





Kausalität – Begegnungen im Alltag, Business Intelligence und AI
Das Thema Kausalität ist in der Machine-Learning- und Data-Science-Community derzeit stark im Gespräch. Erst letztes Jahr erörterte Judae Pearl, einer der bekanntesten Forscher auf dem Gebiet Bayesscher Netze, in seinem „Book of Why“, dass das Verständnis von Kausalität die Zukunft künstlicher Intelligenz prägen wird. Auch der Begriff „Prescriptive Analytics“, als Abgrenzung oder weiterer Schritt nach „Predictive analytics“, ist gerade in aller Munde. Das Verständnis kausaler Zusammenhänge ist auch hier unverzichtbar.

Abbildung 1: Ist die Straße nass, weil es regnet, oder regnet es, weil die Straße nass ist?
Kausalität lässt sich überall in unserer Welt finden, etwa in ganz alltäglichen Erfahrungen: Wenn es regnet, werden Straßen nass. Auch in der Business-Intelligence-Welt können wir von einem besseren Verständnis kausaler Zusammenhänge profitieren: Um zu entscheiden, in welchem Werbekanal ein begrenztes Marketingbudget am besten angelegt ist, sollten wir die Auswirkungen der Werbemaßnahmen möglichst gut kennen. Bei diesen Beispielen können wir logisch argumentieren, warum die eine Größe von der anderen abhängen sollte. Was ist nun aber, wenn solche Informationen nicht zur Verfügung stehen? Oder wenn wir einfach gar nichts über die beobachteten Variablen wissen? Dieses Problem wird als kausale Inferenz (bei zwei Variablen) bezeichnet:
Zwei Zufallsvariablen X und Y stehen in einer kausalen Beziehung miteinander, so dass entweder X —> Yoder Y —> X gilt. Ausgehend von Beobachtungen x, y der beiden Zufallsvariablen, ist die kausale Richtung X —> Y oder Y —> X?

Abbildung 2: Verschiedene kausale Strukturen im Zwei-Variablen-Fall. Hier interessieren wir uns nur für die oberen beiden Fälle (X —> Y oder Y —> X). Bei den unteren beiden handelt es sich um Sonderfälle (kein Zusammenhang oder ein bidirektionaler Zusammenhang).
Kausalität statistisch beschreiben mit dem do-Formalismus
Um Kausalität mathematisch bzw. statistisch zu formulieren, wird meistens der do-Formalismus benutzt. Hierbei werden bedingte Wahrscheinlichkeiten betrachtet, wobei die Bedingung nicht wie üblich die Beobachtung einer Variablen P(y|X = x), sondern das Eingreifen in das System und das Festlegen der Variablen auf einen Wert ist: P(y|do (X = x)). Um auf den Regen und die nasse Straße zurückzukommen: Hier hätten wir einmal die Wahrscheinlichkeit für Regen, wenn wir eine nasse Straße beobachten (sehr hoch) im Gegensatz zu der Wahrscheinlichkeit für Regen, wenn wir die Straße mit einem Wasserschlauch nass machen (nicht mehr so hoch). Dass diese eben unterschiedlich sind, sagt uns etwas über die kausale Richtung – die eben nicht „Nasse Straße“ —> „Regen“, sondern gerade umgekehrt ist.
Beispiele aus der echten Welt
Kausale Zusammenhänge sind überall zu finden, die Tuebingen Cause Effect Pairs sind eine Sammlung von Datensätzen aus der echten Welt. Beispiele hieraus sind etwa:
- Höhe und Temperatur an verschiedenen Orten (die kausale Richtung ist Höhe —> Temperatur)

Abbildung 3: Höhe (x-Achse) und Temperatur (y-Achse) an verschiedenen Orten
- Trinkwasserzugang und Kindersterblichkeit in verschiedenen Ländern
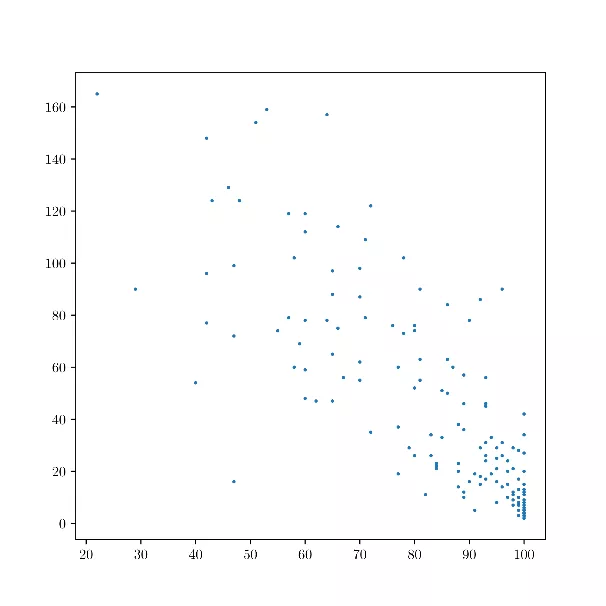
Abbildung 4: Trinkwasserzugang (x-Achse) und Kindersterblichkeit (y-Achse) verschiedener Länder
- Gewicht und Kraftstoffverbrauch verschiedener Fahrzeuge
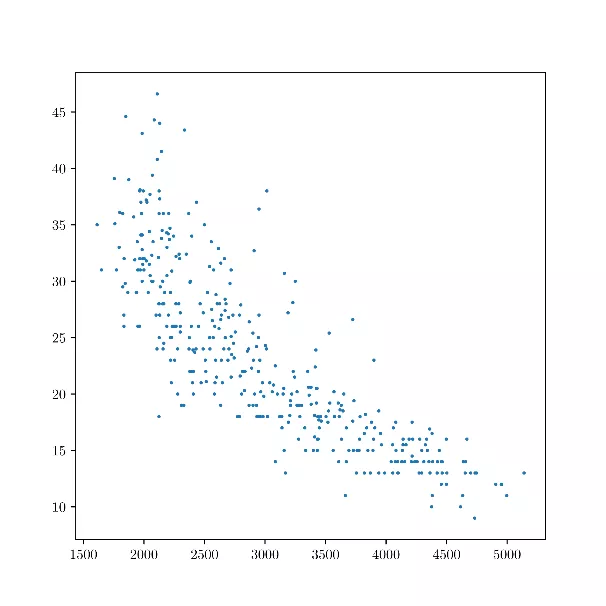
Abbildung 5: Gewicht (x-Achse) und Kraftstoffverbrauch (y-Achse) verschiedener Fahrzeuge
Der Bayes-Faktor zeigt die Richtung
Uns interessieren also die bedingten Wahrscheinlichkeiten für die beiden Modelle X —> Yund Y —> X, gegeben unsere Daten x und y, also P(X —> Y|x,y) und P(Y —> X|x,y). Der Bayes-Faktor setzt diese Wahrscheinlichkeiten miteinander ins Verhältnis:
![]()
Mit dem Bayes-Theorem können wir dies umformen und erhalten ![]() . Ist dieser Faktor also größer als 1, ist eine Richtung X —> Y wahrscheinlicher, ist er kleiner als 1, ist Y —> Xdie wahrscheinlichere Richtung. Um den Faktoren weiter auf den Grund zu gehen, können wir noch die übliche Umformung für bedingte Wahrscheinlichkeiten anwenden:
. Ist dieser Faktor also größer als 1, ist eine Richtung X —> Y wahrscheinlicher, ist er kleiner als 1, ist Y —> Xdie wahrscheinlichere Richtung. Um den Faktoren weiter auf den Grund zu gehen, können wir noch die übliche Umformung für bedingte Wahrscheinlichkeiten anwenden:
![]()
Additive Noise Models
Nehmen wir nun an, die kausale Richtung ist X —> Y. Wenn der kausale Mechanismus durch eine Funktion f repräsentiert wird, gilt also Y = f(X). So ein Modell wäre noch rein deterministisch; wir möchten explizit noch ein „Rauschen“, also einen zufälligen, stochastischen Einfluss, E, erlauben. In den Additive Noise Models wird angenommen, dass dieses Rauschen hinzuaddiert wird, es gilt also Y = f(X) + E. Als A-priori-Verteilung für die verursachende Variable X wird in der Regel eine möglichst natürliche Verteilungsfunktion angenommen, z. B. ein Gaussian Mixture Model. Damit können wir nun den einen Teil Daten überprüfen, nämlich ob die Variable x, die wir als Ursache betrachten, wirklich zu einer A-priori-Verteilung P(x|X —> Y) passt.
Gaussian Process Regression
Um einzuschätzen, ob die Beobachtung der anderen Variablen zu einer bedingten Verteilung P(y|x, X —> Y) passt (wobei wir y = f (x) + e annehmen), müssen wir noch die Funktion f näher betrachten. Dazu behandeln wir f als weitere Realisierung einer Zufallsvariablen. Im Rahmen der Gaussian Process Regression wird angenommen, dass f ein Gaußscher Prozess ist. Ein Gaußscher Prozess ist im Prinzip eine Verallgemeinerung eines Zufallsvektors mit mehrdimensionaler Normalverteilung hin zu einer kontinuierlichen Funktion. Die Kovarianzmatrix der Normalverteilung wird hier zum kontinuierlichen Kovarianzoperator, meistens einfach Kernel genannt. Nachdem man einen bestimmten Kernel als Hyperparameter gewählt hat (RBF-Kernels sind hier üblich, wie auch z. B. bei Support Vector Machines im Machine Learning), wird nun also betrachtet, wie gut die Daten zu einer Funktion f passen, die ein solcher Gaußscher Prozess ist. Eine der Standard-Libraries ist GPML für Matlab, allerdings hat auch Scikit-Learn für Python hier inzwischen eine Implementierung abbekommen.
Causal Generative Neural Networks
Die beschriebenen Methoden helfen uns dabei, den Bayes-Faktor zu bestimmen. Doch es gibt auch eine Methode, hier neuronale Netzwerke einzusetzen. 2017 wurden unter Beteiligung von Facebook AI Research Causal Generative Neural Networks vorgestellt. Dieses Konzept macht sich zunutze, dass neuronale Netzwerke in der Lage sind, Funktionen universell zu approximieren, also prinzipiell jede beliebige Funktion zu modellieren. Hier erhält das Netzwerk die Beobachtungen der einen Variablen, etwa x, und wird dann darauf trainiert, die andere Variable, y, damit zu modellieren. Auch hier tritt wieder die Asymmetrie zwischen kausaler und antikausaler Richtung in Erscheinung. Die wahre kausale Richtung ist in der Regel einfacher zu modellieren als die entgegengesetzte, antikausale Richtung. Die Richtung, in der das Netzwerk die Daten besser modellieren kann, wird dann als die tatsächliche Richtung angenommen.
Kausale Inferenz bei Zeitreihen – Bayesian Structural Time Series
Für das anfangs angesprochene Beispiel, ein Marketingbudget optimal aufteilen zu wollen, ist die Arbeit mit Zeitreihen typisch. Hier ist nun die Fragestellung eher: „Was wäre passiert, wenn die Dinge anders gewesen wären?“ – also z. B. bei vergangenen Werbekampagnen andere Kanäle benutzt worden wären. Diese Fragestellung ist typisch, wenn in der Volkswirtschaftslehre von kausaler Inferenz gesprochen wird, manchmal spricht man auch von Rubins „Potential Outcome Framework“. Eine der modernsten Methoden für solche Analysen sind „Bayesian Structural Time Series”. Google hat hier die Library CausalImpact für die Programmiersprache R veröffentlicht, die auf diese Methodik zurückgreift. Mit gesammelten Zeitreihendaten vergangener Marketingkampagnen können wir nun genau dieser Frage auf den Grund gehen, also einschätzen, wie z. B. der Umsatz ohne die entsprechenden Werbekampagnen gewesen wäre.
Ausblick – kausale Inferenz für Machine Learning
Das Thema hat zahlreiche Bezüge zur Welt des Machine Learnings. Mitunter ähneln sich die Methoden – so werden etwa Kernels auch bei der Klasse der SVM-Algorithmen genutzt. Die Causal-Generative-Neural-Network-Algorithmen sind ein Beispiel dafür, wie der ML-Werkzeugkasten genutzt werden kann, um zur kausalen Inferenz beizutragen. Denkbar ist aber auch, dass kausale Inferenz als Teil eines größeren Machine-Learning-Szenarios verstanden wird. Im Fall von mehreren Variablen könnte mit kausaler Inferenz im Rahmen eines Unsupervised-Learning-Kontexts in einem ersten Schritt die kausale Richtung der Variablen ergründet werden. Ist die kausale Richtung der Variablen klar, kann dann mit Supervised Learning an konkreten prädiktiven Modellen gearbeitet werden.
Referenzen:
- Mooij et al.: Distinguishing cause from effect using observational data: methods and benchmarks (JMLR, 2014, https://arxiv.org/abs/1412.3773)
- Mooij et al.: Probabilistic latent variable models for distinguishing between cause and effect (NIPS, 2011)
- Goudet et al.: Causal Generative Neural Networks (arxiv preprint, 2017, https://arxiv.org/abs/1711.08936)

