





Du schwankst zwischen ETL- oder Data-Warehouse-Automation-Tools und einem „Ich-bau-alles-selbst“-Ansatz? Dann solltest Du unbedingt dbt kennenlernen! Es übernimmt leichtgewichtig alle Routinearbeiten, ist dabei nicht „im Weg“ und in sehr kurzer Zeit erlernbar – und Open Source. Ideal zusammen mit einer Cloud-DB wie Snowflake. Es ist daher nicht verwunderlich, dass sich für so einen Technologiestack, der auf Daten-Wertschöpfung bei effizienter, aufwandsarmer Technogie setzt, der Begriff „Modern Data Stack“ immer mehr durchsetzt.
Moderne BI-Architektur
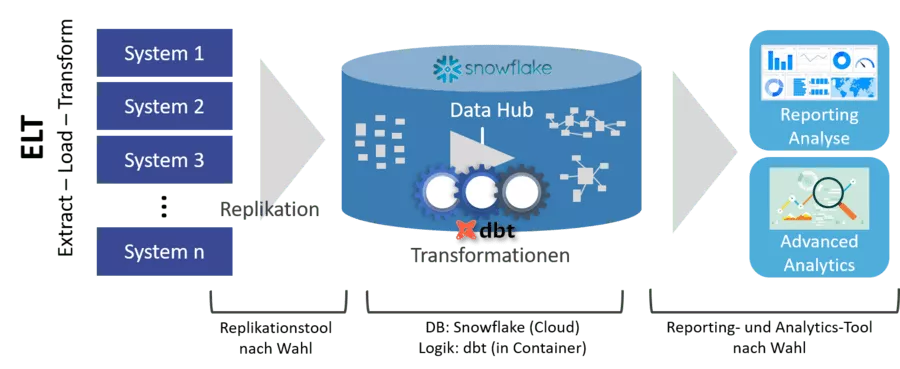
Bis vor wenigen Jahren war es beim Bau von Data Hubs üblich, ETL-Strecken zu implementieren (Extract – Transform – Load), bei denen Datentransformationen auf dem Weg vom Quellsystem in die Zieldatenbank durchgeführt wurden. Heute wird der modernere Ansatz „ELT“ (Extract – Load – Transform) verfolgt, bei dem zunächst die Quelldaten in Rohform in die Zieldatenbank geladen (repliziert) werden – noch ohne Transformationen, die erst danach erfolgen.

Die Gründe dafür liegen auf der Hand:
- Storage für diese Daten (letztlich ein Replikat der Vorsysteme) ist billig geworden.
- Der Ladeschritt (Extract – Load) ist im Vergleich zur späteren Transformation simpel und daher aufwandsarm implementierbar, ggf. mit dediziertem Tool.
- Als Data Lake lassen sich daher auch viel mehr Rohdaten erstmal laden, als gleich (vergleichsweise aufwändig) im Data Hub nachgelagert transformiert werden. Man spricht auch von einer „Staging Area“.
- Die Performance der eigentlichen Transformationen ist am höchsten, wenn sie in derselben Datenbank ablaufen.
- Wartung und Fehlerbehebung sind stark vereinfacht, da immer auf die abgespeicherten Rohdaten zurückgegriffen werden kann – auch wenn sich z. B. Logik rückwirkend ändert.
Best-of-Breed mit dbt und Snowflake
Hier setzt das Werkzeug dbt („Data Build Tool“) als Best-of-Breed-Ansatz des Modern Data Stack an:
dbt kümmert sich nur um Transformationen (das „T“ in „ELT“) und arbeitet ausschließlich auf der Zieldatenbank.
Der (vergleichsweise einfache) Beladungsschritt („EL“) von den Quellsystemen in die Zieldatenbank muss separat erfolgen. Dazu kann unter einer Vielzahl von Werkzeugen gewählt werden – rein cloudbasierten oder mit On-Premise-Installation. Oft sind Konnektoren zu sehr vielen Systemen und Datenbanken mit dabei. Eine unvollständige Auswahl:
- Stitch
- Fivetran
- SymmetricDS
- Qlik Replicate (ehem. Attunity Replicate)
- oder – und oft nicht die schlechteste Wahl – ein paar Zeilen eigener Python-Code, über den man volle Kontrolle hat.
Passend zum sehr schnell einsatzbereiten dbt bietet sich eine Cloud-Datenbank an, die ebenso schnell am Start ist – und hinterher mit Performance glänzt: Snowflake.
Macht, was es soll – schnell und unkompliziert
dbt selbst ist Open Source und damit komplett kostenlos nutzbar unter Windows wie Linux. Es ist eine einfach installierbare Kommandozeilenapplikation. Eine komplette Beladung wird z. B. ausgelöst mit dem Kommando:
dbt run
Es existiert auch eine (moderat) kostenpflichtige Cloud-Variante, die eine eigene browserbasierte IDE (Entwicklungsumgebung) mitbringt.
Hervorzuhebende Eigenschaften von dbt:
- Leichtgewichtig und nicht intrusiv, sehr gut dokumentiert
- Entwicklerfreundlich: sehr schnell gelernt und einsatzbereit, passt zu DevOps
- Push-Down: Es werden (SQL-)Befehle zur Datenbank geschoben und dort performant lokal ausgeführt
- Historisierung (SCD2) out of the box einfach konfigurierbar
- Mit dabei: Logging, Testing-Framework und Erzeugung von Web-Dokumentation (inkl. Lineage)
- Harmonisiert perfekt mit einem Versionskontrollsystem wie Git und CI/CD-Methoden
- Ausgelegt für (ggf. Mikro-)Batchverarbeitung
- In beliebige Job-Scheduler integrierbar – oder auch getriggert in Cloud-Funktionen wie Azure Functions
- Und das Beste: Die Data Engineers konzentrieren sich auf die Transformationslogik in SQL (sehr ähnlich zu geschachtelten DB-Views) – den Rest automatisiert dbt
Auch Snowflake bringt eine Reihe von Vorzügen mit, die gut zu dbt passen:
- Analytische Datenbank (spaltenbasiert) mit sehr hoher Performance
- Komplett cloudbasiert und in Minuten aufgesetzt (bietet auch eine kostenfreie 30-Tage-Trial-Version)
- Hosting nach Wahl: Microsoft Azure, Google Cloud Platform, AWS
- Abrechnung getrennt nach genutztem Storage und Rechenzeit
- Wartungsfrei und einfach zu nutzen, es gibt z. B. nicht mal DB-Indizes
- Autosleep: DB kann sich nach einstellbarer Zeit ohne Nutzung automatisch schlafen legen und erzeugt keine Rechenzeitkosten
- Zero-Copy-Cloning, mit dem sich Kopien der kompletten Datenbank in Sekunden erstellen lassen: z. B. für Integrationstests oder Entwicklerversionen
- Quasi alle Reporting-Systeme wie Power BI, Tableau, Qlik etc. unterstützen Snowflake als Datenbank, ebenso der typische Data-Science-Tool-Stack
Wie oben erwähnt, unterstützt dbt auch andere Datenbanken als Snowflake. Wichtig ist uns:
Bei der sehr kurzen Einarbeitungszeit und den quasi geschenkten Features von dbt sollte man sich insbesondere den Eigenbau eines – und sei es noch so kleinen – ELT-Frameworks gründlich überlegen (auch wenn das alle Entwickler gerne machen ;-) )
Für den Data Engineer von heute
dbt richtet sich an codeaffine BI-Entwickler, die es schätzen, Transformationsregeln in SQL als SELECT-Statements zu schreiben. Es bietet keine grafische Oberfläche zur Modellierung von Datenflüssen, was aber oft kein Nachteil ist: Unten zeigt sich, wie einfach Logik formuliert werden kann. Als Beispiel eine Regel, die den Umsatz pro Monat berechnet und in einer materialisierten Tabelle „revenue_by_month“ ablegt:

Mit der ref-Notation im „from“ des SQL-Statements erkennt dbt die Abhängigkeiten der einzelnen Entitäten. Darauf wird intern der Abhängigkeitsgraph erzeugt (Direct Acyclic Graph = DAG) und bei der Ausführungsreihenfolge automatisch beachtet. dbt kann auch selbstständig parallelisieren. Der Code wird durch einen vollwertigen Template-Prozessor (Jinja) verarbeitet, so dass z. B. Makros eingesetzt werden können.
Vorteile dieses codeorientierten Ansatzes gegenüber einem grafischen ETL/ELT-Tool:
- In SQL lässt sich Transformationslogik sehr prägnant und zeitsparend formulieren – und später leicht warten.
- Effiziente, agile Entwicklung: SQL-Statements lassen sich bei der Entwicklung direkt ausprobieren und leicht in einer Versionsverwaltung halten und bei paralleler Entwicklung mergen.
Nachteil:
- Man muss SQL können (und mögen) – das ist jedoch ohnehin ein typisches Muss für einen Data Engineer.
Eine Affinität zu Skriptsprachen wie Python ist ebenfalls hilfreich, um ggf. Hilfsskripte (z. B. für die Beladung aus den Quellsystemen in die Datenbank, das „EL“) zu schreiben. dbt selbst ist in Python geschrieben.
Auch ein tolles Werkzeug ist nur ein Werkzeug
Wie bei allen BI-Werkzeugen – auch grafischen – gilt:
Auch bei einem effizienten Werkzeug wie dbt ist eine gute innere Struktur wichtig, um ein System zu schaffen, das robust, fehlertolerant, verständlich und leicht wart- und erweiterbar ist.
Hier ist BI-Erfahrung notwendig, um nicht später vor einem unwartbaren „Haufen Spaghetti“ zu stehen. Struktur kann und will dbt nicht forcieren. Daher gibt es alle Freiheiten für eine eigene
- Namens- und Codekonvention
- Datenarchitektur (Layerkonzept, Aufteilung von Zuständigkeiten etc.)
dbt erzeugt zwar eine hübsche Dokumentation (klick- und zoombar), aber erst eine gute Architektur ergibt langfristig ein leicht wartbares System.

Das Schöne: Es kann passend zum Anwendungsfall entschieden werden, auf welche Modellierungstechniken (wie 3NF, Sternschemata, Data Vault) gesetzt wird. dbt lässt die Freiheit, ob zuerst das komplette Datenmodell durchspezifiziert wird oder ob pragmatisch und agiler – ggf. nach einem groben Zielmodell – die Modellierungsdetails erst während der Entwicklung entstehen.
Wir hoffen, Dir mit diesem Beitrag dbt in Kombination mit einer modernen Cloud-Datenbank etwas näher gebracht zu haben. Sprich uns an, wenn Du gerne weiter über Vor- und Nachteile von dbt oder Snowflake fachsimpeln möchtest oder Beratung beim rapiden Aufbau eines Data Hubs wünschst.

