







As stated in part one of this blog series on the reference architecture for our cloud data platform, we will share and describe different parts of this model, and then translate it for the three major cloud providers – Google Cloud Platform, AWS, and Azure. In case you just came across this blog post before seeing the first one about the ingestion part of our model, you can still read it here first. For all others, we’ll start by looking at the data lake part of the b.telligent reference architecture before diving deeper into analytics and DWH in part 3.
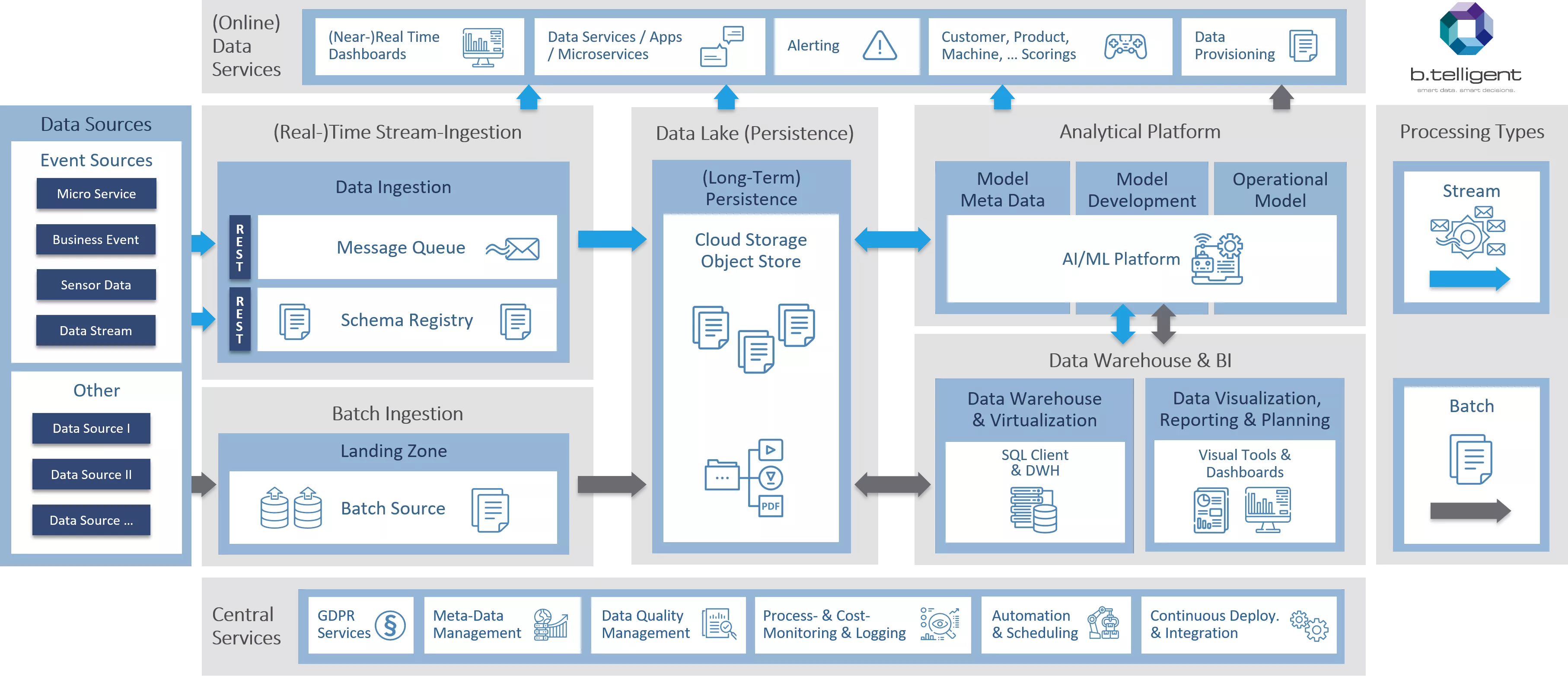
Just so you won’t keep complaining, the reference architecture is in its entirety here. Go for it!
We have successfully ingested data into the platform, which by itself is usually a major obstacle in many organizations we’ve dealt with. But now we need to tackle a myriad of topics in the field of data management. Specifically, we must transform raw data sets into a standardized and curated form (like data cleansing, data quality, GDPR, etc.), or act upon incoming events, such as sending a mobile notification update on your bank account.
The stream processing service handles incoming events from the message queue on an event or micro-batch basis, and applies transformations, lookups, or other transformations. This results in a lower footprint of these services, which means lower CPU and RAM requirements. Whether in a managed or serverless form, both the options must account for cold starts (might take a few seconds or minutes to spin-up resources in the background before the first event is processed), and timeouts (not suitable for long-running processes). Another option is to run a self-managed stream processing engine (like Spark), but here you need to seriously consider whether the increased operational needs offset the configuration freedom you gain. On the other hand, you may have existing streaming pipelines written in Spark, and you need to lift & shift them quickly. In that case, your obvious choice would be a managed, big data cluster service.
Batch processing almost reflects previously stated characteristics. It typically operates on large data sets, thus placing more importance on CPU and RAM configuration, while pushing cold starts and timeouts aside. With the processing time going into minutes or hours, parallel processing with high-availability and durability of intermediate results takes precedence (remember Hadoop?) From this you may have already guessed that what one deemed tedious work just a few years ago (setting up your cluster), has transformed into a matter of low single-digit minutes in the cloud-native world. The outcome: transient and single-purpose clusters have become more relevant than 24/7 general clusters.
Once we have processed our data into the final form, we need to store the results in a multi-purpose persistent storage, a data lake. Technically, the requirements for this component-scalable and highly-durable storage service are features like geofencing, encryption-at-rest, fine-grained security policies, etc. From a logical perspective, we can structure our data lake into areas based on the data processing stage (from a raw to a standardized, curated, and trusted layer, for instance), and further on business dimensions such as the country (for organizations with a global footprint). Most importantly, our data lake service must be tightly integrated with other cloud services to enable AI/ML, business, or DWH teams to work with consistent and reliable data sets.
That’s two out of three parts. Before we proceed to individual vendor-specific versions of our model, we’ll dive first in part 3 into the analytics platform and data warehouse and BI elements of our architecture. Any questions so far?
Continue with part 3: Analytics