





Parametrisierung der Ladejobs über Variablen ist längst nichts Besonderes mehr: Alle gängigen ETL-Tools bieten heute entsprechende Möglichkeiten, um Jobs an unterschiedliche Umgebungen (Dev/Test/Produktion) anzupassen. Neben klassischen skalaren Variablen zeigen wir Dir in diesem Blogbeitrag die Nutzung eines noch viel mächtigeren Konzepts: sogenannter Grid-Variablen.
Mit diesen lassen sich in Matillion, einem Anbieter von Cloud Analytics Software mit Sitz in London, gleichartige Jobs sehr einfach generalisieren und auf eine Vielzahl von Objekten anwenden. Somit entspricht die Implementierung weniger einem einzigen ETL-Job, sondern ähnelt vielmehr einem Framework. Wir wollen dies am Beispiel eines Operational Data Store (ODS) näher betrachten. Die ersten beiden Schritte, Konzeption und das Handling von Metadaten, werden in diesem Teil des Blogbeitrags genauer dargestellt. Für Schritt 3 und 4, in denen wir uns die Nutzung der Metadaten und das Thema Operationalisierung ansehen, empfehle ich Dir Teil 2 dieses Beitrags.
Los geht’s: Aufgabenstellung ist die Befüllung eines SCD2-historisierten ODS. Die Prozesse sollen hierbei durch die Struktur der ODS-Tabellen gesteuert werden. Wir gehen für dieses Beispiel von einem Full Load aus, es lässt sich aber sehr leicht auf einen Delta Load anpassen.
Schritt 1: Konzeption
Bevor wir mit der konkreten Implementierung beginnen, schauen wir uns zunächst den grundsätzlichen Ablauf des Ladeprozesses an. Daraus wird ersichtlich, welche Informationen wir zur Steuerung des Prozesses benötigen. Außerdem definieren wir einige Namenskonventionen.
Wir legen zunächst fest, dass die Tabellen im ODS den gleichen Namen tragen wie im Quellsystem, jedoch um den Zusatz „_hist“ erweitert. Außerdem sollen die Namen der Spalten zwischen Quelltabelle und ODS-Tabelle identisch sein. Zur Historisierung führen wir im ODS die Spalten „valid_from“ und „valid_to“ ein. Hier speichern wir gemäß SCD2-Definition den Beginn und das Ende der Gültigkeit auf Tagesbasis. „valid_from“ wird hierbei inklusiv verstanden, während „valid_to“ exklusiv zu verstehen ist. Auf weitere Spalten zur Historisierung wie Aktualisierungskennzeichen oder Versionszähler verzichten wir hier. Sie könnten aber leicht eingefügt werden.
Die Beladung erfolgt grundsätzlich in vier Schritten:
- Staging der Quelldaten
- Vergleich der Daten in Staging mit dem Datenstand im ODS
- Setzen des „valid_to“-Datums für geänderte und gelöschte Datensätze
- Einfügen der geänderten und neuen Datensätze
Für das Staging der Quelldaten müssen wir wissen, welche Tabelle und welche Spalten geladen werden sollen. Wir benötigen also eine Variable, die den Tabellennamen, und eine Variable, die die Liste der Spaltennamen enthält. Letzteres werden wir mit einer Grid-Variablen realisieren. Es werden alle Spalten benötigt, die in der korrespondierenden ODS-Tabelle existieren – mit Ausnahme von „valid_from“ und „valid_to“, die es in der Quelltabelle ja nicht gibt.
Um die geladenen Daten mit dem aktuellen Datenstand vergleichen zu können, benötigen wir erneut den Tabellen- und die Spaltennamen. Diesmal müssen wir aber zwischen Schlüsselattributen und beschreibenden Attributen unterscheiden. Um die Schlüsselattribute erkennen zu können, ist es unbedingt erforderlich, auf den ODS-Tabellen einen Primärschlüssel zu definieren. Zudem benötigen wir ein Mapping, das definiert, ob wir die alten oder neuen Attributwerte (oder beide) in die Ergebnisdatensätze übernehmen wollen.
Unser Anwendungsfall „ODS“ erfordert für alle beschreibenden Attribute nur die neuen Werte. Zusätzlich bedarf es aber auch des Wertes der Spalte „valid_from“ aus dem alten, d. h. dem aktuell noch gültigen, Datensatz, um den vollständigen Primärschlüssel für die folgende Update-Operation bilden zu können.
Zum Setzen des „valid_to“-Datums wird neben dem Tabellennamen noch der Primärschlüssel der betroffenen Datensätze benötigt. Dieser muss nun zwingend die Spalte „valid_from“ beinhalten, da sonst alle historisierten Versionen eines Datensatzes mit dem gleichen „valid_to“ versehen werden würden. Zum Einfügen der neuen Datensätze brauchen wir außer dem Tabellennamen noch die volle Spaltenliste der ODS-Tabelle.
Schritt 2: Metadatenhandling mit Grid-Variablen
Nachdem wir nun alle benötigten Metadaten identifiziert haben, müssen wir uns um deren Beschaffung kümmern. Wir beginnen mit dem äußeren Orchestration Job, den wir „Source2ODS“ nennen. Den Namen der zu prozessierenden Tabelle lassen wir uns ganz einfach von außen als Aufrufparameter übergeben. Dazu definieren wir eine Job-Variable „table_name“ vom Typ Text und geben ihr einen Default-Wert. Letzterer wird eigentlich nicht benötigt und kann später entfernt werden, hilft aber enorm während der Entwicklungsphase. Durch den Default-Wert können wir den Job während der Entwicklung direkt starten, ohne einen aufrufenden Job zu benötigen, der den „table_name“ explizit setzt.

Da wir nun den Namen der zu prozessierenden Tabelle kennen, können wir uns mittels der Komponente „Table Metadata to Grid“ die Metadaten der Tabelle in eine Grid-Variable laden.
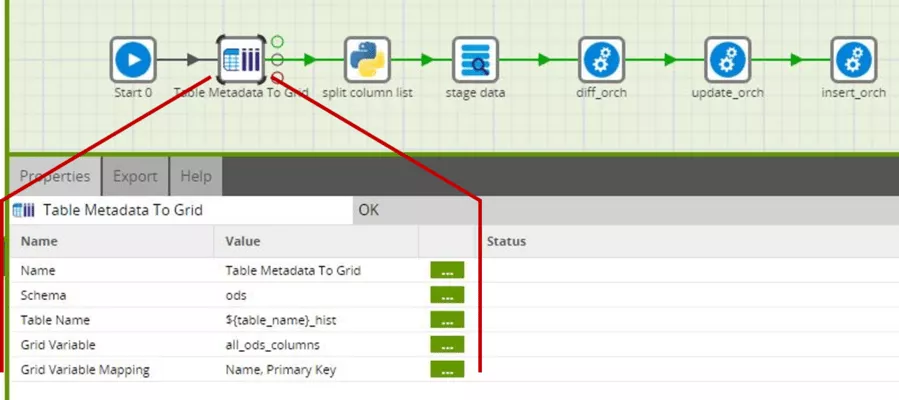
Alle unsere ODS-Tabellen liegen im Schema ods, daher wählen wir dieses Schema aus. Wer hier mit mehreren Schemata arbeiten möchte, kann den Namen des Schemas analog zum Tabellennamen ebenfalls als Variable von außen übergeben lassen. Beim Tabellennamen referenzieren wir mit der Notation ${…} den Wert einer Variablen, hier der Variablen „table_name“. Den darin gespeicherten Text können wir direkt (ohne Konkatenierungsoperator oder Ähnliches) mit dem Suffix „_hist“ erweitern und erhalten so den Namen der ODS-Tabelle (siehe Namenskonvention aus Schritt 1).
Bevor wir die zu befüllende Grid-Variable „all_ods_columns“ an dieser Stelle auswählen können, müssen wir diese definieren.
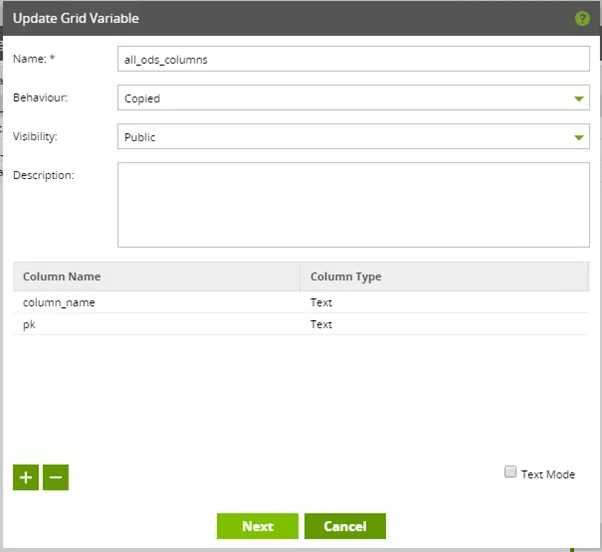
Die Grid-Variable „all_ods_columns“ kann man sich als Tabelle mit zwei Spalten vorstellen, nämlich „column_name“ und „pk“. Beide sind vom Typ Text, wobei „pk“ eigentlich als Flag zu interpretieren ist. In dieser Spalte bedeutet der Wert „Yes“, dass die jeweilige Spalte zum Primärschlüssel der ODS-Tabelle gehört. „No“ bedeutet, dass sie nicht dazu gehört.
Mit dem Grid-Variablen-Mapping legen wir schließlich fest, welche Metadaten in welche Spalte der Grid-Variablen geschrieben werden.
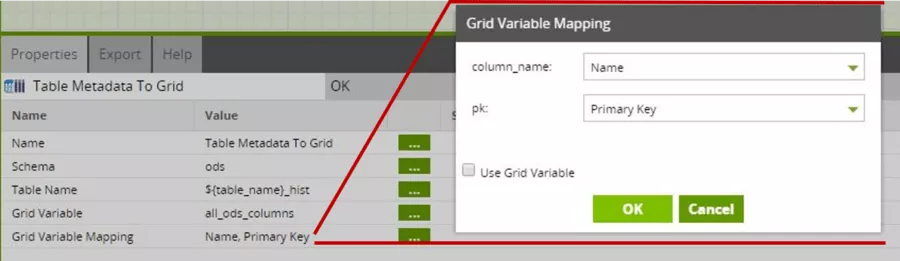
Die Matillion-Komponente stellt hierbei sicher, dass bei „Primary Key“ ausschließlich die Werte „Yes“ und „No“ vorkommen.
Wie in Schritt 1 beschrieben, benötigen wir aber nicht nur die Metadaten der ODS-Tabelle, sondern müssen aus diesen Metadaten eine Reihe verschiedener Spaltenlisten ableiten. Dazu stellt Matillion ein paar Komponenten zur Erweiterung oder Reduzierung von Grid-Variablen zur Verfügung.
Diese Komponenten benutzen wir hier jedoch nicht. Wir verwenden stattdessen die Python-Skript-Komponente, mit der wir die Grid-Variablen wesentlich flexibler und letztlich einfacher verändern können.
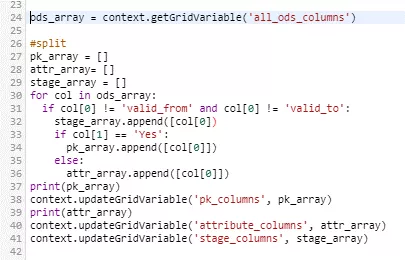
Zunächst wird hier die Grid-Variable „all_ods_columns“ als Liste von Listen ausgelesen. Das resultierende Array wird danach durchprozessiert und letztlich jeder Spaltenname außer den Historisierungsspalten „valid_from“ und „valid_to“ in die Liste der Stage-Spalten sowie abhängig von der PK-Eigenschaft in die Liste der PK-Spalten oder beschreibenden Attribute kopiert. Abschließend werden eigene Grid-Variablen mit Hilfe dieser Listen initialisiert. Die verwendeten Grid-Variablen müssen wieder vorab definiert worden sein.
Die so erstellten Grid-Variablen übergeben wir auch an die jeweiligen Subjobs, die sich um die Delta-Erkennung, das Update der „valid_to“-Zeitstempel sowie das Einfügen der neuen Datensätze kümmern. Dies ist bei Grid-Variablen etwas umfangreicher als bei skalaren Variablen. Eine disziplinierte Namensgebung ist hier dringend zu empfehlen, da man sonst schnell den Überblick verliert.
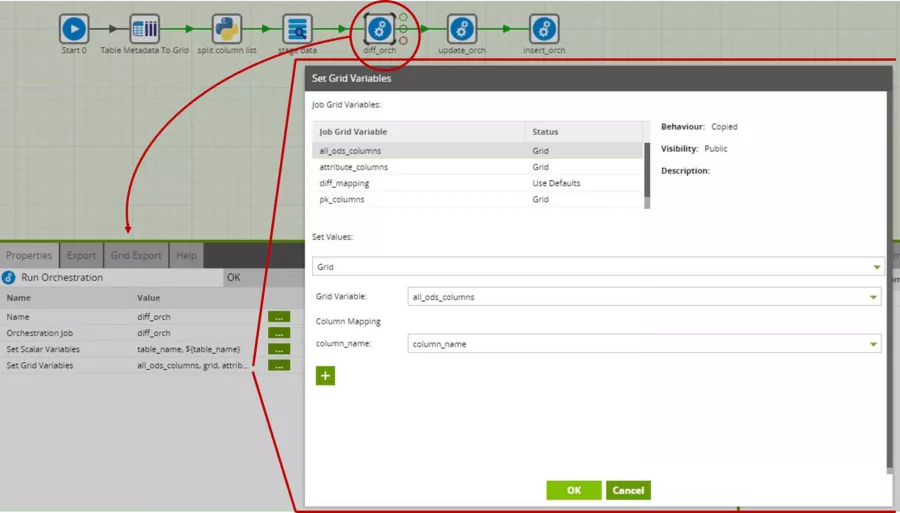
Die Subjobs bauen sich nun selbst eventuell benötigte weitere Spaltenlisten und Mappings aus den übergebenen Listen zusammen.
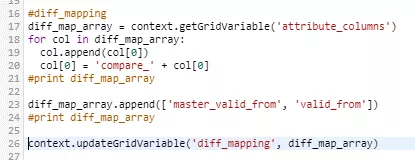
Der Job zur Erkennung des Deltas benötigt beispielsweise ein Mapping von den Input-Spalten der beiden zu vergleichenden Tabellen zum gewünschten Output der Diff-Komponente. Dieses wird vom obigen Python-Code erzeugt und in der – zuvor zu definierenden – Grid-Variablen „diff_mapping“ hinterlegt.
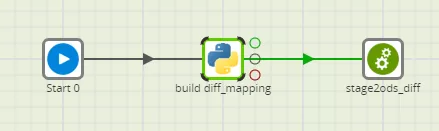
Analog wird im update-Job ein „update_mapping“ und im insert-Job ein „insert_mapping“ erstellt, wobei der jeweilige Python-Code dem obigen Codebeispiel sehr ähnlich ist.


Wie Konzeption und Handling von Metadaten mit Grid-Variablen funktionieren, weißt Du jetzt. Solltest Du noch Fragen zum Thema haben, stehe ich Dir gerne für einen Austausch und weitere Einblicke zur Verfügung. Mehr zur Nutzung der Grid-Variablen und zur Operationalisierung zu einer kompletten Ladestrecke erfährst Du in Folge 2 dieser Blogserie.