







Ever thought about what the architecture of a cloud data platform should look like? We did! In our free webinar series Data Firework Days, we introduced our b.telligent reference architecture for a cloud data platform, a blueprint of how to build a successful data platform for your analytics, AI/ML, or DWH use cases. And we went a step further. Since we all know there’s not just one cloud out there, we also translated our model for the three major cloud providers – Google Cloud Platform, AWS, and Azure. In this blog series, we intend to describe the reference architecture in the first three blog posts and then, in parts 4–6, we’ll look into implementation options for each of them. So, do join us on our journey through the cloud.
Sieben Wochen, sechs Themenbereiche, sechs Formate - wir zünden ein Datenfeuerwerk!
Interaktive Webinare, spannende Tool-Battles, Roundtables und Interviews mit Vordenkern der Digitalbranche: Das warendie Data Firework Days von b.telligent. Wir haben einen Blick auf die Themen geworfen, die den Puls der Digitalisierung in die Höhe treiben: Von Data Science über Cloud und DWH Automation bis hin zu Reporting, Data Governance und allem rund um Customer Intelligence.
To ensure common understanding of a cloud architecture and for a first look at the basics, let us begin with a high-level overview of the reference architecture. As you can see, we have also visually divided our reference model into different areas. I'll devote a short post to each of the main areas highlighted in gray – Ingestion, Data Lake, Analytics Platform, and Central Services – by describing the individual elements and their interrelationships and functions. Let’s start with ingestion, before we go on with Part 2 - Data Lake/Persistence and Part 3 - Analytics & DWH.
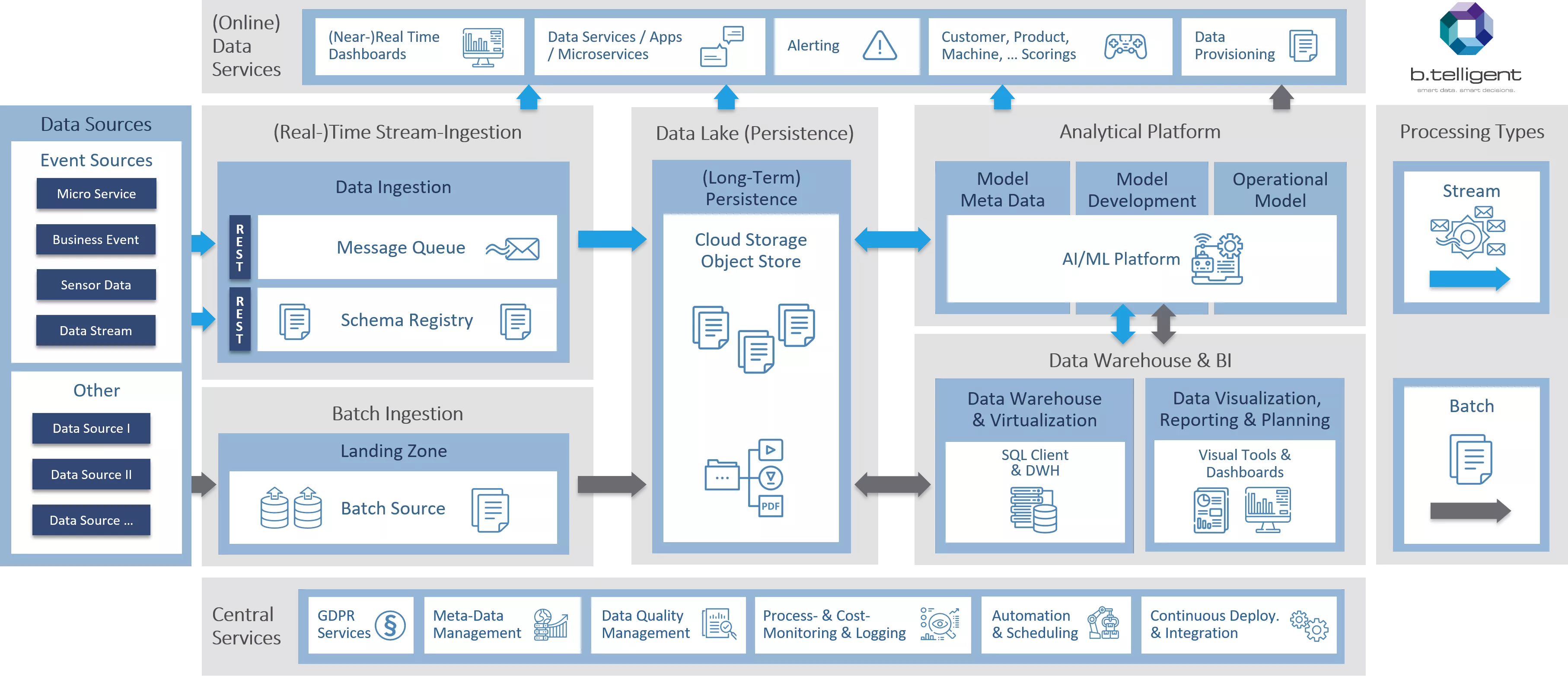
Come on in: data ingestion
In a typical customer landscape, we usually come across multitudes of separate data silos that have mushroomed almost exponentially over time. For instance, we see individual departments in the organization going for different tech stacks, each having to copy similar, if not the same, data sets to its respective silo for further processing. Combined with operational systems that support customers’ day-to-day business (e.g., POS, IoT, or banking transactions), increased variety of data (like video surveillance from stores, product images, or scanned PDF documents), and the speed at which the data are being generated, this translates into a requirement for real-time and batch ingestion channels to co-exist side-by-side.
Message queue is the backbone of real-time ingestion, providing low-latency insertion of events from a potentially large number of input devices/systems (e.g. sensors on cars), storing the events for a set amount of time, and delivering them downstream for real-time processing. Must-have capabilities of such queues are scalability (e.g., pre-Christmas market or Black Friday), durability (ability to withstand zone or region outage), and geofencing (storing data in the preferred geographic location for legal and compliance reasons). We also need to carefully assess criteria such as support for exactly-once processing (a banking transaction must be processed only once), reprocessing (capability to replay events on-demand), ordering (reliance on the order of events), encryption, etc.
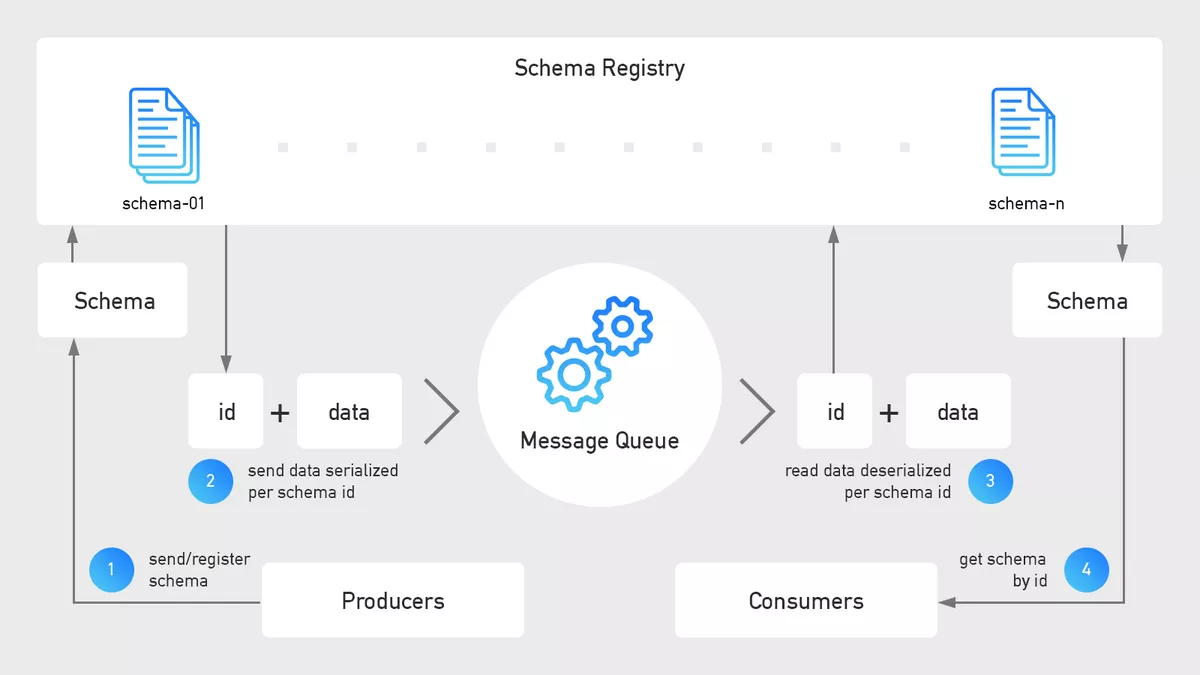
As numerous components in our pipeline process data, proper schema management becomes essential. The data need to be understood the same way, whether we process data for our front-end apps or within our AI/ML platform. This is even more important, when you consider that the structure, data quality, and other parameters of incoming data vary over time. In other words, an updated schema in source systems must not cause failures in downstream components. The schema registry allows for versioned schema management, schema evolution, additional tagging (like GDPR), etc.
Note that in the reference architecture at the beginning of this article, both the message queue and schema registry are preceded by the RESTful interface. The reason for using the REST API, instead of native clients, is the preference for protocols over specific tools.
Batch sources are best served by batch ingestion, as they are typically scheduled on a regular basis (like your daily DWH export), or on-demand (e.g., a department loading a one-off dataset). A scalable and highly-durable storage service is the preferred choice to help accommodate structured, semi-structured, and non-structured data in one place, to avoid the same data silo problem outlined above. We prefer features like geofencing, storage classes (differentiation between hot and cold storage), object lifecycle management (automatically change storage class after a specified time period), versioning, support for handling static content (think static content for your Web applications), encryption-at-rest, fine-grained security policies, etc.
For now, this is enough on the ingestion part of our cloud data platform reference architecture. But if you want to dig deeper, feel free to read the enxt parts of this blog series! If you have questions, don’t hesitate to contact our cloud experts – they’d love to hear from you!
Continue with Part 2: Data Lake!

