







Seit der Veröffentlichung von ChatGPT und der Aufmerksamkeit, die auf Large Language Models gelenkt wurde, erleben wir einen rasanten Anstieg an Veröffentlichungen weiterer Modelle und einen sich schnell entwickelnden Markt mit der Nutzung von LLMs. Die Eignung eines Modells für die Nutzung im Unternehmenskontext ist stark abhängig vom jeweiligen Use Case. In diesem Blogbeitrag wollen wir die derzeit wichtigsten Modelle genauer ansehen und anhand unternehmensrelevanter Kriterien vergleichen, sodass Du einen besseren Überblick behalten kannst.
Large Language Models existierten schon vor ChatGPT
Mit der Einführung von ChatGPT wurde die Welt auf den Kopf gestellt – zumindest scheint es so. Tatsächlich existierten Large Language Models jedoch schon vor der Veröffentlichung von OpenAIs ChatGPT. Den Grundstein für die Transformation von „einfachem“ Natural Language Processing (NLP) hin zur Generative AI legten Google und die University of Toronto bereits 2017 in ihrem Paper „Attention is all you need“. Dort präsentierten sie die Transformers-Architektur, die mithilfe des Aufmerksamkeitsmechanismus Beziehungen zwischen Wörtern erfasst und Abhängigkeiten über längere Textsequenzen modelliert. So ist es möglich, längere, zusammenhängende Texte zu generieren und sogar ganze Dialoge zwischen Menschen und KI-Systemen zu erschaffen.
OpenAI führte 2018 sein erstes GPT-Modell (Generative Pre-trained Transformer) ein, das auf der Transformers-Architektur basiert. Seitdem wurden die Sprachmodelle kontinuierlich erweitert, sowohl durch die Erweiterung der Datensätze als auch durch die Vergrößerung der Modelle selbst – von den anfänglichen 115 Millionen Parametern (GPT-1) bis hin zu den gemunkelten 170 Billionen Parametern (GPT-4).
Nutzungsrechte
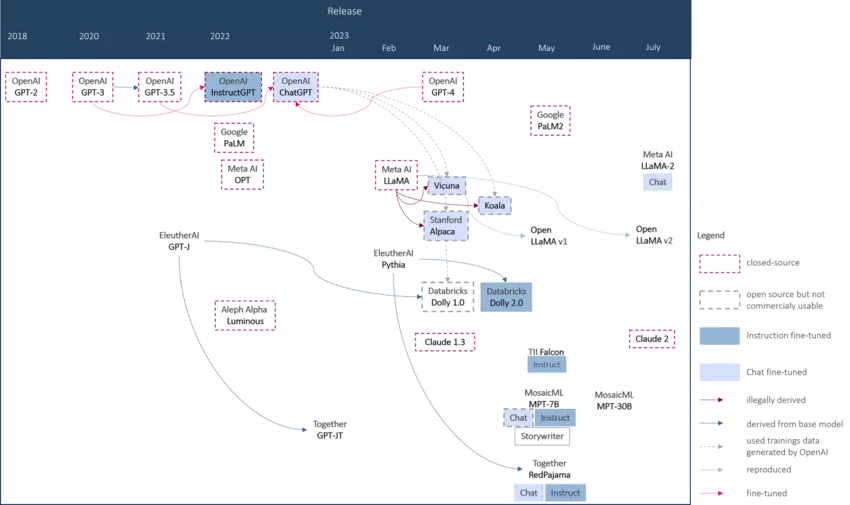
Nach der Veröffentlichung von ChatGPT im November 2022 gewann die Community an Fahrt und es wurden zahlreiche neue Modelle vorgestellt. Ein kritischer Aspekt bei der Betrachtung dieser Modelle liegt in ihrer Transparenz und den Nutzungsrechten. Obwohl einige Modelle als Open Source gekennzeichnet sind, sind sie aufgrund ihrer Entwicklungsgrundlage nicht für kommerzielle Zwecke geeignet. Manche Modelle nutzen beispielsweise mit ChatGPT generierte Dialoge als Trainingsdaten. Dies macht die Nutzung dieser Modelle rechtlich schwierig, denn OpenAIs Nutzungsrechte gestatten die Verwendung der API zur Erzeugung von Konkurrenzprodukten nicht. Einige Modelle verwenden hingegen das geleakte Meta LLaMA, das nur für die Wissenschaft verwendet werden darf. Um die LLaMA-Ableger nutzen zu können, müssen deren Delta-Gewichte auf das originale LLaMA angewendet werden. Die Delta-Gewichte laufen hier unter der Apache-2.0-Lizenz, das darunter liegende Meta-Modell jedoch unter einer nichtkommerziellen Lizenz. Das wirft ein Schlaglicht darauf, dass es oft nicht nur eine, sondern zwei Lizenzen für ein Modell gibt: eine für den Inferenzcode (die oft etwas generöser ist) und eine weitere für die Gewichte des Modells, die (zum Beispiel bei LLaMA) oft etwas restriktiver ist und eine kommerzielle Nutzung ausschließt. Mit diesem Schachzug kann sich ein Unternehmen das Label „Open Source“ verleihen (der Code steht unter einer entsprechenden Lizenz), gleichzeitig kann aber die kommerzielle Nutzung des eigenen Know-hows verhindert werden (denn der Code nützt ohne die Modellgewichte nichts).
In jüngster Zeit sind jedoch bei wichtigen Modellen die Lizenzen (auch für die Gewichte) im Nachhinein durch permissivere ersetzt worden. Falcon ist ein solches Beispiel, das zunächst eine kommerzielle Nutzung nur gegen Lizenzgebühren zuließ, bald danach aber unter eine Apache-2.0-Lizenz gestellt wurde. Auch die Lizenz von LLaMA-2 lässt, anders als bei LLaMA, eine kommerzielle, gebührenfreie Nutzung zu – jedoch in eingeschränktem Umfang. Wenn die Anzahl der aktiven Nutzer:innen in einem Monat die Schwelle von 700 Millionen überschreitet, ist eine Nutzungsgenehmigung von Meta erforderlich.
Die kommerzielle Bereitstellung und Nutzbarkeit von Modellen als Alternativen zu ChatGPT ist für die Entwicklung neuer LLM-Applikationen erstrebenswert, das zeigt die Entstehung der Projekte, die diesen offenen Ansatz verfolgen und deshalb eigene Architekturen und bereinigte, bzw. durch Crowdsourcing gesammelte, Datensätze zum Einsatz bringen. Ein prominentes Beispiel dafür ist Dolly 2.0, für das Databricks mit eigenen Angestellten in einer massiven Crowdsourcing-Anstrengung über 15.000 Trainingsdaten generiert hat, nachdem das erste Modell Dolly 1.0 auf mit ChatGPT erzeugten Daten trainiert wurde und kommerziell nicht zulässig war. Ein weiteres Beispiel ist das Projekt RedPajama von together.ai, das das originale Meta LLaMA Dataset reproduzierte und schließlich selbst Modelle trainierte und unter permissiver Lizenz veröffentlichte.
Datensicherheit
Ein weiterer kritischer Aspekt betrifft die Nutzung und damit die Sicherheit der Daten, mit denen LLMs interagieren. Wo werden die unternehmenssensiblen Daten für das Finetuning der Modelle oder die Anreicherung der Prompts gespeichert und wie werden sie ggf. weiterverwendet? Dieselbe Frage stellt sich für die im Chat ausgetauschten (vielleicht sogar zum Teil personenbezogenen) Daten. Die Nutzung von OpenAIs Modellen wurde diesbezüglich stark hinterfragt und kritisiert. Mittlerweile hat OpenAI hier nachgeschärft, sodass das Teilen der Daten mit OpenAI zur Weiterentwicklung von AI-Modellen über ein Opt-in von dem/der Nutzer:in selbst gesteuert werden kann. OpenAI behält sich aber vor, die Daten zum Missbrauchsmonitoring 30 Tage aufzubewahren. Ebenso hält es Microsoft mit seinem Azure OpenAI Service, über den auf die OpenAI-Modelle per REST-APIs zugegriffen werden kann.
Das deutsche Start-up Aleph Alpha positioniert sich in dieser Debatte eindeutig in Richtung Datensicherheit – es setzt auf ein eigenes Rechenzentrum in Deutschland und legt großen Wert auf die Einhaltung der Datenschutz-Grundverordnung (DSGVO). Zusätzlich nutzt das Start-up Explainable-AI-Methoden, um die KI-Ausgabe nachvollziehen und sogar Ausgaben ohne vertrauenswürdige Quelle unterdrücken zu können. Die Plattform von MosaicML für Modelltraining und Deployment positioniert sich ebenfalls und verspricht, die Daten weder zu nutzen noch zu speichern.
Diese Themen sind dann relevant, wenn ein Unternehmen sich dafür entscheidet, das LLM nicht selbst zu hosten, sondern die Daten für das Finetuning sowie die Nutzer-Prompts an eine externe API zu versenden. Gerade deswegen sind Open-Source-Modelle für Unternehmen attraktiv, da sie auf der eigenen Infrastruktur deployt werden können und damit die Kontrolle über die eigenen Daten gewährleistet ist.
Landkarte der Large Language Models
Mittlerweile tummeln sich unzählige Modelle auf dem Markt. Anhand verschiedener Kriterien haben wir die etablierten und für Unternehmen interessanten Modelle verglichen und möchten Dir einen generellen Überblick über die Landschaft der LLMs verschaffen. Hier haben wir zwar Meta LLaMA als eines der ersten LLMs berücksichtigt, alle weiteren direkt oder indirekt davon abgeleiteten Modelle betrachten wir in unserer Übersichtstabelle jedoch nicht, da sie für den unternehmerischen Einsatz nicht infrage kommen.
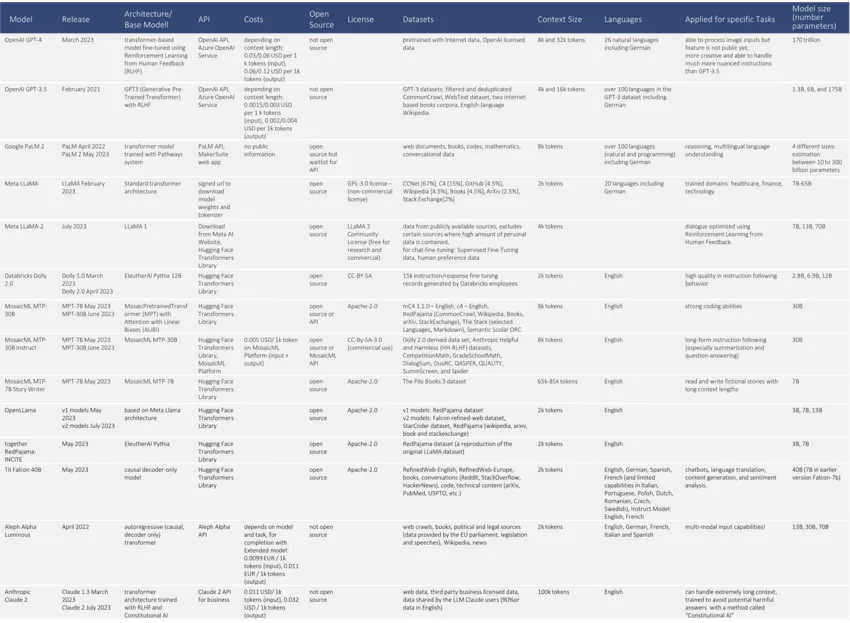
Welches Modell für den Einsatz in Deinem Projekt geeignet ist, hängt stark vom Use Case ab. Hast Du unternehmenssensitive Daten, dann kann die Wahl auf ein selbst gehostetes Modell (bezogen z. B. über Hugging Face) fallen. Hast Du hingegen keine sensiblen Daten, weniger umfangreiche Prompts und möchtest schnell ins Doing kommen, dann greife direkt auf OpenAI zu. Da die direkte Einbindung von OpenAI aufgrund der Datenschutzbedenken jedoch Skepsis hervorruft, ist die Nutzung von Azure OpenAI ein Kompromiss; dieses erleichtert die Einhaltung von Compliance-Anforderungen dadurch, dass das Modell in der jeweils ausgewählten Azure-Region gehostet wird. Das Abfließen der Daten in die USA wird somit vermieden. Da Microsoft in sehr vielen Unternehmen in der DACH-Region bereits als vertrauenswürdiger, langjähriger Partner etabliert ist, fällt den Verantwortlichen die Entscheidung für eine Azure-Lösung oft wesentlich leichter als für die direkte Ansprache der OpenAI-API. Braucht Dein Use Case aber zum Beispiel einen extrem langen Kontext, um dem LLM einen mit Daten angereicherten Prompt zu übergeben, dann verwende Claude. Claude schneidet außerdem auch in der API-Verfügbarkeit und der Latenz deutlich besser ab als GPT-4, bei dem temporäre Ausfälle und langes Warten auf den Output keine Seltenheit sind. Stehen in der Anwendung hingegen ethisch korrekte Antworten und die größtmögliche Vermeidung von schädlichen Outputs im Fokus, dann könnte LLaMA-2 geeignet sein. In der Entwicklung des Chat-Modells hat Meta einige Maßnahmen wie Supervised Safety Fine Tuning, den Einsatz eines Safety Reward Models und Red Teaming zur Erzeugung besonders verantwortungsvoller Ergebnisse ergriffen.
Egal für welches Modell Du dich entscheidest, die Performance muss stimmen. Bislang galt der von OpenAI GPT-3.5 und GPT-4 generierte Output als verlässlich und gut. Dein Anwendungsfall wird entscheiden, welches der OpenAI-Modelle verwendet wird. GPT-3.5 empfiehlt sich für kleine Anfragen oder um Zwischenschritte zu unterstützen, während GPT-4 für einen langen Kontext, Kreativität und ein geringeres Maß an Halluzinationen besser performt. Die Performance eines OpenAI-Modells scheint jedoch im zeitlichen Verlauf zu variieren und kann in einzelnen Aufgaben sogar stark sinken, weshalb die Qualität eingesetzter Modelle über die Zeit beobachtet werden sollte. Auch zwischen den Open-Source-Modellen gibt es Performance-Unterschiede. Hier kann das Open LLM Leaderboard von Hugging Face richtungsweisend sein.
Die Geschwindigkeit, mit der neue Modelle entstehen, ist faszinierend. Mit dem Launch von LLaMA-2 werden bald viele weitere gute Open-Source-Modelle für Unternehmen verfügbar sein, wie zum Beispiel das neue togethercomputer/LLaMA-2-7B-32K oder stabilityai/StableBeluga2. Ebenso faszinierend sind die Anwendungsfälle, die sich Large Language Models zunutze machen.
Wie Unternehmen sich dem Thema LLM und der Use-Case-Findung nähern, kann im nächsten Blogpost nachgelesen werden.
Bei Fragen melde Dich gerne bei uns!

