







Hast Du schon mal darüber nachgedacht, wie die ideale Cloud-Data-Platform-Architektur aussehen sollte? Wir schon! In unserer kostenlosen Online-Event-Reihe Data Firework Days haben wir die b.telligent Referenzarchitektur für Cloud-Datenplattformen vorgestellt, einen Blueprint für den Aufbau einer erfolgreichen Datenplattform für Deine Analytics-, KI-/ML- oder DWH-Anwendungsfälle. Und wir sind noch einen Schritt weiter gegangen. Da wir alle wissen, dass es da draußen nicht die „eine“ Cloud gibt, haben wir unser Modell auch für die drei großen Cloud-Anbieter – Google Cloud Platform, AWS und Azure – adaptiert. In dieser Blogserie wollen wir in den ersten beiden Beiträgen zunächst unsere Referenzarchitektur beschreiben und uns dann, in den Teilen 4 bis 6, mit den Implementierungsmöglichkeiten für die einzelnen Anbieter beschäftigen. Los geht‘s, begleite uns auf unserer Reise durch die Cloud.
Sieben Wochen, sechs Themenbereiche, sechs Formate - wir zünden ein Datenfeuerwerk!
Interaktive Webinare, spannende Tool-Battles, Roundtables und Interviews mit Vordenkern der Digitalbranche: Das warendie Data Firework Days von b.telligent. Wir haben einen Blick auf die Themen geworfen, die den Puls der Digitalisierung in die Höhe treiben: Von Data Science über Cloud und DWH Automation bis hin zu Reporting, Data Governance und allem rund um Customer Intelligence.
Um ein gemeinsames Verständnis einer Cloud-Architektur zu schaffen und einen ersten Blick auf die Grundlagen zu werfen, beginnen wir mit einer High-Level-Übersicht der Referenzarchitektur. Wie Du sehen kannst, haben wir unser Referenzmodell auch visuell in verschiedene Bereiche unterteilt. Jedem der grau unterlegten Hauptbereiche – Ingestion, Data Lake, Analytics-Plattform und Zentrale Dienste – werde ich einen kurzen Beitrag widmen, in dem ich die einzelnen Elemente und deren Zusammenhänge und Funktionen beschreibe. Beginnen wir mit der Ingestion, der Datenaufnahme, bevor wir dann einen Blick auf die Bereiche Data Lake (Persistence) und Analytical Platform werfen.
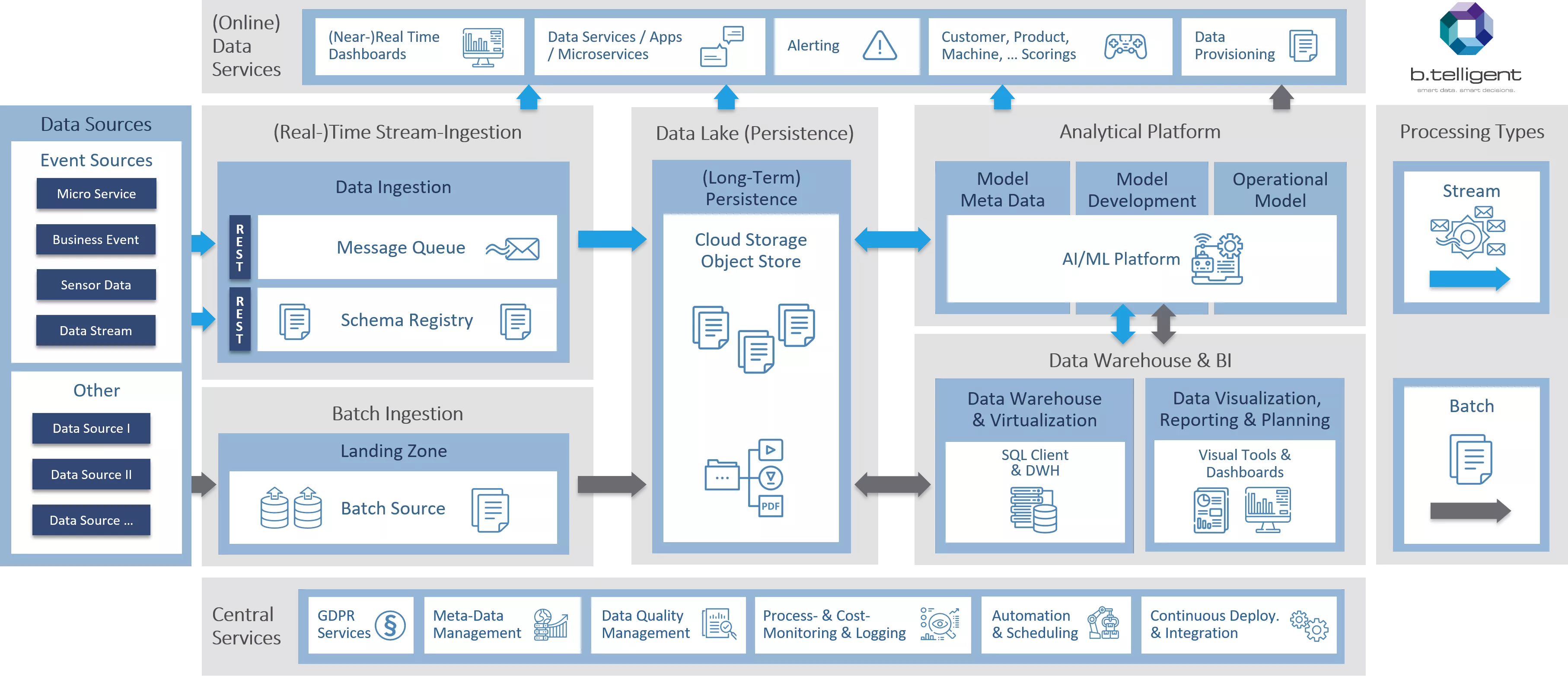
Immer herein mit den Daten: Ingestion
In einer typischen Kundenumgebung stoßen wir in der Regel auf viele separate Datensilos, die sich im Laufe der Zeit fast exponentiell vermehrt haben. Wir stellen zum Beispiel fest, dass einzelne Abteilungen im Unternehmen unterschiedliche Technologien verwenden und jeweils ähnliche, wenn nicht sogar die gleichen Datensätze zur weiteren Verarbeitung in ihr jeweiliges Silo kopieren müssen. In Kombination mit operativen Systemen, die das Tagesgeschäft der Kunden unterstützen (z. B. POS, IoT oder Banktransaktionen), der zunehmenden Vielfalt an Daten (wie Videoüberwachung von Geschäften, Produktbilder oder gescannte PDF-Dokumente) und der Geschwindigkeit, mit der die Daten generiert werden, resultiert daraus die Notwendigkeit, dass Echtzeit- und Batch-Ingestion-Kanäle nebeneinander existieren.
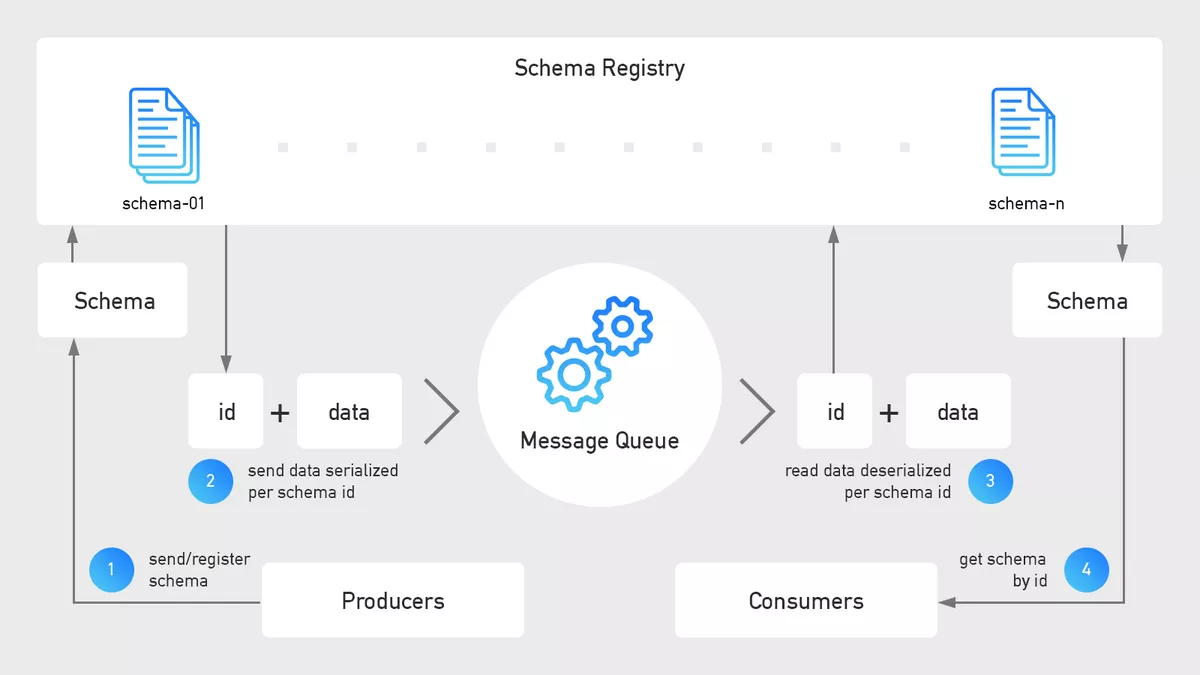
Message Queues sind das Rückgrat der Echtzeit-Ingestion. Sie ermöglichen das Einfügen von Ereignissen mit geringer Latenz von einer potenziell großen Anzahl von Eingabegeräten/-systemen (z. B. Sensoren in PKWs), das Speichern der Ereignisse für eine bestimmte Zeitspanne und das Weiterleiten der Ereignisse zur Echtzeitverarbeitung. Must-have-Funktionen solcher Warteschlangen sind Skalierbarkeit (z. B. zum Weihnachtsgeschäft oder dem Black Friday), Langlebigkeit (die Fähigkeit, Ausfälle in einer Zone oder Region zu kompensieren) und Geofencing (die Speicherung von Daten am bevorzugten geografischen Standort aus [datenschutz]rechtlichen und Compliance-Gründen). Darüber hinaus müssen wir Kriterien wie die Unterstützung von Exactly-once-Verarbeitung (eine Banktransaktion darf nur einmal verarbeitet werden), Reprocessing (die Fähigkeit, Ereignisse auf Anforderung wiederzugeben), Ordering (Abhängigkeit von der Reihenfolge der Ereignisse), Verschlüsselung usw. einer sorgfältigen Bewertung unterziehen.
Da wir die eingehenden Daten in zahlreichen Systemen unserer Datenpipeline verarbeiten, ist eine ordnungsgemäße Schemaverwaltung unerlässlich. Die Daten müssen auf die gleiche Weise behandelt werden, unabhängig davon, ob wir sie für unsere Frontend-Apps oder innerhalb unserer KI-/ML-Plattform verarbeiten. Dies ist umso wichtiger, wenn man bedenkt, dass sich die Struktur, Qualität und andere Parameter der eingehenden Daten im Laufe der Zeit ändern. Mit anderen Worten: Ein aktualisiertes Schema in den Quellsystemen darf nicht zu Ausfällen in nachgelagerten Systemen führen. Die Schema-Registry ermöglicht eine versionierte Schemaverwaltung und -evolution sowie zusätzliches Tagging (wie DSGVO) und vieles mehr.
Beachte, dass in der am Anfang dieses Artikels dargestellten Referenzarchitektur sowohl der Message Queue als auch der Schema-Registry die RESTful-Schnittstelle vorangestellt ist. Da wir Protokolle gegenüber spezifischen Tools bevorzugen, wird anstelle von nativen Clients die REST-API verwendet.
Batch-Quellen werden am besten durch Batch Ingestion bedient, da sie typischerweise regelmäßig (wie beispielsweise der tägliche DWH-Export) oder nach Bedarf (wie im Fall einer Abteilung, die einen einmaligen Datensatz lädt) geplant werden. Ein skalierbarer und hochbeständiger Storage Service ist die bevorzugte Wahl, um strukturierte, halbstrukturierte und unstrukturierte Daten an einem Ort zu speichern und so das oben beschriebene Problem der Datensilos zu vermeiden. Wir empfehlen Funktionen wie Geofencing, Speicherklassen (Unterscheidung zwischen Hot und Cold Storage), Objektlebenszyklusmanagement (automatischer Wechsel der Speicherklasse nach einem bestimmten Zeitraum), Versionierung, Unterstützung für den Umgang mit statischen Inhalten (beispielsweise statische Inhalte für Web-Anwendungen), Encryption-at-rest, detaillierte Sicherheitsrichtlinien usw.
So weit zu unseren Ausführungen zum Ingestion-Teil unserer Referenzarchitektur für Cloud Data Platforms. Wenn Du tiefer in das Thema einsteigen möchtest, dann lies Dir gerne die weiteren Teile dieser Blogserie durch, in denen wir weitere Bereiche der Architektur in Augenschein nehmen! Solltest Du Fragen haben, wende Dich einfach an unsere Cloud-Experten – sie freuen sich darauf, von Dir zu hören!

