







Auf Grundlage unseres vorherigen Blogbeitrags sollten sich unsere transformierten Daten nun im Data Lake befinden und im Glue-Datenkalalog zur Verfügung stehen. Im zweiten Artikel unserer Blogreihe klären wir nun, was AWS Lake Formation ist und wie Du es nutzen kannst, um unbefugten Datenzugriff zu verhindern.
Was ist AWS Lake Formation?
AWS Lake Formation ist ein vollständig verwalteter Service, der das Erstellen, Sichern und Verwalten von Data Lakes auf AWS vereinfacht. Mit AWS Lake Formation kannst du Sicherheitsrichtlinien und Zugriffskontrollen definieren, Datenmanagement und -Governance einrichten oder weitere AWS-Services für die Datenverarbeitung und -analyse integrieren.
Die wichtigsten Vorteile von AWS Lake Formation sind:
- Einfache Einrichtung: Lake Formation vereinfacht den Aufbau eines Data Lakes, indem es den Import von Daten aus AWS-internen Datenbanken und externen Quellen erleichtert. Es stellt mehrere integrierte Konnektoren bereit, um Daten aus verschiedenen Quellen wie z. B. RDS, DynamoDB und S3 zu importieren. Außerdem besteht beispielsweise die Möglichkeit, einen bereits in S3 aufgebauten Data Lake zu nutzen.
- Katalogisierung von Daten: Lake Formation durchsucht Deine Datenquellen via Glue, um die Metadaten zu extrahieren, und erstellt einen durchsuchbaren Datenkatalog.
- Verwaltung von Zugriffskontrollen: Mit Lake Formation kannst Du den Zugriff auf Daten im Data Lake verwalten. Das Tool unterstützt feingranulare Zugriffskontrollen, mit denen Du festlegen kannst, wer auf welcher Ebene auf Daten zugreifen darf, also z. B. auf Tabellen-, Spalten-, Zeilen- oder Zellenebene. Diese Regeln gelten für IAM-Nutzer:innen und -Rollen.
- Kontoübergreifender Zugriff: Lake Formationerleichtert den Datenaustausch über verschiedene AWS-Konten.
- Integration von AWS-Services: Lake Formationlässt sich auch mit verschiedenen anderen AWS-Services integrieren, z. B. AWS Glue, AWS IAM, Amazon Redshift, Amazon Athena und AWS KMS.
Das folgende Diagramm bietet eine Übersicht darüber, wie AWS Lake Formation Nutzeranfragen verarbeitet. Versucht ein:e User:in, auf Daten zuzugreifen, die von AWS Lake Formation verwaltet werden, werden ihm temporär gültige Zugangsdaten mit von Lake Formation festgelegten Zugriffsbeschränkungen bereitgestellt.
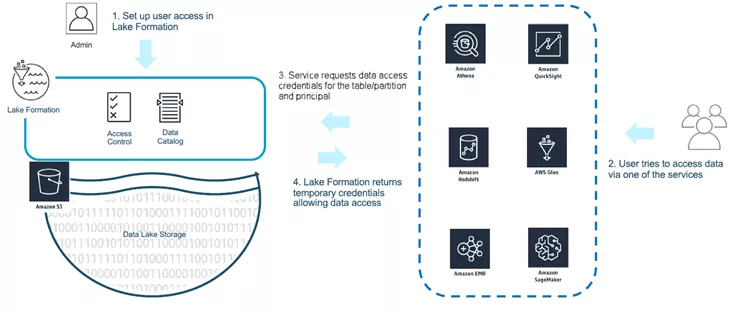
docs.aws.amazon.com/lake-formation/latest/dg/how-vending-works.html
Was sind die Vorteile?
Wie wir bereits in Teil 1 unserer Blogreihe gesehen haben, werden personenbezogene Daten (PII) und nicht personenbezogene Daten (Non-PII) in separaten Buckets gespeichert. Bei der Verarbeitung von PII-Daten ist höchste Sorgfalt vonnöten, denn Datenschutzverstöße können teuer werden, wie mehrere Fälle in verschiedenen Ländern gezeigt haben. Deshalb nutzen wir AWS Lake Formation, um eindeutige Regeln für den Zugriff auf PII- und Non-PII-Daten festzulegen.
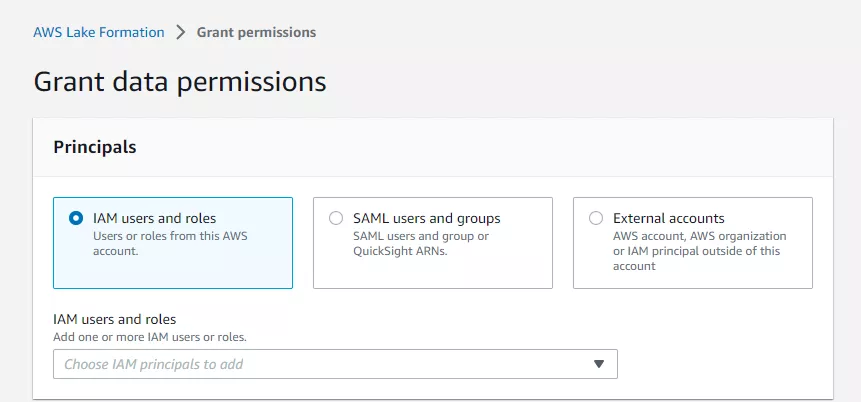
Zunächst müssen wir einen Data-Lake-Administrator:in bestimmen, der/die als einzige:r User:in befugt ist, Lake Formation-Berechtigungen für den Zugriff auf Daten-Speicherorte und Datenkatalog-Ressourcen an einen Principal zu erteilen. Zu diesem Zweck empfehlen wir, keine:n Nutzer:in mit Administratorrechten zu wählen. Die für den/die Data-Lake-Administrator:in erforderliche Richtlinie findet sich unter „AWSLakeFormationDataAdmin“. Du hast außerdem die Möglichkeit, weitere Richtlinien für den/dir jeweilige:n Nutzer:in zu ergänzen, etwa für den kontoübergreifenden Datenaustausch.
Sobald der/die User:in eingerichtet wurde, müssen wir die S3-Speicherorte in Lake Formation registrieren. Dazu gehen wir in den Abschnitt „Data Lake locations“ und registrieren jeweils einen Speicherort pro Bucket. So stellen wir sicher, dass die Berechtigungen zum Zugriff auf die Daten im jeweiligen Bucket durch Lake Formation und nicht durch Nutzerberechtigungen geregelt werden.
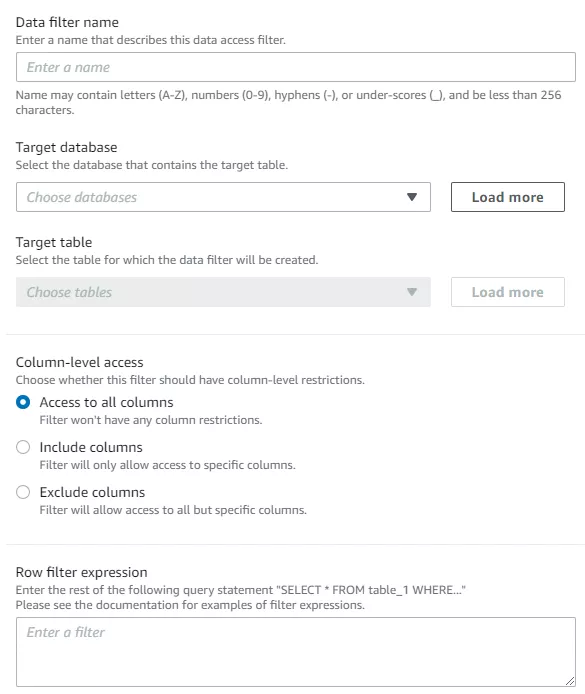
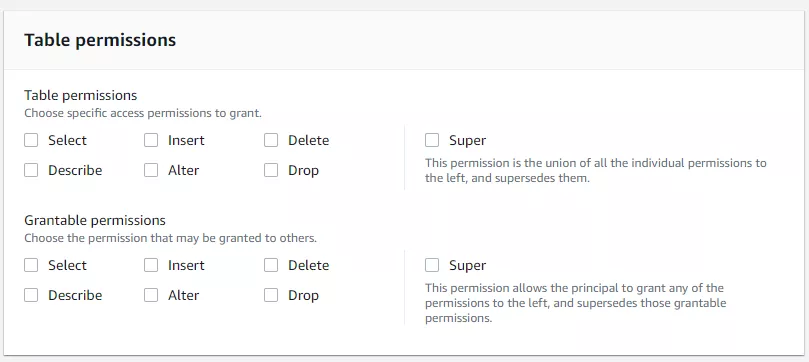
Nachdem wir nun alles eingerichtet haben, schauen wir uns als nächstes an, wie wir Berechtigungen ändern können. Es gibt verschiedene Möglichkeiten, Berechtigungen mit unterschiedlicher Granularität zu erstellen und zu erteilen, z. B. auf Datenbank-, Tabellen-, Spalten-, Zeilen- oder Tag-Ebene (siehe Screenshot unten). Mithilfe von Datenfiltern (siehe Screenshot unten rechts) können wir festlegen, welche Spalten bei Zuweisung zu einer Berechtigung berücksichtigt bzw. ausgeschlossen werden sollen. Hier ist es auch möglich, eine WHERE-Klausel zum Filtern auf Zeilenebene zu verwenden. Die Verwaltung von Berechtigungen mittels Tags ermöglicht uns, ganz einfach Gruppenberechtigungen für bestimmte Daten mit diesem Tag zu erteilen. Ausführliche Informationen zu allen Berechtigungsoptionen findest Du in der Dokumentation (AWS LakeFormation Dokumentation). Darüber hinaus hat AWS bereits angekündigt, dass die Datenfreigabe von Amazon Redshift ab sofort die zentralisierte Zugriffskontrolle mit AWS Lake Formation unterstützt (AWS-Mitteilung).
Im zweiten Teil unserer Blogreihe ging es um die Anwendungsmöglichkeiten von Lake Formation und die Vorteile für unseren Use Case. Wir haben jetzt den Config Bucket, Crawler, ETL-Jobs sowie separate Buckets für PII- und Non-PII-Daten eingerichtet und nutzen AWS Lake Formation für die Verwaltung aller Berechtigungen. Wir haben außerdem gesehen, auf welchen Ebenen Berechtigungen erteilt werden können.
Im nächsten Blogbeitrag soll es darum gehen, wie wir die datenschutzrechtlichen Anforderungen der DSGVO noch besser erfüllen, indem wir das Recht auf Vergessenwerden und das Auskunftsrecht in unser Framework implementieren. Bei Fragen, melde Dich gerne bei uns!
Melde Dich hier!