







Vor kurzem haben wir bereits gezeigt, wie Du Maschinendaten mit einem Edge Device auslesen und diese anschließend in Azure visualisieren und zur weiteren Verarbeitung vorbereiten kannst. Dieser Beitrag behandelt nun dieselbe Frage – nur in AWS.
Setup und Vorbereitung
Die Architektur für den folgenden Use Case besteht aus zwei EC2-Instanzen, zwei Lambda-Funktionen, einer DynamoDB (Datenbank) sowie dem Service Quicksight. Folgendes Bild beschreibt die Infrastruktur in AWS.
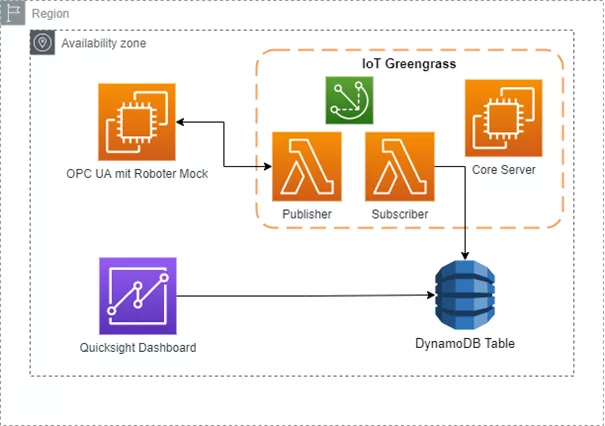
Die erste EC2-Instanz wird zur Simulation des Industrieroboters verwendet. Die Simulation wurde anhand eines Python-Moduls umgesetzt und schreibt regelmäßig Daten in einen OPC UA Server. Auf der zweiten EC2-Instanz ist die AWS IoT Greengrass Software installiert. Diese dient zum Lesen der OPC-UA-Daten und bildet die Integration zur AWS Cloud. Die Software verbindet sich bei Bedarf (entweder bei Trigger oder permanent nach Intervallen) mit dem OPC UA Server, holt die Daten ab und publisht diese in ein gewisses Topic. Eine weitere Funktion wird durch das Topic getriggert und speichert die Daten in einer Datenbank. Die Funktionen werden mittels AWS Lambda initialisiert. AWS Lambda ist eine serverlose Plattform, auf der in unserem Szenario Python-Skripte definiert werden, die anschließend auf der EC2-Instanz bzw. auf dem Edge mittels AWS IoT Greengrass ausgeführt werden. Dieser Service ist das Kernelement dieses Blogbeitrags. Durch die AWS IoT Greengrass Software können verbundene Devices sowohl Lambda-Funktionen als auch Docker-Container ausführen. Dies ermöglicht es Geräten, Daten näher an der Informationsquelle zu erfassen und zu analysieren, selbstständig auf lokale Ereignisse zu reagieren und in lokalen Netzwerken sicher untereinander zu kommunizieren. Durch die Core-Software wird z. B. das MQTT-Messaging zwischen AWS-IoT-Funktionen, Geräten und lokalen Netzwerken ermöglicht. Ebenso ist es mit Lambda-Funktionen möglich, OPC UA Server auszulesen. Die Datenbank wird mittels AWS DynamoDB aufgesetzt. AWS DynamoDB ist eine serverlose skalierbare Datenbank (NoSQL). Auf dieser werden alle Daten für die abschließende Visualisierung gespeichert. DynamoDB ist für diesen Use Case gut geeignet, da die Latenz sehr gering ist. Somit ist die Datenbank für echtzeitnahe Abfragen bzw. für Use Cases im Bereich IoT und Industrie 4.0 geeignet.
Datenverarbeitung und Logik in AWS IoT Greengrass
In unserem Use Case werden in AWS IoT Greengrass zwei Lambda-Funktionen verwendet. Beide Lambdas sind in Python geschrieben und werden lokal programmiert. Damit die Funktionen AWS Greengrass IoT nutzen können, muss das AWS IoT Device SDK für Python heruntergeladen werden. Die Daten vom Server werden im 5-Sekunden-Takt abgeholt und in das Topic „iot/tribe“ gepublisht. Im folgenden Snippet ist die Lambda kurz dargestellt, die eine Verbindung zu dem OPC UA Server herstellt, die Nodes abfragt und diese anschließend zu AWS publisht.
client = greengrasssdk.client('iot-data')
opcuaClient = Client('opc.tcp://0.0.0.0:4840')
values = {
'disturbance - S1': opcuaClient.get_node('ns=2;i=6').get_value(),
'disturbance - S2': opcuaClient.get_node('ns=2;i=7').get_value(),
}
client.publish(
topic='iot/tribe',
queueFullPolicy="AllOrException",
payload=json.dumps(values)
)
Die zweite Lambda initialisiert eine Verbindung zur Datenbank DynamoDB und schreibt bei Trigger die Values in die Datenbank:
dynamodb = boto3.client('dynamodb')
dynamodb.put_item(TableName='greengrass_iot', Item=values)
Damit die Lambdas in AWS IoT Greengrass nutzbar werden, werden diese jeweils gezippt und in AWS Lambda mit allen Abhängigkeiten und Bibliotheken hochgeladen. Anschließend sind diese in AWS IoT Greengrass integrier- und nutzbar.
In AWS IoT Greengrass wird eine Gruppe erstellt. In dieser können benötigte Lambda-Funktionen hinzugefügt und anschließend auf dem Device oder auf dem Core verwendet werden. Die oben genannten Funktionen werden ebenfalls hinzugefügt. Die Funktion für den OPC UA Server ist langlebig und läuft permanent. Die zweite Funktion ist eine „On-demand“-Funktion und wird nur verwendet, wenn etwas in das Topic „iot/topic“ gepublisht wird. Ebenso müssen unter dem Reiter Subscriptions jegliche Verbindungen (Source – Target) definiert werden. In unserem Beispiel sind dies zwei Subscriptions:
- Source: opc_lambda, Target: IoT Cloud, Topic: iot/tribe
- Source: IoT Cloud, Target: dynamo_lambda, Topic: iot/tribe
Folgendes Bild beschreibt den zusammenhängenden Prozess:

Abschließend wird die IoT-Gruppe deployt und ist live. Bei Interesse können auch noch verschiedene Loglevel sowohl für den Core als auch für die Lambdas definiert werden.
Visualisierung der Daten mittels AWS Quicksight
Abschließend können die Daten mittels Quicksight visualisiert werden. Folgendes Bild zeigt ein Beispiel für die Visualisierung über zwei Stunden:

Zusammenfassung
AWS bietet zahlreiche Services an, um leicht, effizient und ohne Hindernisse in die Welt des Internet of Things einzusteigen. Somit sind wir in kürzester Zeit in der Lage, verschiedene Devices auszulesen, diese in die Cloud zu migrieren und für Analysezwecke zu visualisieren. Durch die Publish/Subscriber-Methode ist es möglich, verschiedene Workflows und Prozesse asynchron und zuverlässig zu handhaben.
Du hast Lust und Motivation, Deine IoT-Daten in AWS zu integrieren und in die Welt der Cloud einzusteigen? Gerne unterstützen wir Dich bei der Umsetzung des gesamten Prozesses.