







The new SaaS solution from Microsoft has the potential to change the world of data. But should you migrate now? If so, what is the best approach? A lakehouse or warehouse? And what must you consider with OneLake? Where are the current hurdles? And what about Azure Synapse?
We’ll address all these aspects in this article.
First, there’s a key message for all Azure Synapse customers: Synapse will continue to be fully supported and is not being discontinued. Microsoft has no plans to do so! But we’ll tell you where it still makes sense to look ahead.
Microsoft OneLake
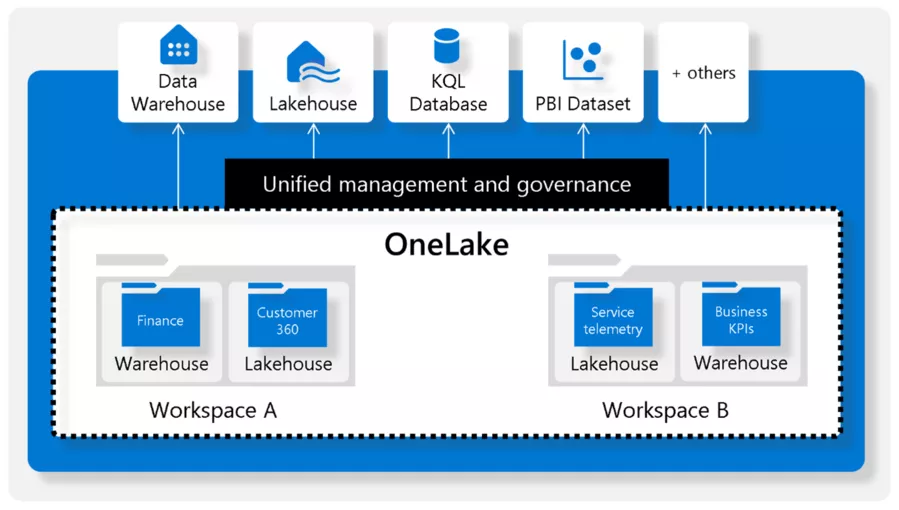
When integrating and processing data, copying and replication processes require a considerable effort that means higher costs and longer processing times. In addition, you often end up with different versions of the same data, reflecting different truths in a sense.
Microsoft OneLake aims to provide data in one version only and to avoid copying operations wherever possible. To achieve this, OneLake serves as the storage space for various services and tools via a unified interface.
For more details about OneLake, click here.
Fabric Lakehouse and Warehouse
When migrating data warehouses, Microsoft offers two services in Fabric with different application possibilities:
- The Lakehouse: this is the central data storage location in Fabric. Data can be stored in a data lake in any file format, for further processing. Data in the Delta Lake format appear as tables and are easily processed using various query languages and tools. Shortcuts enable reading of external data sources (such as Azure Data Lake Storage Gen2, Amazon S3, or other data in OneLake) in this table format, without having to copy the data into the lakehouse. The integration of lakehouse artifacts in GIT is also possible now!
- The Warehouse: while the lakehouse offers a SQL interface, it is readonly (comparable to Synapse SQL Serverless). The Fabric warehouse, on the other hand, is a full-fledged data warehouse (read & write). Schemas, tables, and stored procedures can be created and used, and it was just announced that deployment of the DDL definition is supported by SQLPackage – an important step towards automation! Using OneLake, all Delta Lake objects from the lakehouse can be queried directly in the warehouse, which in turn allows direct access to external data sources via shortcuts. This technology now makes it feasible to also support decentralized domain concepts.
So, the question is: what could individual scenarios look like to accomplish new workloads like data science / AI or IoT in Fabric?
Case 1: The Modern Data Estate
If you are already in the fortunate position of having created a lakehouse using Azure Databricks or Synapse Spark, then you have the perfect basis. With the concept of shortcuts (for those of you familiar with SQL: comparable to a linked service), the existing Delta Lake can be used directly and without detours. There is a possibility to make the data directly available to the many compute engines in Fabric (data science / IoT / Power BI, etc.), without having to copy the data (important: you must be dealing with a Delta Lake, otherwise you have to convert the files first).
This provides an immediate benefit: Power BI can work with these data in Direct Lake mode. This means that Power BI can access the Delta files directly without having to import the data via a semantic model (formerly: dataset). Hence: you get the performance of the import mode combined with the freshness of DirectQuery... and save the scheduling time for the semantic model, a.k.a. dataset.
Building on this shortcut concept, it now becomes possible to migrate the dedicated SQL pools and use them as either a lakehouse or warehouse in Fabric. Likely steps:
- Export the dedicated SQL pools into a SQL project and import this project into Fabric.
- Meanwhile, PowerShell scripts on GitHub now support the conversion from SQL dedicated pool DDLs to Fabric DDLs.
A migration assistant announced for 2024 will even be capable of automatically redirecting endpoints.
Later on, we will talk about the tool to possibly support this.
What about Azure Data Factory? Now that Microsoft Fabric is generally available, Fabric pipelines are also available, and most activities around orchestration are fully supported. Since ADF can also write directly to OneLake, the migration effort is markedly reduced.
However, at present there are still no mapping data flows from ADF in Microsoft Fabric. This means that existing data flows must either be replaced by Dataflows Gen2 in Fabric (guide: https://aka.ms/datafactoryfabric/docs/guideformappingdataflowusers), or the mapping data flow code must be converted to Spark code. Here too the Fabric Customer Advisory Team (Fabric CAT) has provided tools: https://github.com/sethiaarun/mapping-data-flow-to-spark.
Since VNet Data Gateways will also be supported now for Dataflows Gen2, integration into existing network infrastructures now works!
Another aspect that has also been announced is that in the second half of 2024, it will be possible to mount an existing Azure Data Factory in Fabric. But we already know this principle from previous SSIS workloads.
Case 2: Migration of an SQL Managed Instance
The issue that arises is how to migrate, for example, our DWH processes in a SQL Server Managed Instance to Fabric?
With the support of SQLPackage deployments, all objects already defined in this way can now be migrated easily to Fabric. But what method requires the least effort to initially load the data into Fabric?

We tried this out using the AdventureWorks 2022 sample database:
- First, create a lakehouse and a warehouse in Fabric and link the lakehouse as an external data source in SQLMI. Then, export the existing tables as Parquet files (see Jovan Popovic's blog).
- Using a Spark notebook, convert these files into the Delta format, so they can be provided as lakehouse objects.
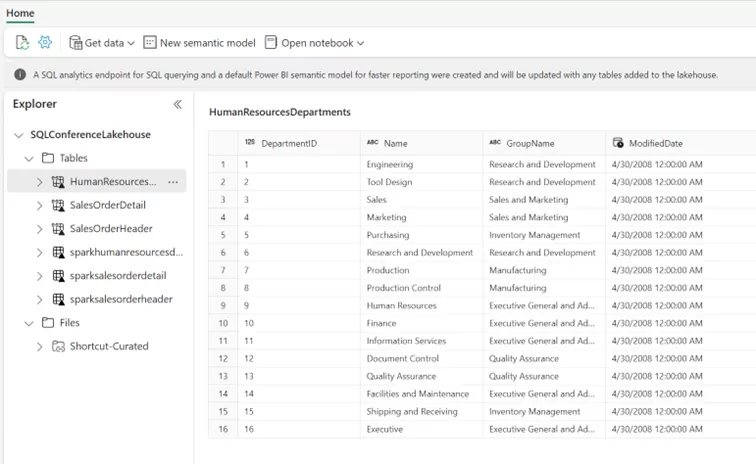
Use these tables directly in the warehouse or process them further (e.g., as staging tables). You may need to adjust procedures to correctly reference the lakehouse (similar to a cross-database query on a SQL Server).
- Below is an example procedure to write data to the Departments table.
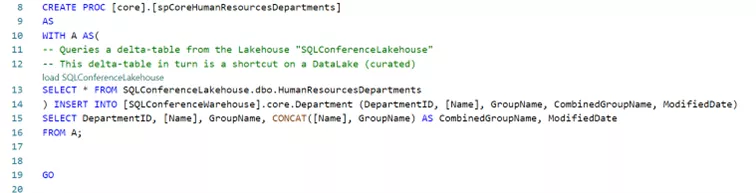
These new tables can be reused via standard SQL interfaces or applied directly in Power BI. Also new: Fabric Warehouses now support the Power BI Direct Lake mode, and thereby lower the complexity of future solutions.
Two additional techniques/tools are now available on the path to migration:
dbt-Fabric
dbt is now widely used in many data warehouse scenarios to define and test data integrations, and to execute them without stored procedures.
While existing SQL solutions typically rely on community connectors, Microsoft has developed a direct connector in Fabric for dbt. Developers aim to support all artifacts that Fabric Warehouse supports in the dbt connector. If a dbt project already has an existing warehouse (e.g., Microsoft SQL Server / Snowflake or Amazon RedShift), it can easily be migrated to Fabric. Here, it is always important to ensure that any database-specific SQL dialects are cleaned up in advance. For example, sp_rename has only just been supported in Fabric Warehouse.

Click Microsoft for documentation with some examples.
Deployment example:
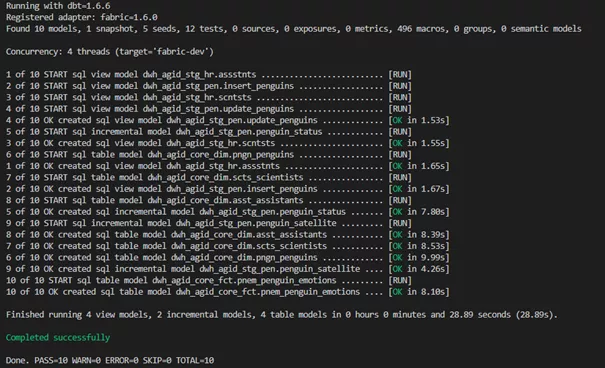
The outcome in Microsoft Fabric:
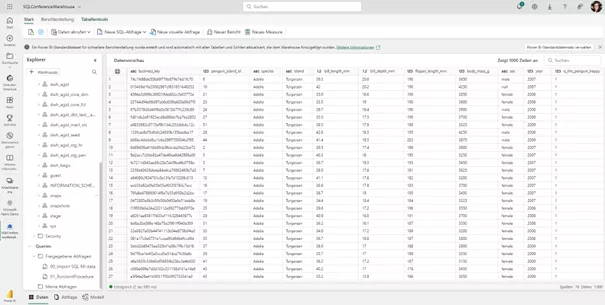
Mirroring
New feature in Microsoft Fabric: Mirroring – but what exactly is that?
Microsoft Fabric's Mirroring refers to real-time data replication using Change Data Capture (CDC) in OneLake. This enables additional applications and provides access to data from operational systems. The mirrored data can be queried from all endpoints. This means that you can immediately access the data using T-SQL queries and join these via shortcuts with data from the existing warehouse.
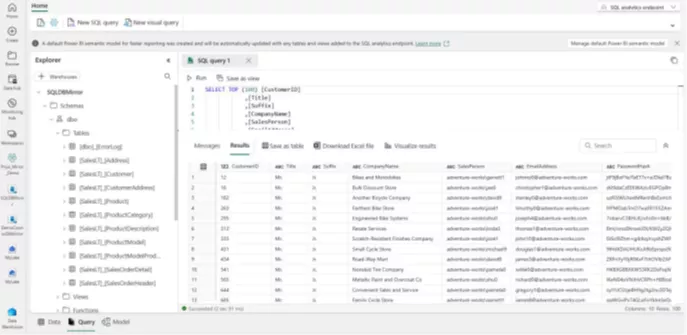
Mirroring is currently available for Azure Cosmos DB, Azure SQL DB, and Snowflake. This feature is particularly exciting for Snowflake users, as mirroring databases can significantly reduce the workload and costs on a Snowflake database, while enabling ad-hoc reporting through Power BI's Direct Lake Mode via the mirror. Thus, end-users can simply switch their connection and immediately have options to provide data to a much wider range of user groups – without having to tackle the underlying technology.
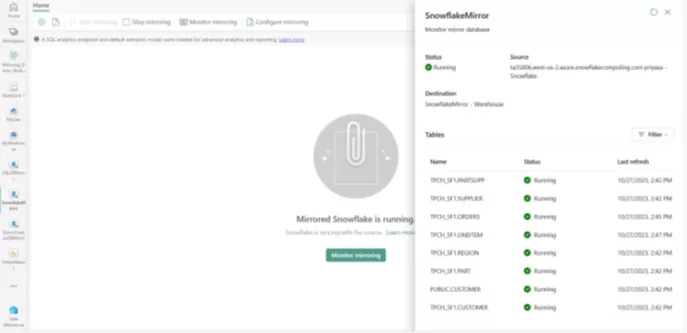
As described above, the next step could be the actual migration using dbt.
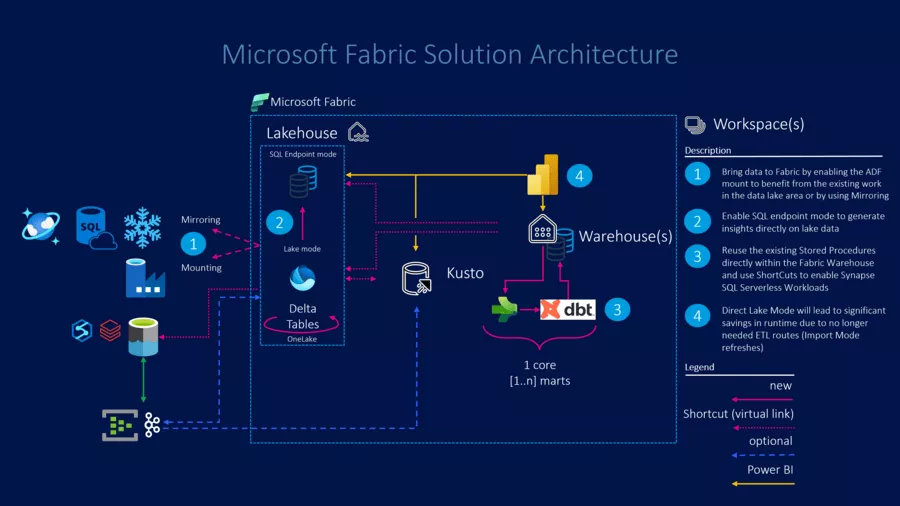
Finally, here is a sketch of a possible architecture solution with all the paths just described:
Did we perk your interest? Or perhaps miss something? Don’t hesitate to get in touch with any of our Azure experts for an initial consultation. We’d be happy to guide you through Microsoft Fabric!

