







In einem früheren Blogbeitrag habe ich gezeigt, wie Du Ray lokal, genauer gesagt unter Windows, einrichten kannst. Die wahre Schönheit von Ray liegt jedoch in seiner Fähigkeit, schnell von einer lokalen Umgebung mit hoher Entwicklungsgeschwindigkeit zu einer Cloud-Umgebung mit Zugang zu deutlich mehr Rechenleistung zu wechseln. In diesem Blogbeitrag zeige ich Dir, wie Du Ray in der Google-Cloud einrichten kannst. Eine lokale Installation ist dafür nicht notwendig – Du kannst sofort in der Cloud starten.
Gesamtansatz: Security first, mit Unterstützung durch Google-Cloud-Mechanismen
Bei der lokalen Verwendung von Ray müssen wir uns nicht allzu viele Gedanken über die Sicherheit machen. In der Cloud ist das anders. Vor allem beim Aufbau des Netzwerks sollten Sicherheitsaspekte in die Überlegungen einbezogen werden.
Ray benötigt viele offene Ports für die Kommunikation zwischen den Cluster Machines und verwendet intern eine Redis-Instanz, deren Ports vor unbefugtem Zugriff abgeschirmt werden müssen – auch, wenn diese durch ein Passwort geschützt ist. Glücklicherweise bietet die Google Cloud einige spezielle Mechanismen, die uns helfen, eine sichere Netzwerkumgebung für Ray aufzubauen. Unser Ansatz ist der folgende:
- Wir konfigurieren ein virtuelles privates Netzwerk (VPC), das ausschließlich von Ray genutzt wird.
- Wir verwenden nur interne IP-Adressen, d. h., keine der von uns verwendeten virtuellen Maschinen (VMs) hat eine externe IP-Adresse. Folglich wird keine dieser Maschinen vom Internet aus erreichbar sein.
- Um mit dem Cluster kommunizieren zu können, verwenden wir den Identity-Aware-Proxy (IAP) von Google.
- Um das Ray-Dashboard anzuzeigen, verwenden wir die Webvorschau, die in die Google Cloud Shell integriert ist.
Einrichten des Netzwerks für unser Ray-Cluster
Im ersten Schritt richten wir das VPN für unser Cluster ein. Dazu kannst Du entweder die Cloud-Konsole, die Cloud Shell oder Terraform verwenden. Wenn Du die Cloud Shell verwenden möchtest, enthält das Repo eine Datei mit den erforderlichen Befehlen. Wir müssen ein VPN einrichten, ein Subnetz in der Region, in der wir unser Cluster bereitstellen möchten (ich habe mich für europe-west1 entschieden, aber Du hast vielleicht eine andere Präferenz), und einige Firewall-Regeln. Bevor Du das Skript verwendest, musst Du die Projekt-ID (Platzhalter „<your-project-id>“) anpassen, (wenn Du das willst) eine andere Region wählen und (wiederum optional) die Namen des Netzes und des Subnetzes ändern. Insbesondere wenn Du die Region änderst, ist Letzteres ratsam, da der Name der Region derzeit Teil des Namens des Subnetzes ist.
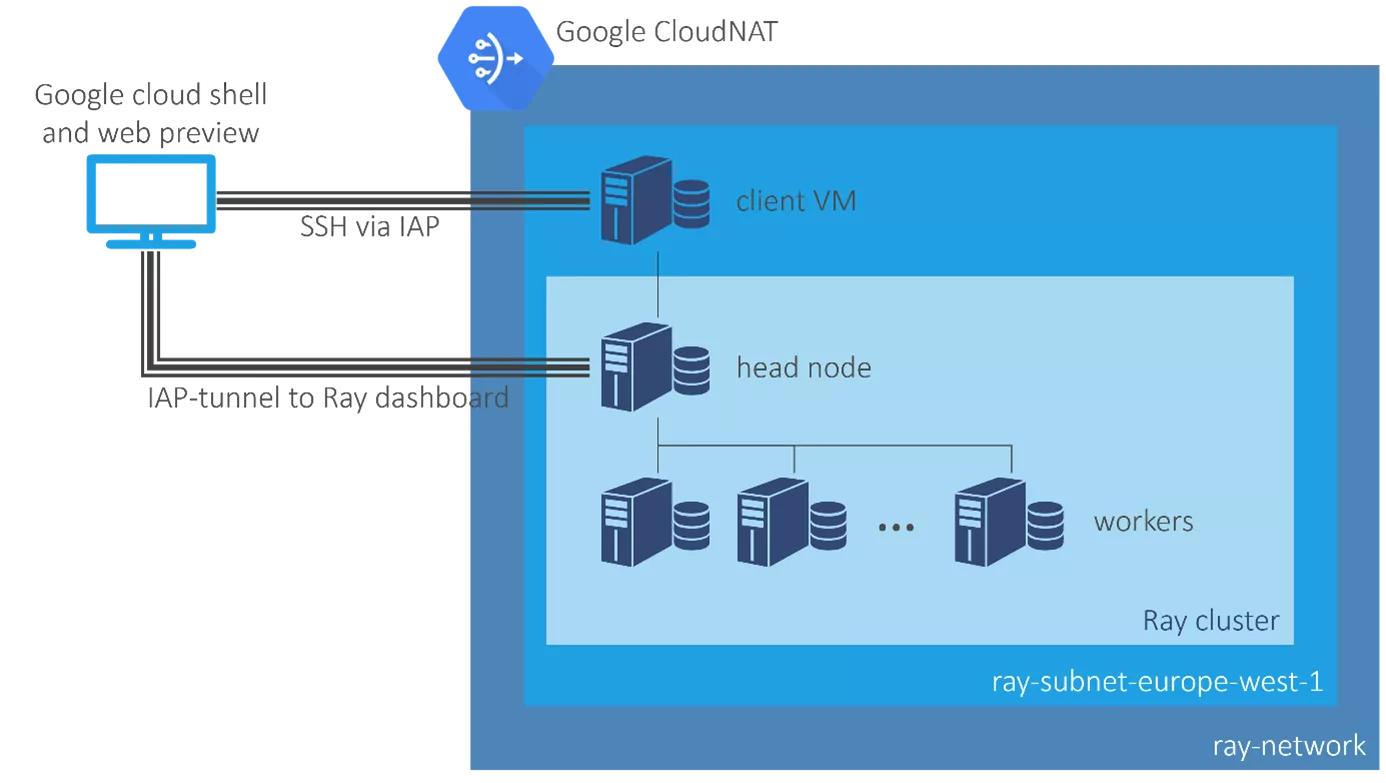
Die Firewall-Regeln öffnen alle Ports für die TCP- und UDP-Kommunikation innerhalb des Clusters (d. h. innerhalb des VPN). Zusätzlich fügen wir eine Firewall-Regel hinzu, die die SSH-Kommunikation mit dem Identity-Aware-Proxy (IAP) von Google erlaubt. Der IAP verwendet den IP-Bereich 35.235.240.0/20. Mit dieser Firewall-Regel kannst Du Dich mit jeder Maschine innerhalb des VPN verbinden, indem Du einfach auf „SSH“ neben dem Menüpunkt der VM in der Cloud-Konsole klickst. Sie ermöglicht es uns auch, Googles Webvorschau über einen IAP-Tunnel mit dem Ray-Dashboard auf dem Cluster zu verbinden.
Schließlich fügst Du dem Netzwerk ein CloudNAT hinzu (in derselben Region, in der sich Dein Subnetz befindet), damit die Maschinen Software aus dem Internet herunterladen können. Die Gesamtkonfiguration ist in der Abbildung links dargestellt.
Verwendung einer Client-VM
Ein Client-Rechner ist eine VM, die nicht zum Cluster gehört (obwohl sie sich im selben Subnetz befindet) und nur dazu dient, das Cluster zu starten, Aufträge zu erteilen und das Cluster dann wieder herunterzufahren. Du kannst das natürlich auch von Deinem lokalen Rechner aus tun – dafür sind allerdings einige Vorbereitungen notwendig, die in der Cloud doch etwas komfortabler möglich sind: Zum einen musst Du natürlich Ray installieren (das ist der einfache Teil), zum anderen aber auch sicherstellen, dass Du es in einer Umgebung mit derselben Python-Version installierst, die im Cluster verwendet wird. Und „dieselbe“ bedeutet in diesem Fall wirklich dieselbe: Sogar die Mikroversion – die Zahl nach dem zweiten Punkt – muss identisch sein. Wenn also in Deinem Cluster z. B. Python 3.7.12 läuft, braucht Dein Client auch 3.7.12. In der Cloud kannst Du Python-Versionen sehr einfach zwischen Cluster und Client synchronisieren: Du verwendest einfach das gleiche VM-Image für die Cluster-Maschinen und den Client. Wenn Du die Cloud-Konsole verwendest, um Deine VM einzurichten, findest Du dieses Image, wenn Du in der Auswahl der Betriebssysteme nach „Deep Learning on Linux“ suchst. Es gibt mehrere Versionen dieses Images, aber wir lassen das Standard-Image einfach unverändert. Zwar ist es ein bisschen übertrieben, dieses große Image auf dem Client zu installieren, jedoch stellst Du so sicher, dass Du immer die gleiche Python-Version auf dem Client und dem Cluster hast. Für den Client-Rechner reicht in der Regel etwas Kleines wie n1-standard-1 aus. Vergiss aber nicht, die Netzwerkschnittstelle auf das soeben erstellte Netzwerk und Subnetz einzustellen und für die externe IP „None“ zu definieren. Unter „Identität und API-Zugriff“ wählst Du zudem die Option „Uneingeschränkten Zugriff auf alle Cloud APIs zulassen“. Das ist erforderlich, da wir unserer VM erlauben wollen, andere VMs zu starten. Wenn Du möchtest, kannst Du die VM auch über die Cloud Shell mit diesem Skript starten. Denk nur daran, zumindest den Platzhalter „<your-project-id>“ (er kommt zweimal vor!) und – falls Du sie oben geändert hast – die Region zu ersetzen.
Ray auf der Client-VM installieren
Um Ray zu installieren, logge Dich per SSH in den Client-Rechner ein, indem Du die SSH-Schaltfläche in der Cloud-Konsole neben der VM selbst verwendest. Stelle zunächst sicher, dass Du eine aktuelle Version von pip hast, indem Du Folgendes ausführst:
pip install --aktualisieren pip
Dann installiere Ray selbst mit:
pip install 'ray[default]'
An diesem Punkt warnt pip Dich möglicherweise vor einem Abhängigkeitskonflikt mit grpcio, aber das kannst Du getrost ignorieren.
Wie geht es nun weiter?
Wir haben jetzt die benötigte Cloud-Infrastruktur eingerichtet. In Teil 2 werden wir die Cluster-Definition an unsere Bedürfnisse anpassen und das neue Cluster ausprobieren.

