







Wenn eine Datenanalyse-Pipeline nach erfolgreichem Proof of Concept (POC) in Produktion gehen soll, ist dies oft ein langer Weg. Ibis bietet die Möglichkeit, diesen Prozess zu vereinfachen und somit schneller Mehrwert zu erzeugen.
Nach der erfolgreichen lokalen Entwicklung einer Analyse-Datenpipeline in Python muss der Code oftmals umgeschrieben werden, um in Produktion laufen zu können. Aber muss das eigentlich so sein? Die Python-Ibis-Bibliothek, die der Hauptautor der Python-Pandas-Bibliothek Wes McKinney programmiert hat, bietet eine spannende Lösung, um Datenverarbeitung zwischen Produktions- und Entwicklungsumgebungen anzugleichen und es somit dem Analytics-Team zu ermöglichen, schneller in Produktion zu gehen. Wir zeigen Dir in diesem Blogbeitrag, wie das funktioniert.
Entwicklung von Reporting & Analytics Pipelines
Reporting & Analytics Pipelines sind ein wichtiger Bestandteil eines datengetriebenen Unternehmens. Zum Bauen von solchen Pipelines nutzen Teams oft isolierte lokale Entwicklungsumgebungen, um möglichst schnell Resultate produzieren zu können. Anschließend stehen sie dann aber vor der Herausforderung, die Pipelines in produktive Systeme zu übertragen. Das Problem: Um beispielsweise im Data Warehouse zu laufen, muss der Code oft umgeschrieben werden.
Ein Grund dafür ist, dass die Datenverarbeitung in der Entwicklungs- und Produktionsumgebung mit verschiedenen Technologien geschieht. Folgende Herausforderungen resultieren aus diesen Unterschieden:
- Das Entwicklungsteam benötigt zusätzliche Kenntnisse über die Technologien aus der Produktionsumgebung.
- Oftmals werden daher nach Abschluss der initialen Entwicklung zusätzliche oder andere Mitarbeiter:innen benötigt. Dies kann aufgrund der (Nicht-)Verfügbarkeit der Mitarbeiter:innen zu Projektverzögerungen führen.
- Beim Umschreiben des Codes können Fehler oder ungewollte Veränderungen auftreten. Dies kann einen Vertrauensverlust bei Stakeholdern verursachen.
Die Python-Ibis-Bibliothek bietet eine Lösung, um die Datenprozessierung zwischen Produktions- und Entwicklungsumgebung zu vereinheitlichen. Mit Python Ibis geschriebener Code kann ohne Anpassungen sowohl auf einer lokalen Umgebung als auch in Datenbanken oder einem Data Warehouse laufen.
Wie funktioniert Python Ibis?
Der erste Schritt beim Arbeiten mit Ibis ist es, eine Verbindung zu einer Datenquelle herzustellen. In einer lokalen Entwicklungsumgebung könnte dies ein Pandas Dataframe sein, in der Produktionsumgebung eine Tabelle in einem DWH oder einer Datenbank.

Illustration einer Ibis-Connection zu einer lokalen SQLite-Datenbank
Anschließend kann die Logik zur Datentransformierung mittels der Ibis API geschrieben werden. Python Ibis generiert dabei für das relevante Datenbackend, wie z. B. Pandas, Spark oder Big Query, den relevanten Code. Die Backends bleiben zuständig für die Ausführung des Codes. Die Datentransformationen werden wie bei anderen Big Data Frameworks lazy ausgeführt, das heißt, sie werden erst dann ausgeführt, wenn sie benötigt werden.
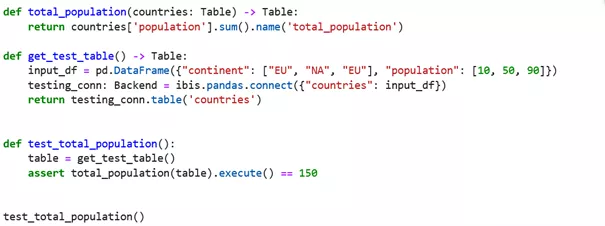
Illustration einer lokalen Ibis-Connection und Unit Testing von Ibis-Code
Use-Case-Beispiel: Churn-Projekt mit Ibis-Bibliothek in der Google Cloud Platform (GCP)
Ein Advanced-Analytics-Team arbeitet an einer neuen Pipeline für die Marketingabteilung. Diese möchte täglich Metriken zur Customer-Churn-Rate für wichtige Kundensegmente erhalten, damit sie ihre Anti-Churn-Kampagne besser steuern kann. Zunächst erarbeitet das Analytics-Team eine Minimal-Viable-Product-Version mit der Ibis-Bibliothek in Jupyter Notebooks auf Vertex AI (Google/User managed VMs mit Jupyterlab vorinstalliert), auf der sie die Daten lokal gespeichert haben.
Sobald die Pipeline die notwendige Qualität erreicht hat, um in Produktion zu gehen, reicht es, die Verbindung zur lokalen Datenquelle mit den entsprechenden Tabellen im Data Warehouse – hier Big Query – zu ersetzen. Das schnelle und einfache Übertragen der Pipeline mittels der Ibis-Bibliothek ermöglicht es dem Team, schneller Mehrwert für die Marketingabteilung zu schaffen.
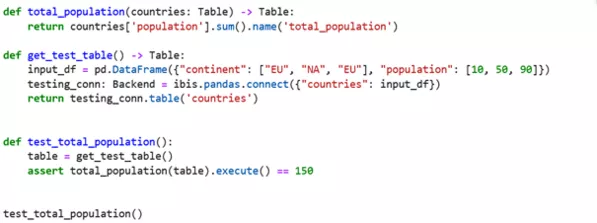
Illustration von Ibis-Code, der zunächst lokal getestet und dann im Produktions-DWH ausgeführt wird
So viel zu den Basics. Im zweiten Teil dieser Blogserie erläutere ich, wie Du Ibis auf einer GCP Vertex AI aufsetzen kannst. Zudem zeige ich an einem Beispiel, wie einfach eine Pipeline mit Python Ibis von einer lokalen Datenquelle ins DWH umgestellt werden kann.
Falls Du bereits vorher mit Python Ibis gearbeitet hast, freue ich mich über Dein Feedback dazu. Bei Fragen zum richtigen Einsatz von Ibis stehen Dir meine Kolleg:innen und ich mit unserer Technologiekompetenz und Erfahrung gern zur Verfügung.

