







Architekturempfehlung und How-to Data Processing mit Azure Synapse Analytics. In diesem Beitrag geben wir zwei Architekturempfehlungen, zeigen, wie diese umgesetzt werden können und wie die Daten für die Visualisierung bereitgestellt werden.
Neben dem Data Ingest ist auch das Data Processing für viele Unternehmen im Industrial Internet of Things (IIoT) noch eine große Herausforderung. Wie Unternehmen erfolgreich IoT-Projekte umsetzen und wie ein erfolgreicher 6-Punkte-Plan aussieht, ist hier nachzulesen. Ein einfacher Start, industrielle Geräte an die Cloud anzubinden, wurde hier beschrieben. Dort ist aufgezeigt, wie Daten eines Industrieroboters mit IoT Central aus einem OPC-UA Server ausgelesen und mittels IoT Central in einem Azure Blob Storage gespeichert werden können.
In der Industrie wird die Nachfrage nach Cloud-Computing-Plattformen wie Microsoft Azure immer größer. Die dadurch ermöglichte Skalierbarkeit und der angebotene IoT Stack bieten eine schnelle Möglichkeit zum Ingest, Processing und Analysieren von industriellen Datenquellen wie SCADA und zum Anbinden verschiedener ERP- und MES-Systeme.
Azure Synapse Analytics
Microsoft Azure bietet eine Vielzahl an Services für die Verarbeitung von IoT-Daten. Die im zweiten Abschnitt aufgezeigten Architekturempfehlungen basieren auf Azure Synapse Analytics, einer zentralen Analyseplattform, die Data Ingestion, Data Processing, Storage und Visualisierung vereint. Neben der (Near-)Realtime-Datenverarbeitung mithilfe der Spark Pools und der Synapse Notebooks gibt es auch die Möglichkeit der Batchverarbeitung unter Verwendung von Synapse Pipelines. Ein weiterer Vorteil ist die Integration mit dem Azure Data Lake Storage und das Speichern der Daten im Delta-Format. Abschließend können die verarbeiteten Daten mithilfe der direkten Power-BI-Verknüpfung visualisiert werden.
Es gibt noch weitere Services, mit denen die IoT-Datenverarbeitung möglich ist. Auf diese wollen wir in unserem zweiten Blogbeitrag dieser Beitragsreihe eingehen. Dabei zeigen wir die Datenverarbeitung mit Azure Stream Analytics und eine serverlose Variante mit Azure Functions.
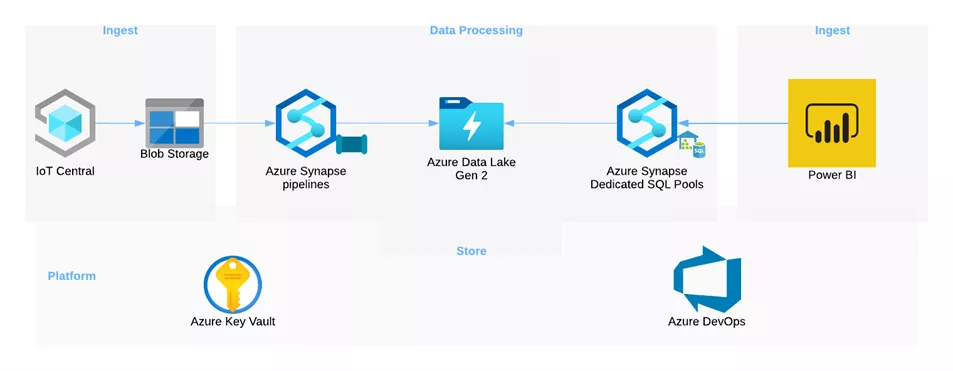
Batch Processing mit Azure Synapse Analytics
Die in einem Blob Storage gespeicherten Daten werden mithilfe von Azure Pipelines geladen, transformiert und in den Azure Data Lake Storage Gen2 geschrieben. Die hierfür erstellte Pipeline beinhaltet zwei zentrale Funktionen. Zum einen müssen die Spalten in die richtigen Datentypen umgewandelt werden, und zum anderen muss die Json-String-Spalte geparst werden. Mithilfe der bereitgestellten parseJson-Funktion werden die verschachtelten Spalten extrahiert und als einzelne Spalten in dem Dataset eingefügt.
Die transformierten Daten werden in dem Azure Data Lake Storage gespeichert und mithilfe von Synapse zur Visualisierung bereitgestellt.


Der Azure Dedicated SQL Pool bietet abschließend die Möglichkeit, mit einer View auf die Daten im Data Lake ein Power BI Dataset zu erstellen und eine kontinuierliche Aktualisierung von Reports vorzunehmen. Im Azure Synapse Portal kann unter „Verwalten“ ein Auslöser für die Pipeline gewählt werden. Für die Batchverarbeitung ist dort Use-Case-spezifisch ein Zeitplan einzustellen.
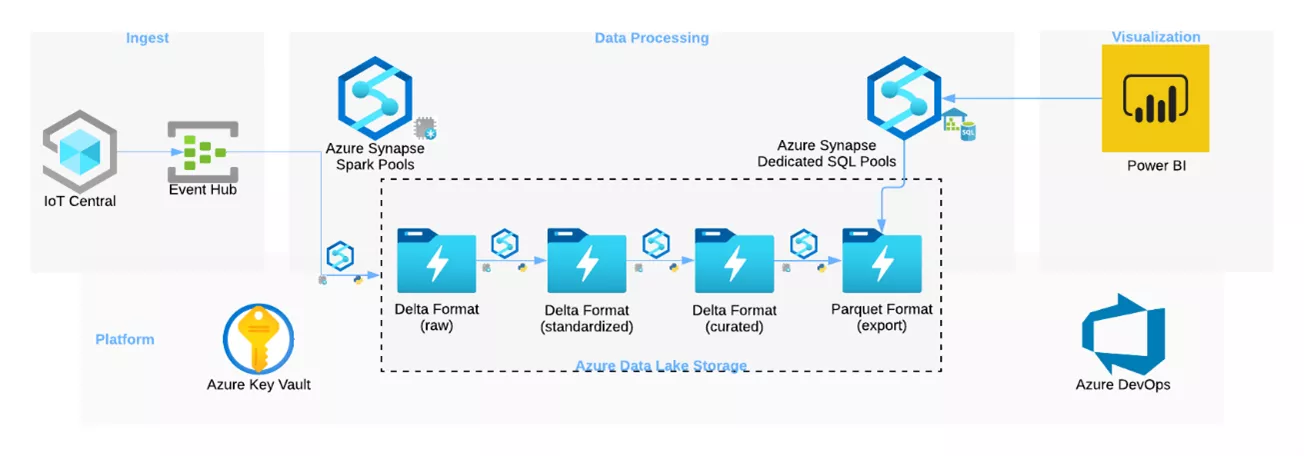
(Near-)Realtime Processing mit Azure Synapse Analytics
Als Alternative zum Batch Processing werden in diesem Anwendungsfall die Daten über den Azure Eventhub an Synapse weitergeleitet. Das Data Processing wird mithilfe von Spark Streaming und den Azure Spark Pools durchgeführt und ist in verschiedene Stages aufgeteilt. Ein zentraler Service ist der Azure Data Lake Storage Gen2, der das Write-once, Access-often Analytics Pattern in Azure abbildet. Als Speicherformat wird Delta verwendet, das eine höhere Ausfallsicherheit und Leistung für alle in ADLS gespeicherten Datenquellen bietet und sich somit sehr gut für die IoT-Datenverarbeitung anbietet.
Im ADLS werden die Daten in unterschiedliche Layer unterteilt:
- raw: Die Rohdaten werden im Delta-Format abgespeichert und es findet keine Transformation oder Anreicherung der Daten statt.
- standardized: Die Daten werden in ein standardisiertes Format gebracht und in einer übersichtlichen Struktur abgespeichert.
- curated: Es findet eine Anreicherung der Daten mittels weiterer Informationen statt.
- export: Die Daten werden für den Export und die weitere Verarbeitung vorbereitet.
Der abschließende export-Layer wird aufgrund der derzeit noch vorhandenen Limitation von externen Tabellen mit Azure Synapse Dedicated SQL Pools benötigt, weil diese das Delta-Format nicht lesen können (Azure-Dokumentation).
Die Verbindung zwischen dem Eventhub und dem ADLS Gen2 wird mithilfe von Spark Streaming hergestellt. Eine Voraussetzung dafür ist die Bereitstellung des Accesstokens in dem Azure Key Vault und die Abfrage mithilfe der mssparkutils.

Die weiteren Transformationen und Anreicherungen der Daten werden ebenfalls mit Spark Streaming durchgeführt. Dazu wird zunächst die in den Eventhub-Daten vorhandene Json-String-Spalte extrahiert und in einzelne Datenspalten aufgeteilt. Nach dieser Standardisierung wurden weitere KPIs berechnet, und der finale Datensatz wurde abgespeichert.
Die angereicherten Daten werden mittels eines Synapse Dedicated SQL Pools abgefragt und in einer externen Tabelle für Power BI bereitgestellt. Die gespeicherte Tabelle wird (Near-)Realtime upgedated und ermöglicht echtzeitnahe Einblicke in die Daten des Industrieroboters.
Ausblick
In dem nächsten Beitrag gehen wir auf zwei weitere Architekturen zum IoT Data Processing ein. Dabei zeigen wir euch die Umsetzung mithilfe von Azure Stream Analytics und Azure Functions. Abschließend werden wir in dem nächsten Teil auch das Power BI Dashboard zur Datenvisualisierung näher beleuchten und das Ergebnis des End-to-End Data Processings mit den empfohlenen Azure-Architekturen vorstellen.
Du willst den zweiten Teil des Blogbeitrags lesen? Hier gehts zu Teil 2.

