







Im ersten Teil dieser Blogreihe, haben wir gezeigt, wie man mit schlankem SQL-Code redundante Versionen einer historisierten Tabelle „wegdestillieren“ kann.
Der dort vorgestellte Algorithmus stellte jedoch gewisse Anforderungen an die Daten, die in der Praxis nicht immer praktikabel sind. Wie die Umsetzung gelingt, wird im Folgenden gezeigt.
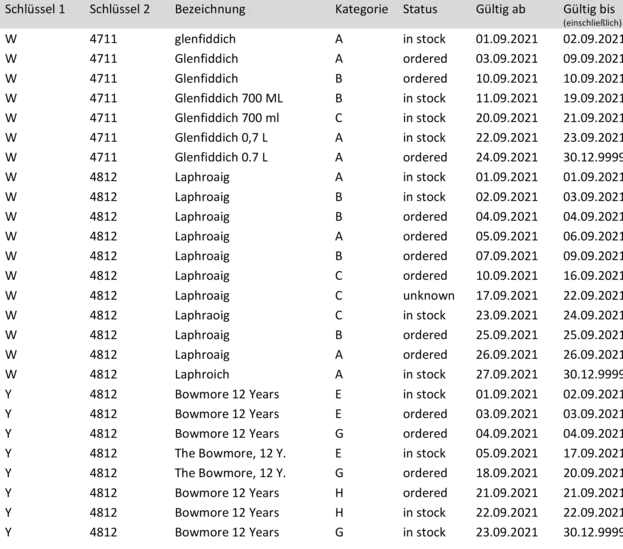
Hier ein erweitertes Beispiel, in das die Praxisfälle eingebaut wurden:
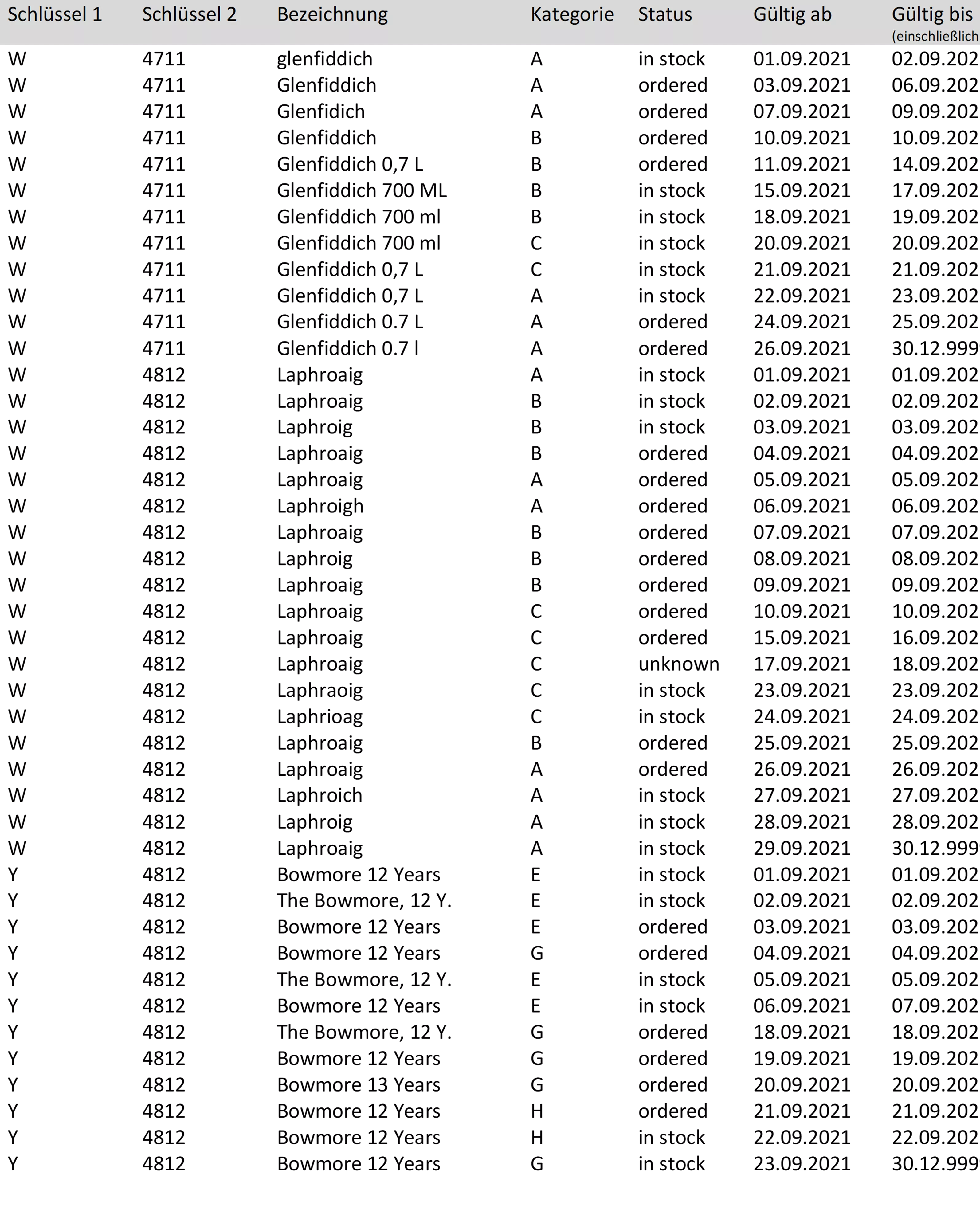
Folgendes kann von den „Idealbedingungen“ abweichen, wie im Beispiel zu sehen ist:
Zusammengesetzter Primärschlüssel
Hier ist es ausreichend, alle Schlüssel-Teile in die entsprechenden GROUP- und PARTITION BY-Statements, sowie in die Join-Bedingung einzufügen. In Data Vault umgeht man das Problem gleich durch die Einführung von Surrogate-Keys.
Lücken in der Historie
Entweder sind die Lücken in einer Historie gewollt, oder sie resultieren aus Fehlern im Quellsystem oder dem Integrationsprozess. Unabhängig davon bedeutet das für den Destillationsprozess, dass diese Lücken durch „Ghost-Records“ temporär geschlossen und diese Lückenfüller zum Schluss wieder entfernt werden.
Gültig-ab- und Gültig-bis-Datum sind nicht identisch
In manchen Umgebungen entspricht das Gültig-bis-Datum der Vorgängerversion nicht dem Gültig-ab-Datum des Nachfolgers, ohne dass damit eine Lücke ausgedrückt werden soll, z. B.: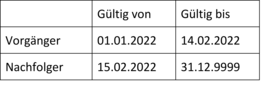
Hier hilft es, das Gültig-bis-Datum generell um die entsprechende Einheit (hier: eine Sekunde, im Code-Beispiel: ein Tag) zu erhöhen. Beim Ende-Datum ist darauf zu achten, dass es nicht zum Überlauf über das Jahr 9999 kommt.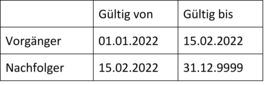
Abhängig vom gewünschten Inhalt nach der Destillation kann das Inkrement am Ende wieder vom Gültig-bis-Datum abgezogen werden.
Kein sicherer Dummy-Wert
In der ersten Fassung wurde zum Markieren der Zeilen ein Dummy-Wert in das Attribut geschrieben. Es kann nicht immer ausgeschlossen werden, dass dieser Wert in den Daten selbst vorkommt. Deshalb wurde für die Zwischenschritte die Spalte „flag“ eingeführt, die standardmäßig mit „-“ vorbesetzt wird und die Werte „PREV-DUMMY“, „GAP_GHOST“, „UNCHANGED“ und „END-DUMMY“ erhalten kann.
Mehrere relevante Attribute
Meistens sind nicht nur die Änderungen eines einzelnen Attributs für die Versionierung relevant. Im Beispiel wird nach Kategorie und Status versioniert, die Bezeichnung ist uninteressant. Mit der Einführung der Spalte hashdiff als Hashwert (hier MD5) aller konkatenierten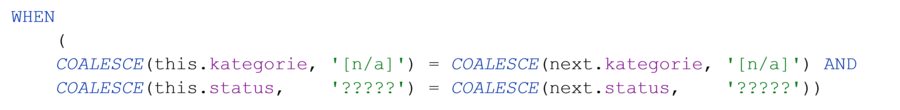
Durch die notwendige NULL-Ersetzung würde aber das Problem des unsicheren Dummy-Wertes zurückkommen. Ohne COALESCE() wird der Vergleich noch aufwendiger. Der/Die Leser:in kann es gerne probieren.
Den hashdiff dagegen kann man einfach mit GLEICH vergleichen. Die Attribute selbst müssen mitgenommen werden.
Die Lösung
Die Lösung besteht erneut aus einer Query, die aus insgesamt fünf aufeinander aufbauenden Common Table Expressions (CTE) und der finalen Abfrage besteht.
In CTE 1 wird zunächst
- Das Gültig-bis-Datum um einen Tag erhöht, um die exklusive Sicht zu erhalten
- Das nachfolgende Gültig-ab-Datum ermittelt, um die Lücken zu erkennen
- Vorgänger-Dummies vor die jeweils erste Version gesetzt und mit dem Flag „PREV-DUMMY“ versehen-
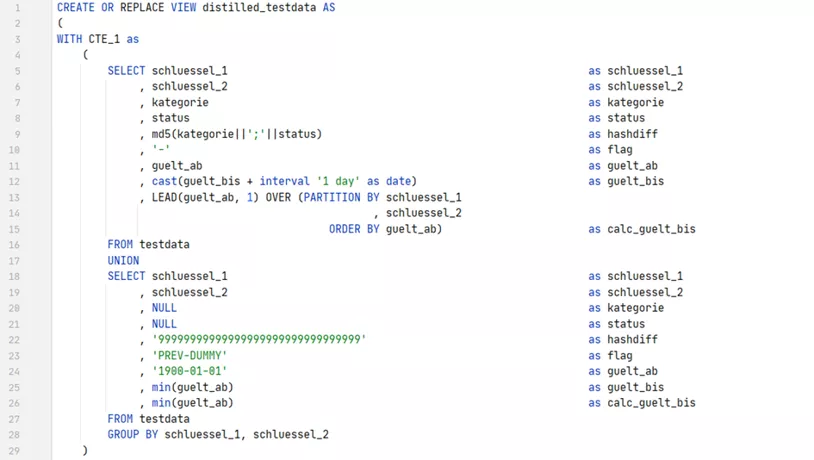
CTE 2 kommt neu dazu: Hier werden zur CTE 1 Ghost-Records für die identifizierten Lücken hinzugefügt und mit dem Flag „GAP-GHOST“ gekennzeichnet.

Jetzt wiederholt sich die Logik, die bereits im ersten Teil nicht einfach zu verstehen war. In CTE 3 werden alle Vorgänger und Nachfolger aus CTE 2 durch den Selbst-Join verkettet. Als Attribute werden die des Nachfolgers verwendet, lediglich Gültig-ab- und maximales Gültig-bis-Datum werden aus dem Vorgänger ermittelt. Hat sich der Hashdiff nicht verändert, wird die Zeile (der Nachfolger) als „UNCHANGED“ markiert.
Da der „PREV-DUMMY“ auch einen Dummy-Hashdiff enthält, hat sich die jeweils erste Version geändert. Ist das Flag des Nachfolgers durch den Left Join leer geblieben, gab es keinen Nachfolger, und die Zeile bekommt das Flag „END-DUMMY“.
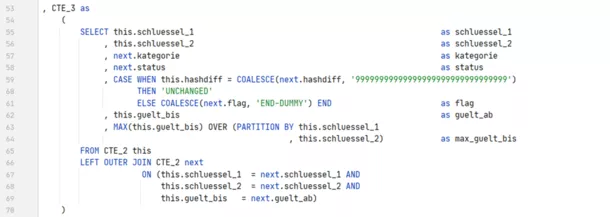
CTE 4 entfernt alle unveränderten Nachfolger-Zeilen aus dem Ergebnis von CTE 3. Grund für die Auslagerung ist auch hier die PARTITION-BY-Operation, die diese Zeilen nicht ausschließt.

Aus dem gleichen Grund muss auch das neue Gültig-bis-Datum (in der exklusiven Sicht) separat in der CTE 5 ermittelt werden.
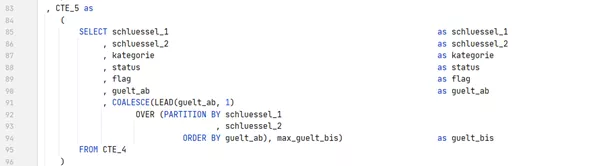
Für das Endergebnis stören nur noch die Dummies für Anfang und Ende, sowie Ghost-Records für die Lücken. Diese verschwinden, wenn man am Ende nur die Zeilen ohne Flag übrig lässt:

Abgesehen von den zusätzlichen Attributen und Schlüsseln, hat sich der Code im Vergleich zur ersten Lösung zeilenmäßig gerade einmal verdoppelt. Ein maßvoller Aufwand, mit dem wir unseren Whisky nun in ziemlich schlanke Flaschen abgefüllt haben.
Am Ende bleiben nun diese 26 Zeilen übrig:
Praxistest zur Performance in einem konkreten Anwendungsfall:
Ausgangslage: Eine View mit fast 600 Zeilen SQL-Code, deren Ergebnis durch mehrere Selbstreferenzen ziemlich groß geworden ist. Diese View ist Teil einer ganzen Kette, dadurch wirkt sich die Reduzierung der Datenmenge auch auf die nachfolgenden Views aus.
Die ersten drei Bedingungen (keine Lücken, Primärschlüssel, Gültig-Bis-Datum) waren bereits erfüllt und zeigen, dass in der Praxis nicht alle dieser Fälle zusammen auftreten müssen. Die Implementierung kann auf vier Zwischenschritte reduziert werden.
Bei der Umgebung handelte es sich um eine Hadoop/Hive-Datenbank, die Ausführung erfolgte mit Spark SQL (livy-Interpreter) in einem Zeppelin-Notebook.
Der Kunde hat sich dazu entschieden, den Algorithmus als Standard in seine Business Vault-Views aufzunehmen, wann immer Potential vorhanden ist.
Fazit
Die Lösung zeigt, wie den fünf häufigsten Problemfällen bei der Daten-Destillation ohne unverhältnismäßigen Aufwand begegnet werden kann. Doch lohnt sich dieser Aufwand immer? Im ersten Teil hatten wir die Datenmenge noch auf ein Drittel reduziert, jetzt bleiben noch fast zwei Drittel übrig. Ist unser neuer Whisky gar nicht so hochprozentig?
Versionen sind das Ergebnis der Änderungen einzelner Attribute. Je mehr Attribute das Ergebnis enthält, desto höher die Zahl der Versionen. Je weniger Attribute für den Anwendungsfall relevant sind, umso höher ist das Potential der Destillation.
Der eigentliche Vorteil zeigt sich meist in der Weiterverarbeitung. Für die Kunden macht es einen Unterschied, ob die nachfolgenden Schritte in der Datenintegration mit 12 oder 4 Millionen Zeilen durchgeführt werden.

