







In our free series of online events under the banner of Data Firework Days, we introduced you to the b.telligent reference architecture for cloud data platforms. Now we'd like to use this blog series to take a closer look at the subject of the cloud and the individual providers of cloud services. In the first of this three-part series Blueprint: Cloud Data Platform Architecture, we were interested in the architecture of cloud platforms in general.
Read part 1 here: Blueprint: Cloud Data Platform Architecture
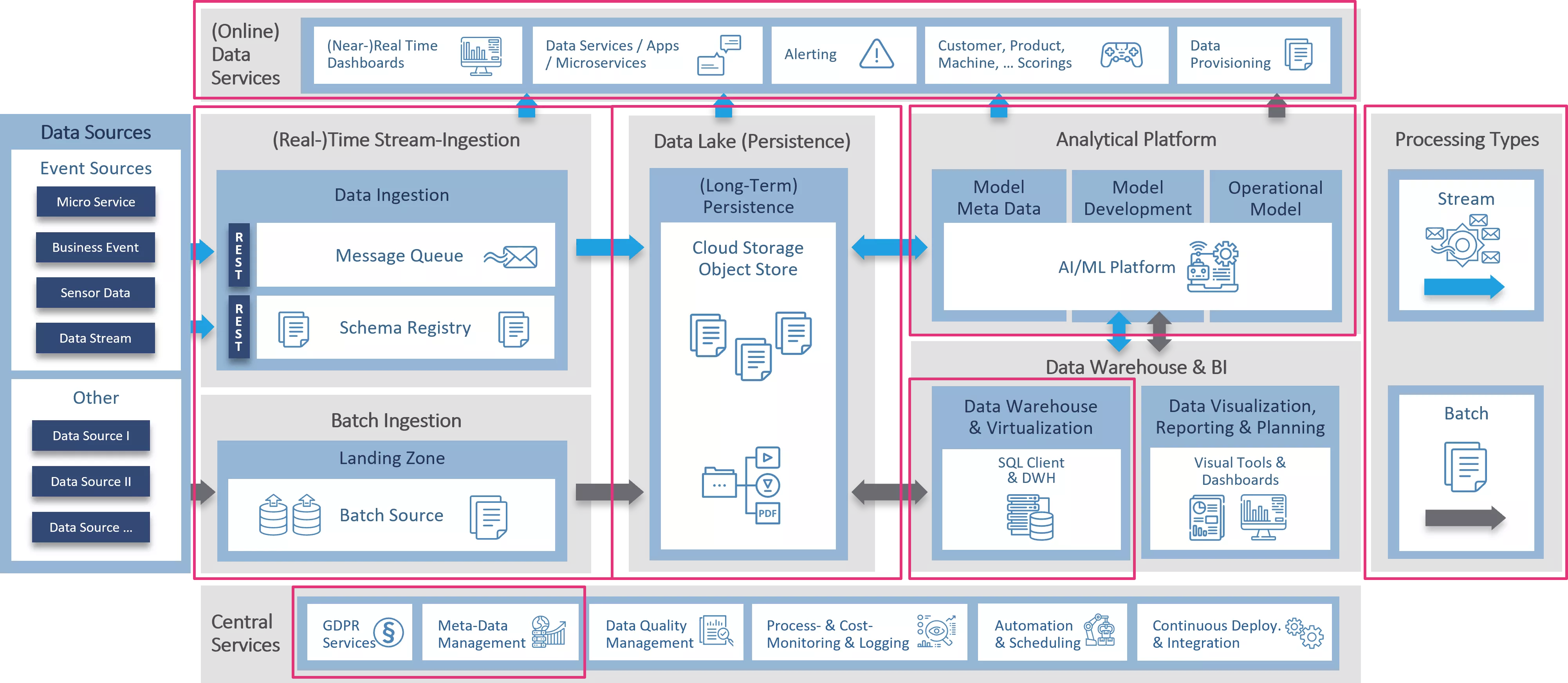
Cloud data platform architecture?
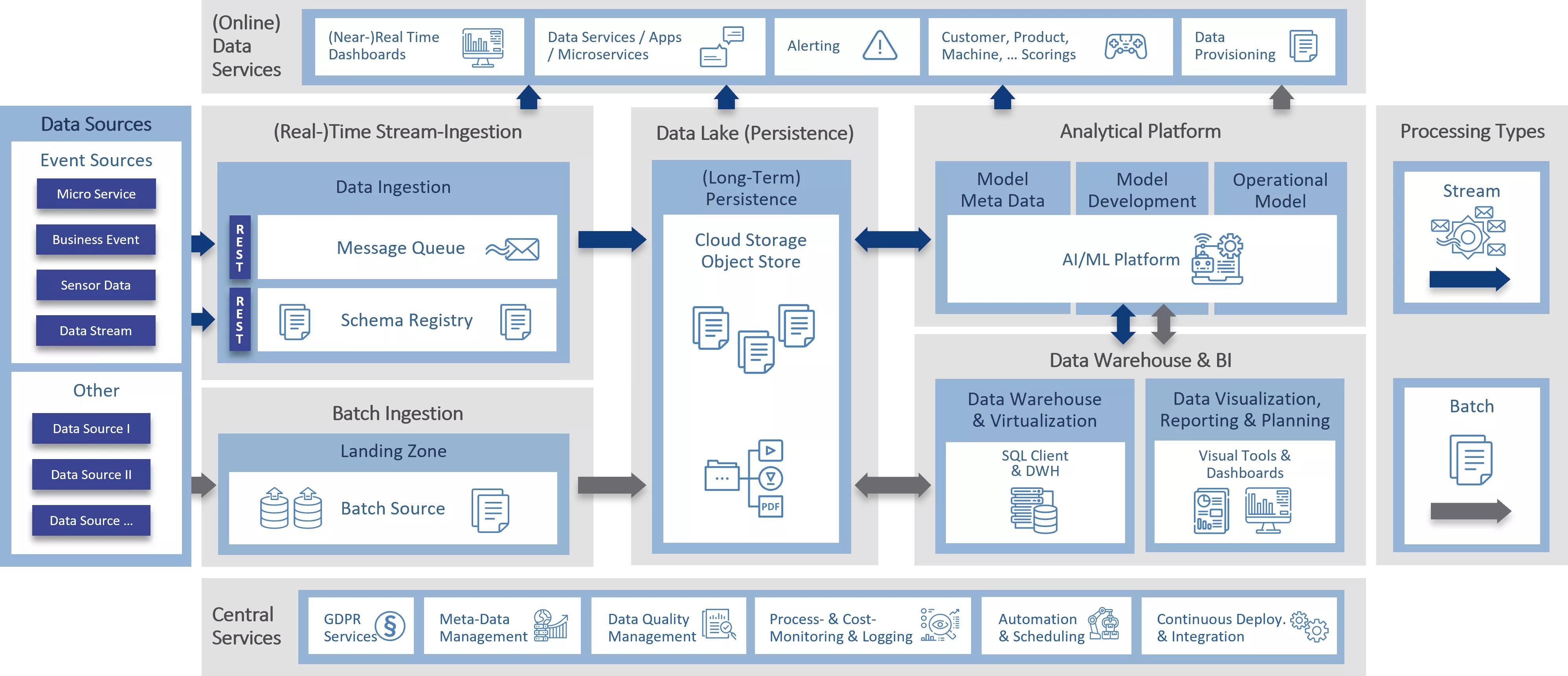
The different areas of these platforms are:
- Ingestion – Transporting data from the source systems to the cloud data platform
- Processing – Processing the data through the data lake to the target format
- Data lake – Persistent storage of data in any form
- Analytics, data warehousing & BI – Optimized data storage and data analysis
- Central services – Supplementary services for building and running a data platform and ensuring data governance
- Data services – on-demand data access
Spotlight on AWS
In this blog post we look at how Amazon's Lake House approach fits in with our reference architecture and how it can be used to implement a cloud data platform.
So what exactly is the Lake House approach and what services does it offer?
The AWS Lake House architecture approach describes how various services are integrated in the AWS cloud. This architecture makes it possible to create an integrated and scalable solution for processing, storage, analysis and governance of large amounts of data. Unlike other providers' lakehouse concepts, this architecture goes beyond the mere integration of data lake and data warehouse technologies. It also includes streaming, data governance and analytics.
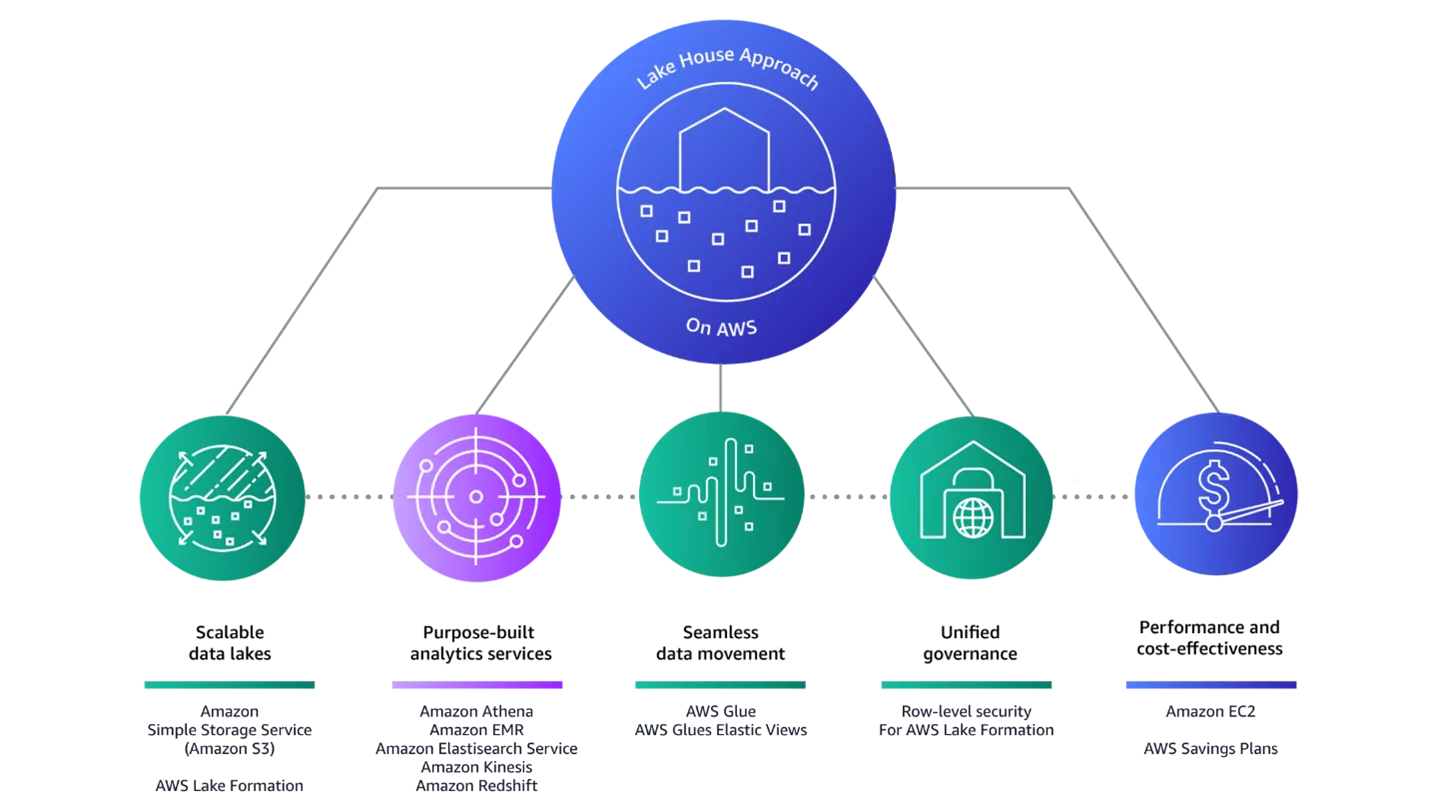
In addition to the cost-effective scalability of the overall system, the use of demand-oriented data services is also important for AWS. AWS maintains that a product based on a single service can never be more than a compromise solution. The provider is therefore a keen advocate of combining a variety of services to meet the user's requirements as optimally and comprehensively as possible.
The above diagram shows the individual AWS services available as part of the Lake House architecture, with the data lake at its core. The following services are used to build a data lake on AWS:
- Amazon S3 – data storage
- Amazon Glue – data catalog & ETL
- Amazon Lake Formation – data governance
- Amazon Aurora – direct access to the data lake via an SQL interface
The other services are then arranged around this central core. The advantage here is that, depending on the application, they can be used individually or in combination – and the cost is usage-based.
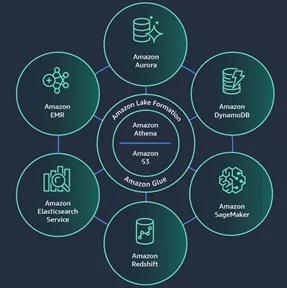
In this integrated system, communication between the services is also possible in different directions. A service such as a relational database can not only supply data to the data lake but can also receive reprocessed data from the data lake or data warehouse. The Amazon Glue Data Catalog ensures that data is available to all services via a common metadata view. The data in the Data Catalog is subject to governance via Amazon Lake Formation.
The concept can be easily understood by looking at the interoperability between the Data Lake and Amazon Redshift, the AWS cloud data warehouse service. The metadata in the data catalog allows a specific part of the data lake to be accessed transparently as part of the data warehouse. The Spectrum service within Amazon Redshift is used to do this. With Spectrum, a database defined in the Glue Data Catalog is represented as a schema integrated within the Amazon Redshift database. The tables in this schema together with the Redshift-native tables can then be used in SQL queries with joins etc. This use is still subject to governance by Amazon Lake Formation, however. So users can only access the tables, columns and data for which they have access rights.
Data lake, data warehouse, data catalog, etc. – what parts of the cloud data platform are covered by the Lake House approach?
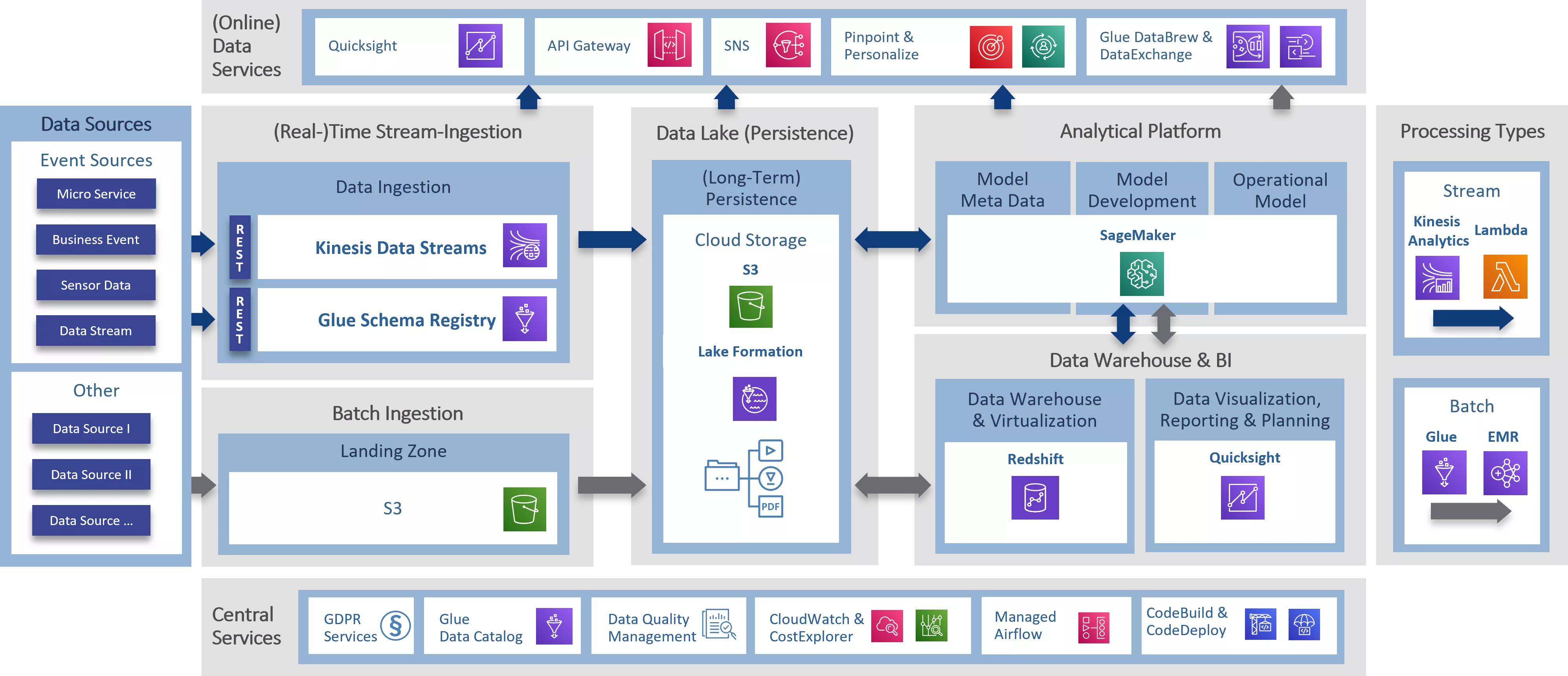
It is now possible to transfer the services and functionalities described in the Lake House approach to the majority of the b.telligent reference architecture for cloud data platforms:
- Ingestion and processing
- Streaming – Amazon Kinesis
- Batch – Amazon Glue ETL
- Data Lake - data storage
- Amazon S3
- Amazon Athena
- Data warehouse
- Amazon Redshift
- Analytical platform
- Amazon SageMaker
- Meta-data management and GDPR services
- AWS Glue Data Catalog
- Amazon Lake Formation
The remaining parts of the b.telligent reference architecture are covered by other services. These are not explicitly mentioned within the Amazon Lake House architecture approach, however, but are part of the large AWS service catalog.
- Data visualization/reporting – AWS Quicksight
- Automation & scheduling – Amazon Managed Airflow
- Continuous deployment and integration – AWS Codepipeline and Code Deploy
- Process & cost monitoring & logging – AWS Cloud Watch, Cloud Trail and AWS Cost Explorer
A complete implementation of the reference architecture with AWS services could look like this:
If you're about to implement a cloud data platform and would like to know more about implementing it on AWS, just contact us and we'll be happy to explain how we can guide you on your journey into the world of the AWS cloud.

