







Herzlichen Glückwunsch, Du hast es geschafft und die bisherigen Ausführungen zu unserem Referenzarchitekturmodell unbeschadet überstanden! Der mühsamste und lästigste Teil liegt damit schon hinter uns. Falls Du gerade erst mit Teil 3 in unsere Blogserie einsteigst, kein Problem! Klicke einfach auf die Links zu Teil 1 und Teil 2. Dort erfährst Du mehr zu Ingestion und Data Lakes sowie der gesamten Referenzarchitektur.
Das Data Warehouse ist letztlich die einzige Wahrheitsquelle in Deinem Unternehmen und zugleich der Dienst, auf den die meisten Deiner Benutzer:innen täglich zugreifen. Die Services der großen Cloud-Anbieter reichen von Self-managed- bis hin zu Serverless-Lösungen. Während die endgültige Entscheidung schlussendlich von Deiner spezifischen Umgebung abhängt, tendieren wir zu Letzteren, da sie deutlich geringere Wartungsanforderungen aufweisen und eine bessere Integration mit anderen Diensten im Ökosystem des Cloud-Anbieters bieten. Bei unserem Data Warehouse Service achten wir in der Regel auf Funktionen wie ANSI-SQL-Unterstützung, Stream‑/Batch-Ingestion, In-Memory-Funktionen, KI-/ML-Framework-Integration, Sicherheit auf Spalten‑ und Zeilenebene, automatische Sicherung und Wiederherstellung, hohe Verfügbarkeit, Skalierbarkeit, Uptime-SLA usw. Durch die Rationalisierung der Datenaufnahme, die Komplexität der Konfiguration (Beibehaltung von Tabellen oder Zugriffsberechtigungen für Datensätze) und durch ein vielfältiges Angebot von Funktionen rund um den Data Warehouse Service trennt sich schließlich die Spreu vom Weizen.
Daten sichtbar machen
Datenvisualisierungstools sind die Retter in der Not, denn sie schließen die Lücke zwischen den oben beschriebenen Low-Level-Datenmanagement-Themen und bieten die Option, aus den zugrunde liegenden Daten einen Wert abzuleiten. Sie ermöglichen es einer Vielzahl von Endnutzer:innen, transparent und unter Einhaltung aller Sicherheits- und Compliance-Regeln auf Daten zuzugreifen, wertvolle Erkenntnisse zu gewinnen und interaktive Dashboards zu erstellen, die auch unternehmensweit freigegeben werden können. Durch die Integration mit dem Data Warehouse Service nutzen Datenvisualisierungstools auf effektive Weise Low-Level-Optimierungen (wie Filter-Push-down) und reduzieren so die zu bewegenden Datenmengen. Außerdem dienen Datenvisualisierungstools dazu, die Arbeit der Endbenutzer:innen in beträchtlichem Maße zu vereinfachen und zu modernisieren. Hierfür werden vielfältige Funktionen wie Data Discovery, Data Cataloging, regelbasierte Benachrichtigungen, regelmäßige Berichte, Git-Workflows zur Kollaboration und vieles mehr genutzt.

Sobald wir über fortgeschrittene Anwendungsfälle wie Empfehlungsdienste, dynamische Preisgestaltung und Betrugserkennung nachdenken, kommt die KI-/ML-Plattform ins Spiel. Als Data Engineer möchtest Du Informationen aufbereiten und vorverarbeiten und dann Deine Modelle entwickeln, trainieren, testen und bereitstellen. Dieser Workflow muss so einfach und schlank wie möglich sein, damit Deine KI-/ML-Teams die neuesten Modelle schnellstmöglich bereitstellen können. Mit anderen Worten: keine einmaligen VM-Instanzen mehr, die ohne korrekte Metadaten-Tags herumliegen. Und keine manuellen Datenaufnahmen/-exporte aus obskuren lokalen Datenquellen. Zu den zusätzlichen Funktionen, die den Werkzeugkasten eines Analysten erweitern, gehören die Kennzeichnung von Datensätzen, die Verwendung von vorbereiteten oder benutzerdefinierten VM-Images (benutzerdefinierte KI-/ML-Bibliotheken), Notebooks (Jupyter) und die Verwendung des KI/ML-Repositorys (Stichwort: gemeinsame Nutzung von KI/ML-Komponenten und Pipelines durch Data Engineers für eine verbesserte Zusammenarbeit). Eine KI-/ML-Plattform wird im Hinblick auf die nahtlose Integration aller oben genannten Funktionen bewertet.
Was alldem zugrunde liegt: Zentrale Dienste
An diesem Punkt haben wir zwar einen durchgängigen Datenfluss von unseren Quellsystemen zu den Endanwender:innen, aber wir tappen immer noch etwas im Dunkeln. Erstens haben unsere Anwender:innen keinen Überblick über die auf der Plattform gespeicherten Daten und können daher nicht kurzfristig beurteilen, welche Datensätze für ihren Anwendungsfall relevant sind. Zweitens fehlt unserem DevOps-Team, wenn eine der oben genannten Komponenten ausfällt, die Fähigkeit zur Beobachtung und Fehlersuche. Drittens werden, wie wir leider schon in zu vielen Unternehmen feststellen mussten, die Infrastrukturressourcen von Hand bereitgestellt. In der Folge sind Konzepte der Automatisierung und Wiederholbarkeit nicht anwendbar.
Metadatenmanagement in Form eines Datenkatalogs behebt das erste Problem. Automatisierte Data Discovery in Cloud-Diensten (Datensätze im DWH oder in der persistenten Schicht) hilft bei der Synchronisation technischer Metadaten. Diese können mit schematisierten Tags für Metadaten im Unternehmenskontext, wie PII und DSGVO, erweitert werden. Unser Ziel ist ein vollständig verwalteter Service mit Sicherheits- und Governance-Integration und einer einfach zu navigierenden Benutzeroberfläche, die Such- und Entdeckungsfunktionen für eine einheitliche Datenansicht bietet, egal wo sie sich befinden (einschließlich Unterstützung für On-Premise-Datensätze).
Nichtsdestotrotz ist es nur eine Frage der Zeit, bis in unserer Plattform etwas schiefgeht – eine harte Realität für Kunden von Cloud-Diensten. Trotz der SLAs, die für jeden Dienst bereitgestellt werden, könnte der Dienst vorübergehend nicht verfügbar sein – was unsere End-to-End-Datenverarbeitungspipeline unterbricht und Probleme in den nachgelagerten Bereichen verursacht. Aus diesem Grund verwenden wir, wie bei unserem On-Premise-System, Monitoring-Tools, um die Leistung, die Betriebszeit und den allgemeinen Zustand der Plattform zu überwachen. Durch das Sammeln von Kennzahlen, Ereignissen, Uptime Probes, Anwendungsinstrumentierung usw. können wir über Dashboards Einblicke generieren – wie beispielsweise durch Mustererkennung oder Fehlervorhersage – und bei Bedarf Abweichungen durch Benachrichtigungen melden. Im nächsten Schritt generieren Cloud-Dienste eine Vielzahl von Logfiles – plattformspezifische und (von unseren Anwendungen generierte) User Logfiles sowie Security Logs (ein Audit-Trail von administrativen Änderungen und Datenzugriffen). Für die Protokollierung wünschen wir uns Funktionen wie Logfile-Archivierung, -Beibehaltung und -Alarmierung, logfile-basierte Kennzahlen, benutzerdefinierte Logs, erweiterte Analysefunktionen für generierte Logfiles und die Integration von Drittanbietern (Exporte an SIEM-Tools).
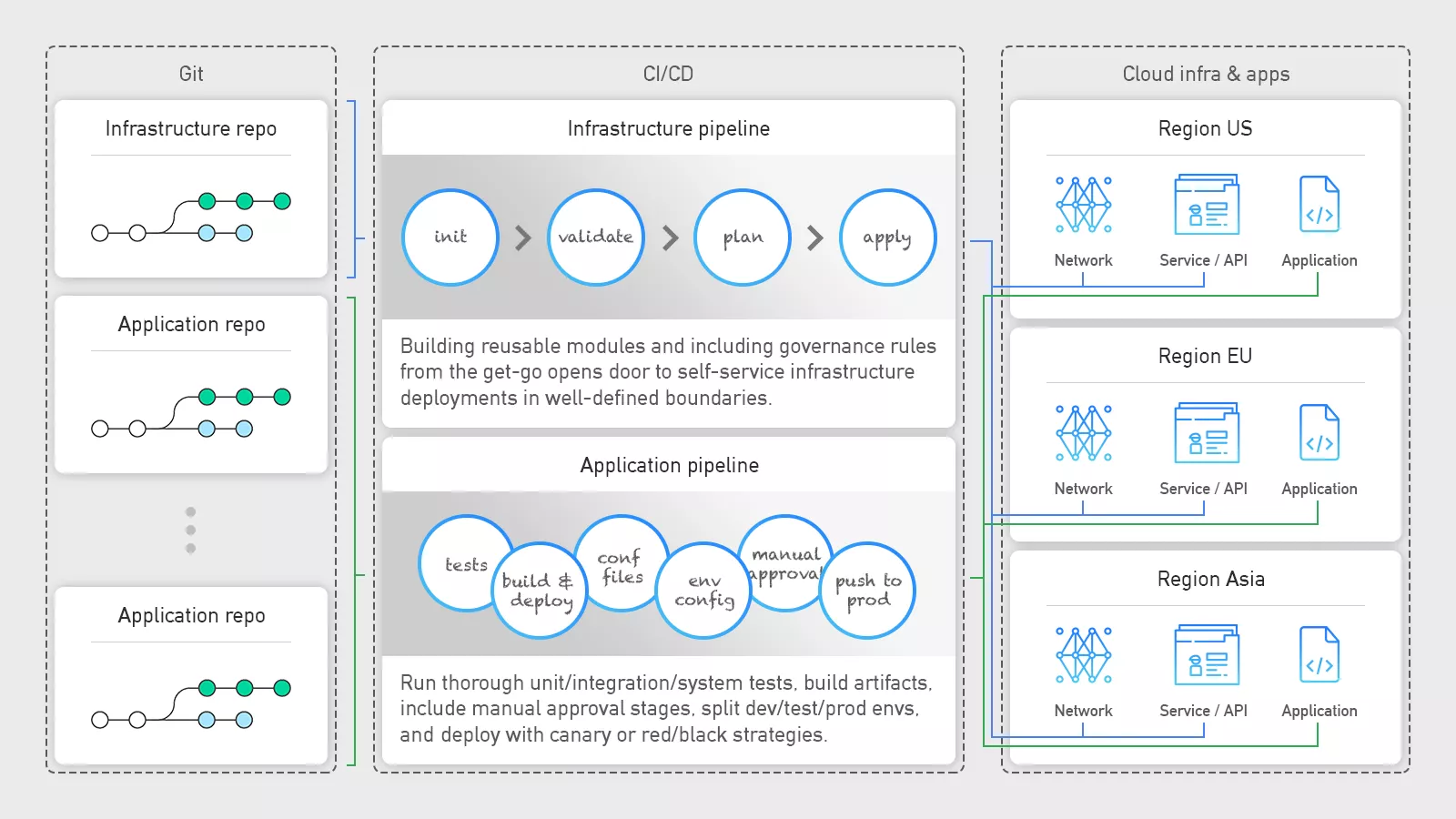
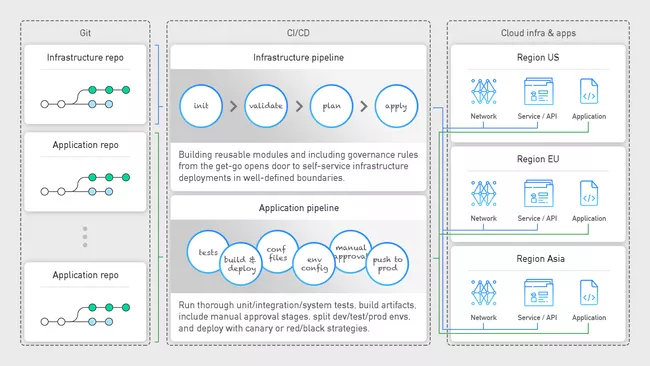
Lass uns an dieser Stelle kurz einen Blick zurück werfen. Angenommen, Dein Unternehmen hat sich nach reiflicher Überlegung für die Migration in die Cloud entschieden. Sobald Dir der Zugang gewährt wird, meldest Du Dich in der Konsole an und beginnst voller Begeisterung, verschiedene Dienste zu nutzen. Hebt jemand die rote Fahne? Das Schlüsselwort hier ist Automatisierung, von Deiner Infrastruktur bis zu Deinen Anwendungen. Unabhängig davon, ob Du die Infrastruktur für das gesamte Unternehmen oder nur für Deine Abteilung verwaltest, solltest Du Konsistenz und Wiederholbarkeit anstreben. Nur dann kannst Du sicher sein, dass Deine DEV- und PROD-Umgebungen konsistent sind und dass alle Bugs oder Fixes schnell und konsistent über die Umgebungen verteilt werden können. Mit CI/CD, also Continuous Integration und Continuous Deployment, können wir den gesamten Prozess automatisieren. Der CI-Teil kümmert sich um die Build- und Test-Phasen Deiner Infrastruktur/Applikation (Ausführen von Modul-/Integrations-/Systemtests, Erstellen eines Docker-Images und Speichern des Images in einer Artefakt-Registry). Der CD-Teil ist für die Bereitstellung der Infrastrukturressourcen/Artefakte an die Zieldienste zuständig (Bereitstellung des Docker-Images an den Kubernetes-Cluster). Durch die Integration dieses Prozesses mit Deiner Versionskontrolle (GitHub oder GitLab) können sich die Entwickler:innen auf die Implementierung konzentrieren, denn sie wissen, dass durch das Pushen eines Git-Commits automatisch eine CI-/CD-Pipeline gestartet und die Anwendung deployt wird – eine Praxis, die als GitOps bekannt ist.
Nachdem wir nun die einzelnen Bausteine der Referenzarchitektur auf High-Level-Ebene besprochen haben, wird sich unser nächster Beitrag dieser Serie mit der Implementierung auf einer Google Cloud Platform beschäftigen. Bleib dran und – wenn Du auf keinen Fall etwas verpassen willst – denk daran, Dich für unseren Newsletter anzumelden!