIN hasn’t found any partner, the relevant attribute is replaced through the same dummy value at the beginning.
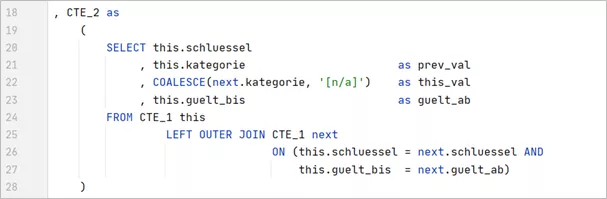
Perhaps the next steps will help you better follow the why and what for:
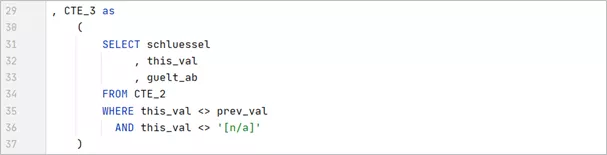
After this shift, in CTE3 we simply leave those rows unchanged in which the relevant attribute has changed (this_val <> prev_val), and where it so far does not concern the end dummy. For this, however, the start dummy remains (dummy value in prev_val).
For the final result, the Windows function LEAD() is applied to determine the date_valid_to from the date_valid_from of the next value, and this_val gets back the name of the relevant attribute (category). For the last version within the key, we set the final end date (e.g., 31.12.9999).
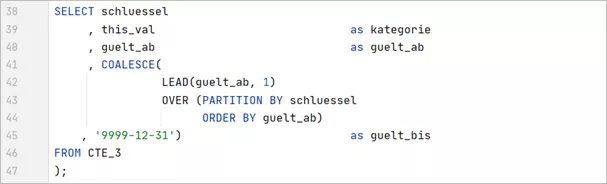
Fantastic! We’ve managed to distill an extremely smooth single malt whisky from the formerly changeable dates!
Conclusion
We can undoubtedly use SQL and a single query to solve the issue of distilling relevant versions from the history within the scope of a temporal database. The above algorithm, nevertheless, requires specific characteristics in the data, which may not always be met in practice. You should definitely check that out first.
Sound a bit like your very own moonshine? Don’t worry. In my next blog, I’ll delve into solutions for data that do not meet these requirements. Make sure to not miss it!