





Before HANA, exception aggregations in SAP BW more frequently posed a challenge at runtime, this also applying to the distinct count operation. This operation is used, for example, to obtain a customer count from orders.
Earlier, distinct count operations were often implemented as follows: A calculated key figure with a value of 1 was established, and additions then performed via exception aggregation. However, what worked well in environments without HANA currently causes the pushdown to stop functioning. This can prevent calculations from being optimally performed, depending on settings.
A solution is therefore required for HANA environments: Accordingly, let us concentrate next on optimal implementation of distinct count with business warehouse on HANA or BW/4HANA.
Settings in the query
The function is already integrated as exception aggregation in SAP BW, and can be enabled directly for key figures or queries involving previously calculated key figures. This ensures selection of the optimal execution plan. Because we want to count occurrences in data pertaining to an InfoObject (for example, our customers in orders), the InfoObject to be counted must be selected. The procedure in BW-MT is as follows:7
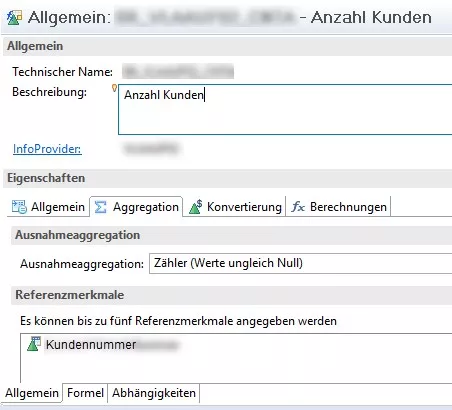
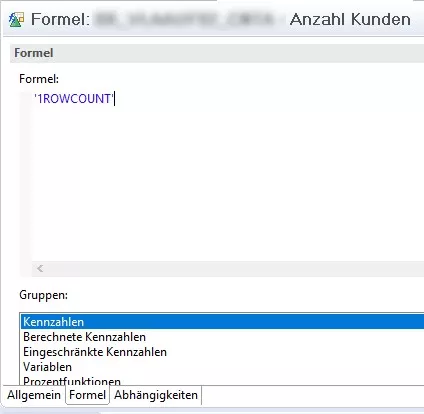
The execution plan
For optimal execution of distinct count, the data model must be prepared in the next step in order to prevent unnecessary operations involving the database. This is of relevance in ensuring optimum utilization of database features, especially in the case of storage inside in-memory databases using column store. It applies across database types to products from a variety of manufacturers, and reflects systemic behaviour.
Without optimization of the data model, the following objects are needed by the business warehouse to determine customers, and must be considered in the execution plan:
- SID of the InfoObject to be counted
- ADSO with facts
Problem: SIDs of InfoObjects
Because an ADSO contains no SID, a join must be performed on the InfoObject's SID table during execution. This costs a lot of resources, because the column store cannot be fully utilized (column vs. join operation), and increases the runtime in the case of large quantities of master data. This can be neglected if there are only a few characteristics.
To avoid this join operation, ADSO offers a setting for checking master data during loading / activation and SID storage, when an InfoObject is selected in the ADSO dialog (see screenshot below). During activation of the ADSO, the SID value is thus also stored in a separate column, in addition to the characteristic. This eliminates the need for a join operation, and the distinct count operation can be executed directly on the active table of the ADSO.
In newer Support Packages, this optimization can also be performed using remodeling and the ADSO does not have to be emptied beforehand. In earlier versions, a solution to the content may be necessary. The data operation necessitated by subsequent readout of the SID would also be possible without data deletion. Because the SID columns generally occupy more memory, this setting should not be used universally for all objects, but be applied after careful consideration. Refer to the webinar: Best Practice – Implementation of SAP BW on HANA).

Problem: Materialization with union operations
Similar to the SID problem, data models/queries across objects can also pose performance problems. This is because the database, in the case of a union for tables (for example, when using a composite provider with multiple objects) must deal with them individually. In the PlanWiz execution plan, this is made evident, for example, by the creation of a temporary table. This places higher demands on the main memory, and also increases the runtime during execution.
Treatment of causes
The "problems" lead to the following execution steps, which would be necessary as well as in other databases:
- Join of the SIDs
- GROUP BY from all SIDs of sub-objects, and storage in a temporary table
- Distinct count on the temporary table
Solution Step 1:
We can simply avoid this by incorporating the SID in the ADSO.
Solution Steps 2 and 3:
The data model must be adapted due to the frequent user queries. For example, if the analytic engine recognizes that an ADSO is not necessary for results, it is not read (pruning). By ensuring that only a single ADSO is used for result determination, we thus optimize the runtime. This be achieved easily with semantic groups in BW/4HANA. The analytical engine needs to know beforehand what an ADSO contains, in order to exclude it. Without this information, it needs to check the content and uses a temporary table. In an example involving a similar problem in practice, a query's overhead comprising 20 GB over a runtime of 30 s could be reduced to 200 MB over 1 s, because only small data quantities needed to be cached by the database.

Design follows function
Optimization of the data model always depends on user queries. Needed therefore are regular reviews of whether the requirements concerning the current analytics processes are still being met. A consideration of this aspect allows the HANA database's performance to fully unfold in conjunction with a BW, and thus satisfy users.