







Datenprodukte, die von vielen Nutzer:innen oder Domänen geteilt und genutzt werden, gelten als besonders wertvoll bzw. nützlich. Aber wie werden Daten zur Verfügung gestellt, geteilt und gemeinsam genutzt? Diese Frage wird unter anderem in diesem Blogbeitrag unter dem Stichwort „Data Sharing“ und mit Fokus auf technische Aspekte einer Data-Mesh-Architektur mit nativen AWS-Services beantwortet.
Was ist unter dem Begriff „Data Sharing“ zu verstehen?
Bislang hat sich in der Data-Community keine allgemeingültige Definition des Begriffs „Data Sharing“ etabliert, jedoch überschneiden sich Aspekte wie Empfängerkreis der geteilten Daten, Gegenstand des Teilens und Zweck des Teilens in den aktuell auffindbaren Definitionen. Dabei ist festzustellen, dass vor allem Softwarehersteller einen Vorschlag zur Definition des Begriffs veröffentlichen, sodass diese Definitionen eine technologische Färbung aufweisen.
Unter Rückgriff auf die wesentlichen Aspekte kann Data Sharing als ein Verfahren bezeichnet werden, bei dem Daten einem definierten Empfängerkreis zur weiteren Verarbeitung und Analyse zur Verfügung gestellt werden. Der Empfängerkreis kann dabei aus der internen Organisation (Teams, Abteilungen) oder auch aus externen Parteien über Unternehmensgrenzen hinweg bestehen. Auch Maschinen können in den Empfängerkreis einbezogen werden. Die Hauptziele von Data Sharing sind:
- die Förderung und Beschleunigung der Kollaboration zwischen verschiedenen Datenkonsument:innen
- die Reduzierung von Prozessaufwänden, wie z. B. das mehrfache Sammeln und Aufbereiten von Datensätzen
- die Benennung von Verantwortlichkeiten der Datenproduzent:innen gegenüber den Datenkonsument:innen
- die Förderung des Erkenntnisgewinns und ggf. Veredelung der eigenen Daten durch die Einbeziehung zusätzlicher Datenpunkte
Data Sharing mit Blick auf Data Mesh
Data Sharing bezeichnet das Bereitstellen von Daten für verschiedene Teams, Abteilungen oder sogar externe Organisationen. Data Mesh hingegen ist ein soziotechnisches Konzept, das darauf abzielt, die Herausforderungen der Skalierung von Organisationen in datenintensiven und komplexen Umgebungen zu bewältigen, hier kannst Du mehr dazu lesen. Setzt man die Ziele von Data Mesh (Skalierung von datenintensiven/komplexen Organisationen) und Data Sharing (Bereitstellung von Daten) in Beziehung, kann die Implementierung von Data Sharing als eine notwendige Komponente zur Erreichung des Data Meshs verstanden werden.
Je nach Zielsetzung einer Organisation kann jedoch Data Sharing auch ohne die Einführung einer Data-Mesh-Architektur umgesetzt werden. Unternehmen können zentralisierte Datenplattformen, Data Lakes oder Data Warehouses nutzen, um Data Sharing zu ermöglichen. In diesem Fall basiert Data Sharing auf einem traditionelleren, zentralisierten Ansatz für das Datenmanagement, bei dem ein dediziertes Datenteam für die Speicherung, Qualität und Zugänglichkeit der Daten verantwortlich ist.
Wie Amazon Web Services Data Sharing ermöglicht und Sharing Services im Data Mesh verortet
Im Laufe der Jahre hat Amazon Web Services (AWS) eine Reihe von Data Sharing Services eingeführt, mit denen Daten gespeichert, verarbeitet und vor allem gemeinsam genutzt werden können. Zu den bisher bekanntesten AWS-Diensten, die entweder eine direkte Möglichkeit zum Teilen von Daten bieten oder die gemeinsame Nutzung von Daten unterstützen, gehören AWS Data Exchange, Redshift Data Sharing und AWS Lake Formation. Neu hinzugekommen ist Amazon DataZone.
Es gibt verschiedene Möglichkeiten, die genannten Data Sharing Services einzusetzen – zum Beispiel im Data Mesh. Die folgende Abbildung zeigt eine Variante zur Umsetzung einer Data-Mesh-Architektur mit nativen AWS-Services auf. In dieser Architektur stellen Datenproduzent:innen ihre Daten über eine zentrale Governance-Plattform den Datenkonsument:innen zur Verfügung.
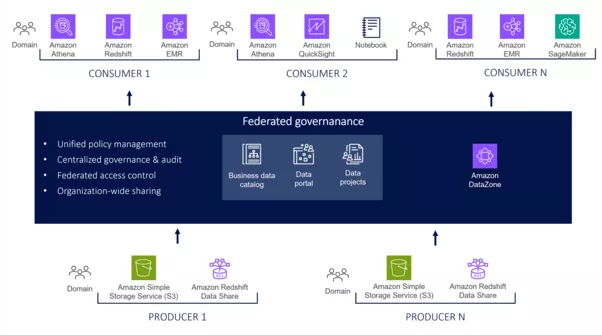
In Anlehnung an: https://aws.amazon.com/blogs/architecture/lets-architect-architecting-a-data-mesh/
Die oben genannten Sharing Services Redshift Data Sharing und Amazon DataZone sind in der aufgeführten AWS-Data-Mesh-Architektur aufgeführt. Obwohl AWS Lake Formation nicht explizit in der dargestellten Architektur aufgeführt ist, wird dieser Service als integrierter Service über Amazon DataZone genutzt. Die einzelnen Services und deren Rolle im Data Mesh werden im Folgenden beschrieben:
Redshift Data Sharing:
Redshift Data Sharing ist eine Art Freigabefunktion für Daten, die Teil des Amazon Redshift Data Warehouse Service ist. Diese Funktion ermöglicht Unternehmen die gemeinsame Nutzung von Daten (sogenannten Live-Daten) in Redshift-Clustern, ohne dass Daten kopiert oder verschoben werden müssen.
Mithilfe von Redshift Data Sharing kann im Data Mesh ein Datenprodukt anhand von Redshift-Clustern geteilt werden. Dabei muss eine Beziehung zwischen dem sogenannten Producer-Cluster und dem Consumer-Cluster hergestellt werden. Der Producer-Cluster ist der Cluster, der die Daten weitergibt, und der Consumer-Cluster ist der Cluster, der die gemeinsam genutzten Daten empfängt bzw. einen Zugriff auf die geteilten Daten erhält. Nach Erhalt der Zugriffsberechtigung auf die geteilten Daten können in dem Consumer-Cluster externe Tabellen erstellt werden, die auf die Daten im Producer-Cluster verweisen, um diese anschließend weiterzuverarbeiten.
AWS Lake Formation:
Mit AWS Lake Formation können Nutzer:innen auf einfache Weise Aufgaben erledigen, die mit der Erstellung und Verwaltung von Data Lakes verbunden sind. Beispiele sind die Einrichtung von Sicherheits- und Zugriffskontrollen, die Datenbereinigung und -normalisierung wie auch die Datenkatalogisierung.
In einer Data-Mesh-Architektur kann AWS Lake Formation verwendet werden, um einen Data Lake zu erstellen, der als Grundlage für die verschiedenen Domänen dient. Jede Domäne kann über AWS Lake Formation Zugriff auf den Data Lake sowie auf Redshift Data Shares erhalten. Durch die Definition von Richtlinien für den Datenzugriff kann gesteuert werden, auf welche Daten jede Domäne Zugriff hat, und es kann sichergestellt werden, dass nur die Teams Zugriff auf die Daten haben, die sie benötigen. Zusätzlich bietet AWS Lake Formation durch die Integration mit AWS Glue auch Funktionen zur Datenbereinigung und -transformation für den Erstellungsprozess von Datenprodukten.
Amazon DataZone:
Amazon DataZone ist ein Datenverwaltungsdienst, der bestehende Dienste und Funktionen wie AWS Glue und AWS Lake Formation nutzt. Der Dienst ermöglicht es Datenproduzent:innen, den Datenzugriff auf benutzerfreundliche Weise zu verwalten und zu regulieren, um Governance und Compliance auf skalierbare Weise umzusetzen. Data Producer oder Data Consumer können über die integrierte Datenanalyseplattform Daten abonnieren und Metainformationen einsehen wie auch Daten gemeinsam nutzen und analysieren.
In einer Data-Mesh-Architektur kann Amazon DataZone als integrierte und zentrale Plattform für Data Discovery, Zugriffskontrollen und Data Governance dienen. Domains können ihre Ressourcen wie qualitätsgesicherte Data Assets, AWS-Accounts und Datenquellen in einem speziell für sie geschaffenen virtuellen Raum verwalten. Darüber hinaus können Daten mit einem Geschäftskontext versehen werden, wodurch sie verständlich und auffindbar werden. Die Automatisierung der Veröffentlichung und Nutzung von Daten wird durch die Definition von Workflows unterstützt, um sicherzustellen, dass bei der Veröffentlichung und Nutzung der Daten die festgelegten Zugriffsrechte eingehalten werden. Zudem ermöglichen Amazon-DataZone-Projekte es den Nutzer:innen, virtuelle, isolierte Bereiche zu schaffen, in denen eine Gruppe von Nutzer:innen mithilfe von freigegebenen Analyse-Tools an definierten Datenbeständen Analysen durchführen können.
Ob traditionelle, zentrale Datenplattform oder Data Mesh – bei der Umsetzung von Data-Sharing-Ansätzen stehen Kunden häufig vor technischen wie auch organisatorischen Herausforderungen, wie beispielsweise die Ausrichtung von Prozessen und Verantwortlichkeiten nach SLAs geteilter Daten, Sicherstellung des Datenschutzes, Interoperabilität und Datenqualität. Hierbei können wir Dich unterstützen und die Zusammenarbeit und den Erkenntnisgewinn in Deiner Organisation fördern. Kontaktiere uns gerne für ein unverbindliches Erstgespräch!
Wir freuen uns auf das Gespräch mit Dir

