







The PoC has been made, a model ready for production has been trained, and the showcase has inspired all stakeholders. But in order for business cases to be realized with the model, it (and the related processing) must be embedded in the existent (cloud) landscape.
The basic steps of image processing
Handling of image and video files poses completely new challenges compared to structured data. The right framework can help overcome these challenges as quickly as possible and thus simplify implementation of image processing.
Image files are usually processed in a stream. Each image goes through this entire procedure individually. It can be divided into four discrete, basic logical steps:
Prepare: The image is prepared for the subsequent processing phases. First, the image file is loaded (from blob storage). After that, the adjustments necessary for analysis are made to the image. This can comprise, for example, resizing or cropping the image. This is often followed by base64 encoding for the next processing step.
Analysis: In the next step, the image is automatically analyzed (usually with ML models). The models needed here are usually provided via a REST API. In the analysis step, the string encoded in base64 is sent to this interface. The response contains the analysis result – for example, the detected class of the image or the coordinates of certain objects in the image.
Transform: The image can optionally be transformed before permanent storage. This is done either on the basis of the analysis results (e.g. removal of faces for anonymization) or independently (lowering resolution to save storage space).
Action: Finally, actions are executed based on the analysis results. This includes, for example, permanent storage of images and metadata. However, messages can also be sent to downstream systems to inform them about the completed image processing.
Processing components
Thanks to the public cloud and the (serverless) services offered there, implementation of the individual processing steps is now easier and more standardized than ever before. However, more than a virtual machine is needed for images to be processed in productive operation. A robust architecture for this can consist of the following components:
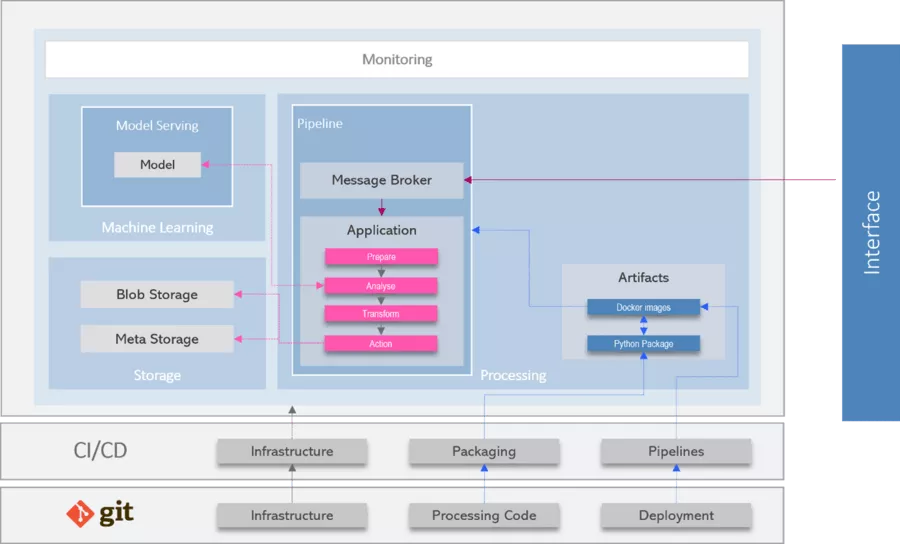
Model serving: In order for the trained model to be used, it must be made available. This usually entails a REST API which receives the (encoded) image as input and returns the analysis results as a response. All hyperscalers offer services allowing easy deployment of models.
Message broker: For new images to be processed robustly, a scalable messaging service is needed. For example, upload of an image can comprise the event which triggers publication of a message. The message then triggers asynchronous processing of the image.
Application: Needed here is an instance which applies the four basic steps of processing to the image. If the steps have been implemented within a container, a (serverless) container service can be used for this purpose.
Storage: On completion of analysis, the image is permanently put into blob storage. Required additionally here is a database for storing the image's metadata and analysis results.
Artifacts: The container images to be managed are stored in an artifact registry. Also located here are the independently created Python packages which provide the code needed for processing. These are imported when the container is built.
Monitoring: To enable trouble-free operation in the long-term, the process steps must be monitored. This monitoring detects (and reports) errors occurring in any process. It also provides early warnings of unexpected deviations from predictions by models.
When things have to go fast – synchronous image processing
An architecture like the one shown above does not make sense for every application, however. In the example above, images are processed asynchronously – when (and how quickly) this processing finishes is of secondary importance here. However, integration of a computer-vision model into an app, for example, requires processing with low latency. In order to fulfil this requirement, the architecture must be modified.
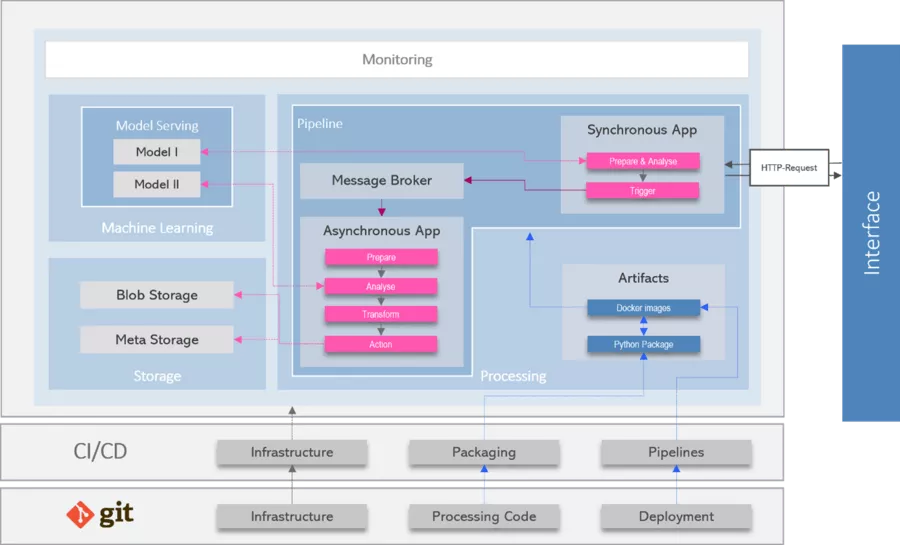
In this case, it is advisable to separate the entire processing into a synchronous and an asynchronous part. An HTTP request triggers synchronous processing. In this part, only the absolutely necessary analyses are performed before their results (for example, image classification) are returned; triggered subsequently is asynchronous processing including publication of a message in the message broker.
The asynchronous processing part involves execution of all steps which are not time-critical. Analyses can also be performed in this part (e.g. to prevent storage of images with faces). Subsequently, the images and master data can also be stored permanently.
Use of inter-project synergies
Of course, functional architectures can be built via the interface or the respective hyperscaler's CLI. However, this poses two problems:
- Manual construction of the infrastructure is error-prone and only partially traceable later.
- Establishment of a second, identical infrastructure (e.g. for another project) is time-consuming.
For this reason, it is appropriate to define the infrastructure in a code (e.g. Terraform). This allows optimal utilization of inter-project synergies and minimization of superfluous manual expenditure.
Do you have a computer-vision model (or an idea for it) just waiting to be used productively? Let's plan how to best meet this challenge together.

