







Whether in storage, production or customer service – completely different business processes all involve a use of images which need to be analyzed and evaluated. However, manual evaluation of these images is time-consuming and error-prone. These procedures can be automated with the help of computer vision, i.e. machine analysis and processing of images. Thanks to highly mature methodology, machines are now able to carry out even complicated analyses.
What now - dog or cat?
If a picture of a cat and a dog are placed next to each other, even small children can distinguish between the animals. But which attributes make this possible? What is the set of rules for differentiating between the two animals?
Dogs are bigger than cats <-> But a Maine Coon is bigger than a Chihuahua
Dogs have more pointed muzzles <-> What about the pug?
Cats have thick whiskers <-> But even without whiskers, a cat remains a cat
Although this is a trivial issue which a human can answer completely intuitively, creation of a robust set of rules here requires an enormous amount of effort. But is such a set of rules even necessary for a machine to be able to analyze images fully automatically?

How machines learn
Instead of going through an elaborate process of defining rules, we can give machines the opportunity to discover or learn underlying patterns independently. The learning process can be divided into four basic steps:
- Labeling: Machines learn on the basis of a data set. First of all, many sample images must be collected. These are then labelled, i.e. each sample image is manually assigned to one of the two classes (dog | cat). It is important to select sample images which are as representative as possible. If all cat pictures are taken in living rooms, but all dog pictures in meadows, the machine might inadvertently learn the difference between the environments instead of the animals.
- Splitting: We then have to split our labelled dataset into two independent sets – training and testing. The training data set will be used to train our model. The test data set will be used subsequently to determine whether the model has really learned to distinguish between dogs and cats – and has not simply remembered all the images in the training data set.
- Training: We now display all the images of our training set within a model, and inform it about the correct class of each image. Based on this classification, the model is then able to find patterns which can be used to distinguish between dogs and cats.
- Testing: After the model has been trained, it is shown the images of the test data set – but without any classification. The model must then decide whether each image represents a dog or a cat. The model's performance can subsequently be evaluated by comparing the model's decisions with the actual classes.
What can models do?
The example above involves a simple application of computer vision. The model simply has to decide what can be seen in an image. This is a single-label image classification which only determines whether the image is that of a dog or cat. However, further model types are available to resolve a variety of issues: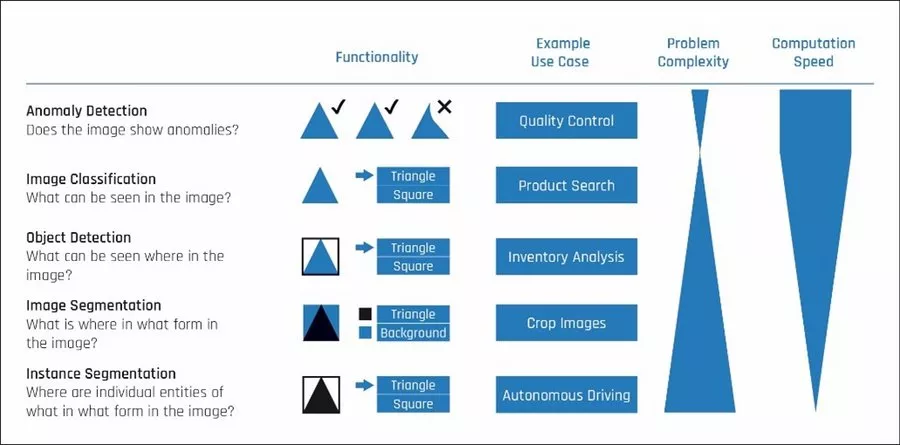
Anomaly detection: The model learns how images normally appear and can detect deviations from them. "Negative examples" are not needed here for training.
Image classification: As mentioned earlier, the model recognizes the contents of an image. A distinction can be made here between single-labels and multi-labels. In the case of multi-label problems for example, an image displaying a dog and a cat can be assigned to multiple classes.
Object detection: The model detects the position of objects and assigns each object to a class. Accordingly, it indicates the coordinates of a rectangle enclosing a cat in an image, for example.
Image segmentation: The model classifies each pixel. This allows a cat to be clearly distinguished from a background, for example.
Instance segmentation: Object detection is first carried out to identify the cat and its position. In addition, the cat's outline is determined with pixel precision.
These methods differ not only in terms of issues they resolve, but also in terms of the effort involved in model creation. The labelling effort also depends largely on the selected model type. For each use case, it is important to find the model type (or a combination of several) best suited to resolving the involved issue.
Tired of evaluating images manually? Or are you eager to develop new business cases with images? Let's plan your project together!

