







Wenn wir einfache deskriptive Analysen durchführen, beschränken wir uns nur selten auf die Mittelwerte. Häufiger werfen wir einen Blick auf die ganze Verteilung, sehen uns Histogramme, Quantile und Ähnliches an. Mittelwerte allein führen oft zu falschen Schlussfolgerungen und unterschlagen wichtige Informationen. Warum vergessen wir das, sobald wir Vorhersagemodelle erstellen? Diese zielen meist nur auf Mittelwerte – und die lügen.
Anwendungen in der Logistik: Quantilregression ist eine Standardfunktion in Amazon Forecast
Es gibt Anwendungsfälle, in denen die Modellierung von Quantilen unentbehrlich ist. Häufig ist das zum Beispiel in der Logistik der Fall. Vorreiter wie Amazon reagieren darauf mit Produkten wie Amazon Forecast, bei dem die Vorhersage beliebiger Quantile zu den Kernfunktionen gehört.
Leider ist die Quantilregression nicht einfach zu implementieren. Der Rest dieses Blogbeitrags wird zeigen, warum das so ist, und erklären, wie die Schwierigkeiten überwunden werden können, um Quantilvorhersagen mit Gradient-Boosted-Trees-Modellen zu erstellen. Für tabellarische Daten sind Gradient Boosted Trees immer noch Stand der Technik, obwohl häufig behauptet wird, dass Deep-Learning-Methoden endlich aufgeholt hätten. Ich werde zu den Ersten gehören, die die neuen Möglichkeiten feiern, wenn es tatsächlich so weit ist, weil ich jetzt schon gern mit Deep Learning für Tabellendaten spiele. Aber so weit sind wir noch nicht.
Die bekannteste Implementierung von Gradient Boosted Trees ist wahrscheinlich XGBoost, gefolgt von LightGBM und CatBoost. XGBoost ist für seine Flexibilität und seinen Reichtum an Optionen bekannt. Für die Quantilregression gab es bereits 2016 einen Feature Request bei XGBoost. Leider ist er immer noch offen.
Quantilregression in XGBoost: Moment, ist das nicht ganz einfach?
Wer sich eingehend mit XGBoost beschäftigt hat, wird sich vielleicht fragen, warum wir die Quantilregression nicht einfach mit einer benutzerdefinierten Verlustfunktion realisieren können. In der Tat ist bekannt, dass die Quantilregression dieser einfachen Verlustfunktion entspricht (für ein beliebiges Quantil q zwischen 0 und 1):
l (x) = x (q - 1 {x<0} )
Um sie als benutzerdefinierte Verlustfunktion in XGBoost zu verwenden, müssen wir auch die ersten beiden Ableitungen bereitstellen. Und hier beginnen die Probleme. Erstens ist diese Verlustfunktion an der Stelle 0 nicht differenzierbar, sodass die Ableitungen gar nicht überall definiert sind. Und zweitens ist die zweite Ableitung konstant gleich null (dort, wo sie existiert). Der zweite Punkt ist besonders problematisch, weil der Optimierungsalgorithmus zweiter Ordnung, der XGBoost und andere Implementierungen der aktuellen Generation so schnell macht, mit einer verschwindenden zweiten Ableitung nichts anfangen kann. Er funktioniert in einer solchen Situation sehr schlecht. Mit einer benutzerdefinierten Zielfunktion ist es also leider nicht getan.
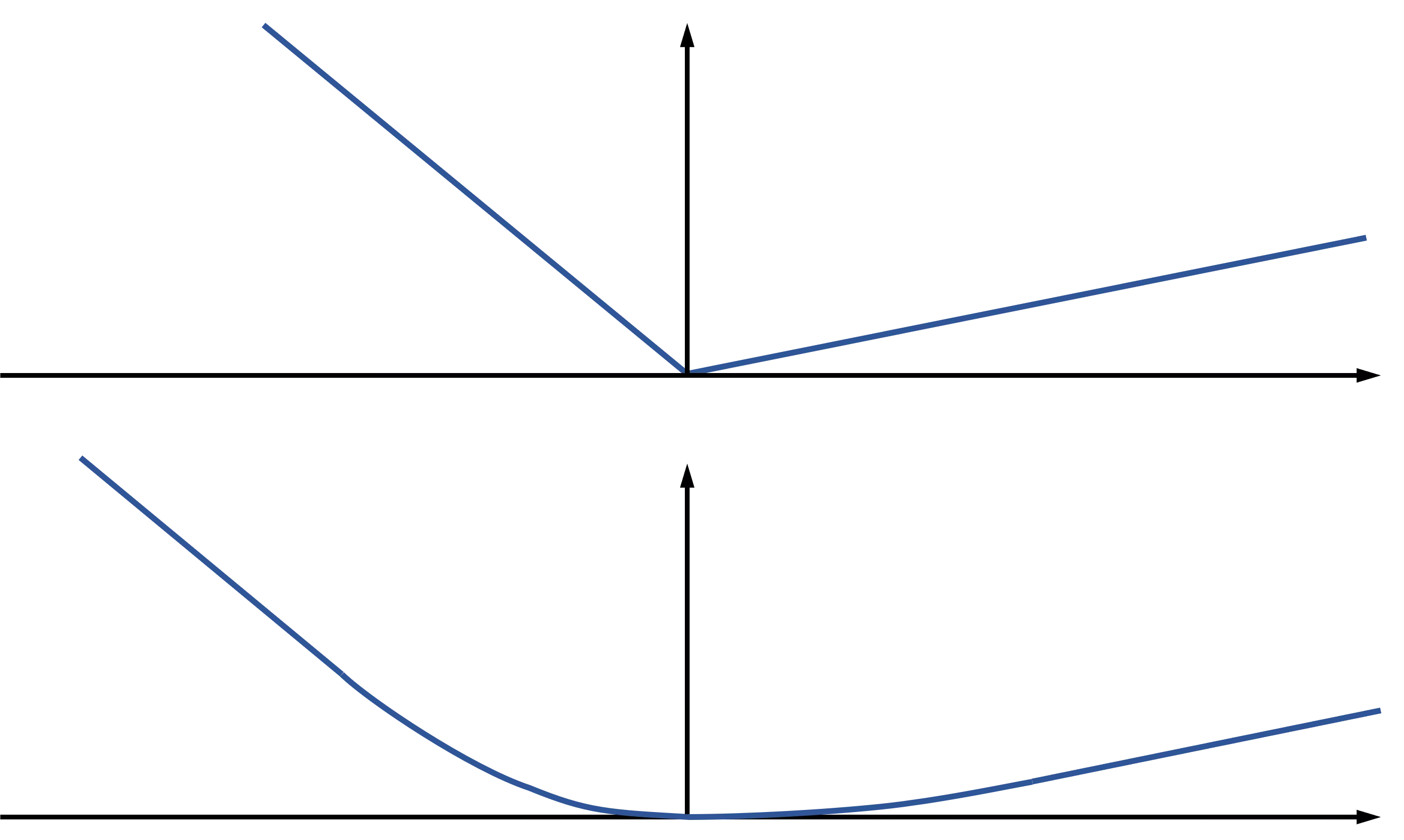
Huber-Verlustfunktion: If your loss isn’t nice, you have to Huberize
Es gibt ein Standardhilfsmittel für einige der Unannehmlichkeiten, die die Verlustfunktion für die Quantilregression mit sich bringt: Man kann die Verlustfunktion „huberisieren“, d. h., man ersetzt die Funktion in der Nähe von 0 durch eine geglättete Version (eine quadratische Funktion). Die Abbildung links zeigt den Vergleich zwischen der Standard-Quantilverlustfunktion (Beispiel im oberen Teil der Abbildung) und der huberisierten Version (unten). Damit ist das erste Problem gelöst, aber leider nicht das zweite: Die zweite Ableitung ist immer noch nicht besonders hilfreich, da sie abgesehen von einem kleinen Bereich um 0 herum immer noch verschwindet. Huberisieren bringt uns also hier nicht weiter. In vielen anderen Situationen ist es aber durchaus hilfreich. Wer mehr über die Huber-Verlustfunktion für die Quantilregression erfahren möchten, findet im Paper von Aravkin et al. mehr Material.
Wie man ein unlösbares Problem löst
Okay, vielleicht war es einfach eine schlechte Idee, eine Quantil-Verlustfunktion mit Optimierungsmethoden zweiter Ordnung zu kombinieren. Vielleicht sind in diesem Fall neuronale Netze tatsächlich die bessere Wahl, weil sie eine gewisse Flexibilität in Bezug auf den Optimierungsalgorithmus bieten und es Alternativen gibt, die keine zweite Ableitung erfordern. Aber halt ... LightGBM bietet tatsächlich die Quantilregression als Standardfunktion! Die LightGBM-Entwicklergemeinschaft hat einen Weg gefunden, das Problem mit einer vernünftigen Näherung zu lösen, die eine funktionierende Quantilregression liefert und gleichzeitig die Geschwindigkeitsvorteile der Optimierung zweiter Ordnung beibehält. Wie J. Mark Hou in seinem Blogeintrag anmerkt, wurde der Trick, den sie verwendet haben, zuerst im Gradient-Boosted-Trees-Algorithmus von Scikit-learn implementiert: Um das Problem der verschwindenden zweiten Ableitung zu lösen, werden die Werte der zweiten Ableitung in den Blättern jedes Baums (die natürlich alle 0 sind) durch die Werte der Verlustfunktion selbst ersetzt. Da dies nur in den Blättern geschieht, ist der Rechenaufwand relativ gering. Dieses Vorgehen repariert zumindest diejenigen Verlustfunktionswerte, die für die Gesamtergebnisse am wichtigsten sind. Die Verlustfunktionswerte, die für die Splits im Baum verwendet werden, bleiben, wie sie sind. Das ist aber akzeptabel, da die Splitting-Algorithmen ohnehin nur grobe Heuristiken sind. Ein kürzlich in Nature erschienener Artikel ist nur eine von mehreren Quellen, die über sehr gute Ergebnisse mit der LightGBM-Implementierung der Quantilregression berichten.
Quantilregression überall: LightGBM rettet den Tag
Endlich haben wir eine State-of-the-Art-Implementierung von Gradient Boosted Trees gefunden, die die zusätzliche Flexibilität der Quantilregression mitbringt. Jetzt gilt es, das neue Werkzeug zu benutzen: Im ersten Schritt kann man vorhandene Modelle daraufhin prüfen, ob es sich lohnt, den Mittelwert durch den Median zu ersetzen, zum Beispiel weil der weniger anfällig für Ausreißer ist. Wenn man sich erst einmal an dieses neue Instrument gewöhnt hat, sieht man plötzlich überall Möglichkeiten für verschiedene Varianten der Quantilregression.
Und jetzt: Einfach mal ausprobieren!

