





Nachdem wir im ersten Teil dieser Blogserie über die Konzeption und das Handling von Metadaten in Matillion mit Grid-Variablen gesprochen haben, werfen wir nun einen genaueren Blick auf die Frage: Wie nutze und operationalisiere ich diese Daten nun?
Schritt 3: Metadatennutzung
Nun wollen wir uns auch die konkrete Nutzung der erstellten Metadaten anschauen. Sie verbirgt sich einerseits im Step „stage data“ des Hauptjobs „Source2ODS“ und andererseits in den drei Transformationen „stage2ods_diff“, „stage2ods_update“ und „stage2ods_insert“. Schauen wir uns zunächst das Staging der Quelldaten etwas genauer an.
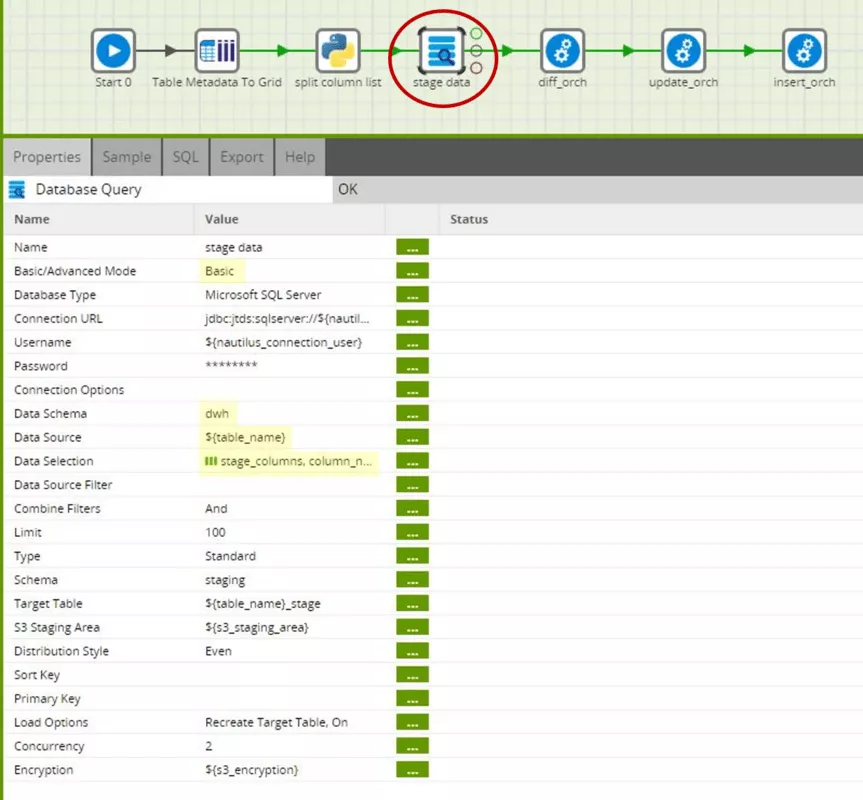
Wir benutzen hier die Komponente Database Query in ihrer Basisversion. Dies bedeutet, dass Schema und Name der Quelltabelle sowie die zu ladenden Spalten separat ausgewählt werden bzw. wie in unserem Anwendungsfall über Variablen gesetzt werden. Im Advanced Mode kann der Komponente auch ein SELECT-Statement übergeben werden. Für uns reicht der Basic Mode hier aber vollkommen aus.
Im Parameter Data Source verwenden wir wieder die Job-Variable „table_name“. Im Parameter Data Selection verwenden wir die Spalte „column_name“ der Grid-Variablen „stage_columns“. Die Komponente liest also nur die Spalten der Quelltabelle, die in der Grid-Variablen „stage_columns“ eingetragen sind. Da die Grid-Variable „stage_columns“ aus den Metadaten der ODS-Tabelle „${table_name}_hist“ abgeleitet wurde, werden also nur die Spalten gelesen, die auch tatsächlich für die ODS-Tabelle benötigt werden. In der Quelltabelle können nun beliebig Spalten ergänzt und gelöscht werden, solange sie nicht in der ODS-Tabelle vorkommen – und selbstverständlich muss der Primärschlüssel konstant bleiben.
Die übrigen Parameter beziehen sich auf die technische Connection zur Datenquelle sowie die von Matillion und Redshift benötigte temporäre Zwischenspeicherung der Daten in einem S3 Bucket. Diese Parameter sind für den Fokus dieses Artikels aber nicht relevant.
Bei der Delta-Erkennung werden Grid-Variablen an verschiedenen Stellen der Transformation genutzt.
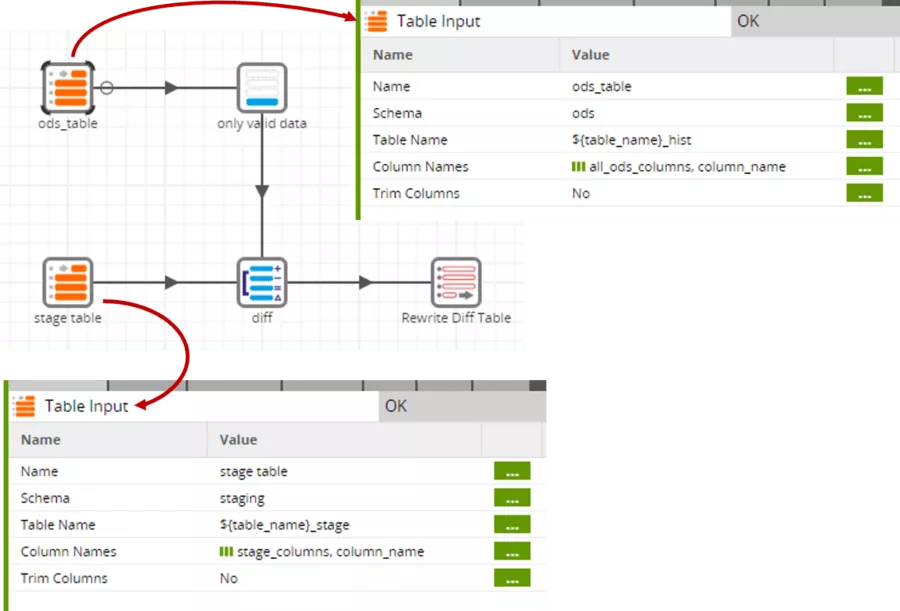
Wie bereits bei den Parametern Data Source und Data Selection des Staging-Schrittes werden auch bei den Table-Input-Komponenten Variablen genutzt. Da die ODS-Tabelle etwas breiter ist als die Stage-Tabelle – nämlich zusätzlich „valid_from“ und „valid_to“ enthält –, werden hier unterschiedliche Grid-Variablen verwendet.
Da die Komponente Table Input keine direkte Filtermöglichkeit bietet, benötigen wir noch den expliziten Filter „only valid data“, der auf die aktuell gültigen Datensätze (valid_to gleich ‚2999-12-31‘) einschränkt. Nur diese Datensätze sind für den Vergleich relevant.
Im eigentlichen Delta Step werden sogar gleich drei Grid-Variablen genutzt.
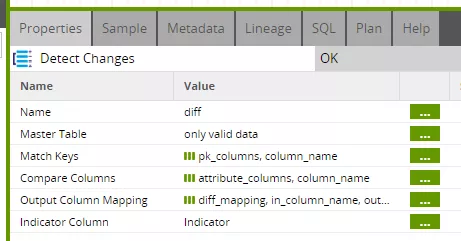
Hier benötigen wir zum einen die Liste der Schlüsselattribute („pk_columns“) sowie die Liste der Vergleichsattribute („attribute_columns“) und zum anderen das Mapping beider Eingangstabellen zum Output der Komponente („diff_mapping“).
Die Komponente führt quasi einen Full Outer Join zwischen den Eingangstabellen aus und markiert den Ergebnisdatensatz mit dem Resultat des Vergleiches:
- I identical beide Datensätze sind identisch
- C changed beide Datensätze unterscheiden sich
- N new der Datensatz ist neu
- D deleted der Datensatz wurde gelöscht
Da wir im Mapping zusätzlich zu den Schlüsselattributen und den Vergleichsattributen auch die Spalte „valid_from“ aus der ODS-Tabelle mitgenommen haben, können wir diese im Folgeschritt verwenden, was es uns dort deutlich leichter macht.
Der abschließende Step „Rewrite Table“ sichert das Ergebnis des Vergleiches in einer Zwischentabelle. Diese wird bei jedem Prozessdurchlauf neu erstellt (überschrieben). Sie besteht aus allen Spalten des Inputdatenstroms und benötigt daher keine explizite Spaltenliste.
Die Update-Transformation sieht auf den ersten Blick recht einfach aus.

Die Table-Input-Komponente bezieht sich nun auf das ermittelte Delta. Als Spaltenliste wird die Grid-Variable „diff_columns“ verwendet. Hierbei ist aber interessant, noch einmal genau zu schauen, welche Spalten nun wirklich enthalten sind (vgl. Schritt 2 in Teil 1 des Beitrags).
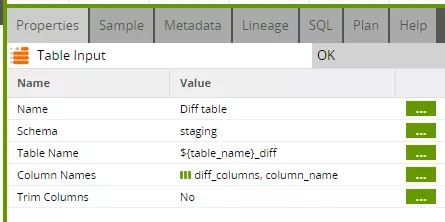
Der Hauptjob hat dem update-Job beim Aufruf als „diff_columns“ nur die „pk_columns“ übergeben, also die Liste der Schlüsselattribute. Der update-Job hat dieser Liste dann die Spalten „valid_from“ und „indicator“ hinzugefügt, bevor er die Variable an die Transformation weitergegeben hat. Die übrigen Spalten werden zum Update des „valid_to“-Datums nicht benötigt und brauchen daher erst gar nicht aus der Diff-Tabelle gelesen zu werden.
Der Filter sorgt dafür, dass das „valid_to“-Datum nur bei gelöschten oder geänderten Datensätzen gesetzt wird.
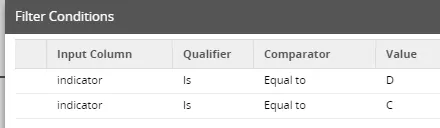
Im Calculator Step wird der zu setzende Wert für „valid_to“ festgelegt. Im Beispiel benutzen wir hierfür die Redshift-Funktion „getdate()“, die das jeweils aktuelle Datum zurückliefert.
Zum Schluss bleibt noch das eigentliche Update, das wieder über Grid-Variablen gesteuert wird.
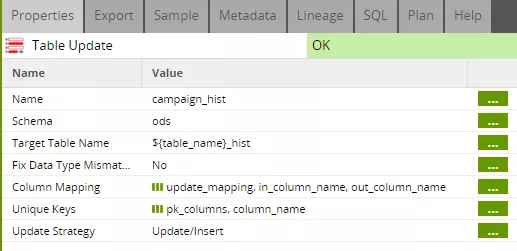
Hier benötigen wir zunächst ein Mapping zwischen den Eingangsspalten der Komponente und den Spalten der Zieltabelle. Da wir unsere Spaltennamen initial aus der ODS-Tabelle, also der Zieltabelle des Updates, entnommen haben, sind die Spaltennamen jeweils identisch. Dennoch verlangt die Komponente ein explizites Mapping, das im update-Job erstellt wird (siehe Schritt 2). Außerdem benötigt die Komponente die Liste der Schlüsselattribute, die wir in der Grid-Variablen „pk_columns“ abgelegt haben. Hier ist nun auch die Spalte „valid_from“ enthalten, um sicherzustellen, dass nur die jeweils aktuelle Version eines Datensatzes gefunden und verändert wird. Diese Ergänzung der „pk_columns“ wurde ebenfalls im update-Job vorgenommen (siehe Schritt 2).
Die Insert-Transformation sieht auf den ersten Blick der Update-Transformation zum Verwechseln ähnlich.

Die Table-Input-Komponente ist sogar exakt identisch parametrisiert, allerdings enthält die Grid-Variable „diff_columns“ hier die vollständige Spaltenliste – außer „valid_from“.
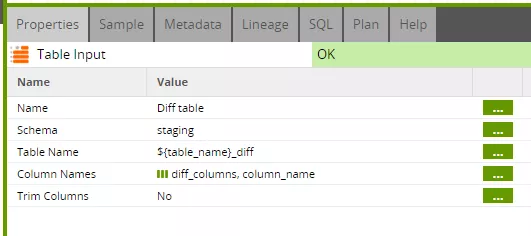
Der Filter sorgt dafür, dass nur neue oder geänderte Datensätze eingetragen werden.
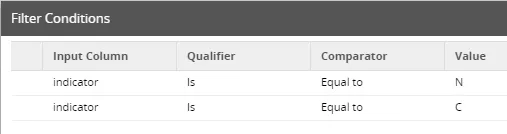
Im Calculator Step wird diesmal die Funktion „getdate()“ als Wert für „valid_from“ genutzt, während „valid_to“ auf den Standardwert ‚2999-12-31‘ gesetzt wird.
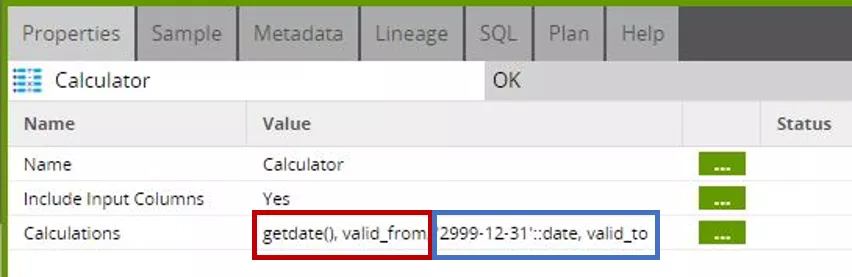
Die abschließende Output-Komponente verlangt wieder ein Mapping der Spaltennamen zwischen dem Input der Komponente und der Zieltabelle. Wir verwenden hier die im insert-Job erstellte Grid-Variable „insert_mapping“ (siehe Schritt 2).
Schritt 4: Operationalisierung
Bisher haben wir hier nur den Ladeprozess für eine einzelne Quelltabelle betrachtet. Um diesen nun auf ein ganzes Quellsystem anzuwenden, muss lediglich der Hauptjob „Source2ODS“ mehrfach mit den verschiedenen Tabellennamen aufgerufen werden. Hierzu bietet Matillion verschiedene Iterator-Komponenten.
Wir haben uns hier für den Einsatz des Grid-Iterators entschieden. Dieser Iterator ruft den Job „Source2ODS“ so oft auf, wie Zeilen in der Grid-Variablen vorkommen. Die Werte in den einzelnen Zellen des Grid können dann beim Aufruf als Übergabeparameter verwendet werden.
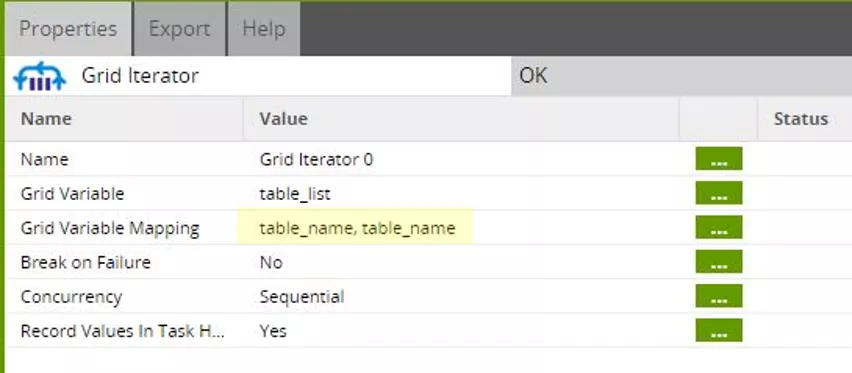
Wir verwenden hier die Grid-Variable „table_list“ und weisen den Wert der Spalte „table_name“ einer skalaren Variablen „table_name“ zu.
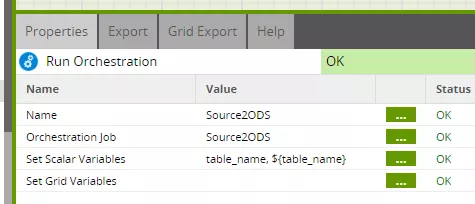
Die Variable „table_name“ wird wiederum als Aufrufparameter für den Job „Source2ODS“ verwendet, hier konkret an die Job-Variable „table_name“ übergeben.
Die Grid-Variable „table_list“ befüllen wir über eine gezielte Query auf die Metadatenview „svv_table_info“.
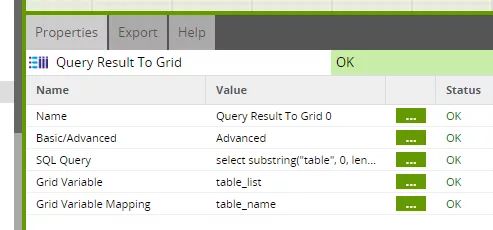

Damit haben wir nun einen einzigen Job für die automatische Befüllung unseres Operational Data Store. Neue Spalten und sogar neue Tabellen können einfach im Zielschema angelegt werden und werden bei der nächsten Beladung automatisch befüllt – ganz ohne Änderung des ETL-Prozesses.
Mit dieser kleinen Anleitung kannst Du die technische Beladung Deines DWH und die Historisierung der Quelldaten vollständig automatisieren. Dadurch gewinnst Du viel Zeit, um Dich um die wirklich wichtigen Aufgaben im Data Warehousing zu kümmern – nämlich fachlichen Mehrwert für Deine Nutzer zu schaffen!
Du hast Fragen zum Thema oder möchtest mehr über Matillion erfahren? Ich freue mich auf den Austausch!

